Waarom zijn reproduceerbaarheid en repliceerbaarheid belangrijk?
Waarom zijn reproduceerbaarheid en repliceerbaarheid belangrijk?
Een succesvolle reproductie laat zien dat data-analyses correct en eerlijk zijn uitgevoerd en met een geslaagde replicatie wordt de betrouwbaarheid van het onderzoek verhoogd.
Onderzoekers kiezen vaak voor een vorm van blindering, waardoor participanten, onderzoekers en/of data-analisten niet weten of participanten in de experimentele of controlegroep zijn ingedeeld.
Hierdoor kunnen de geblindeerde partijen de resultaten niet (on)bewust beïnvloeden, waardoor de interne validiteit van een experiment wordt verhoogd.
Bij blindering in onderzoek weten een of meerdere partijen niet of de participanten zijn ingedeeld in de controlegroep of de experimentele groep. Er zijn drie soorten blindering:
Enkelblind onderzoek: participanten weten niet in welke groep ze zijn ingedeeld.
Dubbelblind onderzoek: participanten en onderzoekers weten niet in welke groep de participanten zijn ingedeeld.
Driedubbelblind onderzoek: participanten, onderzoekers en data-analisten weten niet in welke groep de participanten zijn ingedeeld.
Bij cohortonderzoek observeert de onderzoeker proefpersonen die al een bestaand, gemeenschappelijk kenmerk hebben (zoals “roken”). Er wordt geen manipulatie uitgevoerd en er wordt niet gecontroleerd voor externe variabelen.
Cohortonderzoek kan prospectief of retrospectief zijn, maar experimenteel onderzoek is altijd prospectief.
Een case-control study legt net als een retrospectief cohortonderzoek de nadruk op het verleden, en er wordt geredeneerd vanuit de uitkomst naar de oorzaak. Het doel van een case-control study is om de risicofactoren van bijvoorbeeld een ziekte te achterhalen. Hiertoe worden twee groepen onderzocht:
een groep personen van wie bekend is dat zij een bepaalde uitkomst “bezitten” (e.g., een ziekte)
Bij een cohortonderzoek wordt geen gebruik gemaakt van twee groepen, maar slechts van één groep (cohort). De proefpersonen worden herhaaldelijk gemeten voor langere tijd om correlaties vast te stellen. Ook kan een cohortonderzoek zowel retrospectief (gericht op verleden) als prospectief (gericht op toekomst) zijn.
Een cohort is een groep mensen uit de samenleving die een gemeenschappelijk kenmerk bezitten (e.g., rokers, de populatie van Amsterdam of iedereen die is geboren in 1998).
Bij een cohortonderzoek wordt een cohort herhaaldelijk gemeten over een langere periode.
Over het algemeen doorloop je voor een peer review de volgende stappen:
Eerst legt de auteur het manuscript voor aan de redacteur.
De redacteur kiest ervoor om:
Het manuscript af te wijzen en terug te sturen naar de auteur
Het manuscript door te sturen naar de geselecteerde peer reviewer(s).
De peer reviewer geeft feedback op het manuscript.
Ten slotte wordt het bewerkte manuscript teruggestuurd naar de auteur, waarna wijzigingen worden verwerkt en het manuscript wordt ingediend voor publicatie.
Peer reviews kunnen voorkomen dat duidelijk problematisch, gefraudeerd of anderszins onbetrouwbaar onderzoek wordt gepubliceerd. Daarnaast is het een uitstekende kans om feedback te krijgen van gerenommeerde experts in je vakgebied. Ook werkt peer review als een eerste verdediging die hiaten, vage termen en onbeantwoorde vragen voor lezers kan identificeren.
Veel vakgebieden maken gebruik van een peer review, vooral om te bepalen of een manuscript klaar is voor publicatie. Peer review verhoogt de geloofwaardigheid van het manuscript. Hierdoor behoren wetenschappelijke tijdschriften tot de meest betrouwbare bronnen waarnaar je kunt verwijzen in je bronvermelding.
Peer review is echter ook gebruikelijk in niet-academische settings, zoals voor medisch onderwijs of de gezondheidszorg. Daarnaast worden peer assessments ingezet als pedagogisch hulpmiddel in basis-, middelbaar en hoger onderwijs.
Als je een meetinstrument ontwikkelt of evalueert, helpt constructvaliditeit om te bepalen of je daadwerkelijk het construct meet dat je wilt meten. Zonder constructvaliditeit loop je het risico dat je per ongeluk ongerelateerde constructen meet.
Statistische analyses worden vaak uitgevoerd om de validiteit te bepalen op basis van de verzamelde data van je metingen. Je onderzoekt de convergente en discriminante validiteit door te bepalen of je meetresultaten positief of negatief correleren met andere bestaande metingen.
Daarnaast kun je ook een regressieanalyse uitvoeren om te beoordelen of je meetinstrument daadwerkelijk de uitkomsten voorspelt die je verwacht had. Als je regressieanalyse overeenkomt met je verwachtingen, versterkt dit je claim van constructvaliditeit.
Constructvaliditeit (ook wel begripsvaliditeit genoemd) geeft aan in welke mate je onderzoeksinstrument het concept meet dat het moet meten (en niet per ongeluk een ander concept).
Inhoudsvaliditeit (content validity) is de mate waarin de aspecten van het te meten begrip volledig worden gemeten met je onderzoeksinstrument. Hierbij gaat het erom in hoeverre alle aspecten van het begrip “gedekt” worden.
Constructvaliditeit is dus een overkoepelende soort validiteit die betrekking heeft op het construct zelf in relatie tot andere constructen, terwijl inhoudsvaliditeit inzoomt op de te meten aspecten van het construct.
Controleren van externe variabelen door onder andere (1) een representatieve steekproef uit de populatie te trekken, (2) je dataverzamelingsprocedure te standaardiseren, en (3) externe variabelen van proefpersonen (e.g., leeftijd, gender, inkomen) te meten.
Gebruikmaken van minstens één controlegroep die wordt onderzocht naast de experimentele groep waarin een vergelijkbare conditie, placebo of geen conditie wordt aangeboden.
Willekeurig verdelen van de proefpersonen over de verschillende groepen van het experiment om te zorgen voor een valide vergelijking (randomisatie).
Een experimentele groep, ook wel de behandelingsgroep genoemd, krijgt het experiment of de behandeling waarvan de onderzoekers het effect willen bestuderen.
Een controlegroep krijgt in plaats hiervan een vergelijkbare conditie, placeboconditie of geen conditie aangeboden.
In alle andere opzichten moeten beide groepen identiek zijn.
In een gerandomiseerd onderzoek met controlegroep (randomized controlled trial, RCT) wordt gebruikgemaakt van deze twee groepen om de resultaten te vergelijken en zo de validiteit van het experiment te waarborgen.
Een controlled clinical trial (CCT) is in principe hetzelfde als een randomized controlled trial, alleen heeft er bij deze experimenten enkel quasi-randomisatie of helemaal geen randomisatie plaatsgevonden.
Als het niet bekend is of de participanten zijn gerandomiseerd, of als de methode voor randomisatie niet volledig is, wordt een onderzoek meestal bestempeld als een controlled clinical trial.
Indruksvaliditeit (face validity) geeft aan in welke mate een meetinstrument op het eerste gezicht relevant en geschikt lijkt om te meten wat het moet meten.
Indruksvaliditeit (face validity)is belangrijk, omdat het een eerste beoordeling is van de validiteit van je meetinstrument. Het is een snelle en gemakkelijkke manier om na te gaan of een meetinstrument op het eerste gezicht nuttig is.
Bij een hoge indruksvaliditeit geven mensen aan dat je meetinstrument volgens hen lijkt te meten wat het moet meten.
Bij een lage indruksvaliditeit kan er verwarring zijn over de meting zelf of over waarom deze methode wordt toegepast.
Voor indruksvaliditeit (face validity) is het in de meeste gevallen het beste om verschillende mensen te vragen je meetinstrument te beoordelen. Deskundigen hebben weer hele andere kennis en kijken naar hele andere dingen dan potentiële proefpersonen. Beide groepen kunnen waardevolle inzichten leveren voor de beoordeling van je meetinstrument.
Het Rosenthal-effect verwijst naar situaties waarin hoge verwachtingen tot betere prestaties leiden, terwijl lage verwachtingen tot slechtere prestaties leiden.
Een andere naam voor het Rosenthal-effect is het Pygmalion-effect.
Het waarnemer-verwachtingseffect (observer-expectancy effect) is een vorm van onderzoeksbias die optreedt als onderzoekers de resultaten van hun eigen onderzoek beïnvloeden via interactie met deelnemers aan het onderzoek.
De eigen overtuigingen en verwachtingen van onderzoekers over de resultaten kunnen onbedoeld deelnemers beïnvloeden via demand characteristics (vraagkenmerken).
Het observer-expectancy effect wordt vaak gebruikt als synoniem voor het Rosenthal-effect of Pygmalion-effect.
De determinatiecoëfficiënt (R²) is een getal tussen de 0 en 1 dat de mate aanduidt waarin een statistisch model in staat is een bepaalde uitkomst te voorspellen. Je kunt de R² interpreteren als de proportie (het deel) van de variantie in de afhankelijke variabele die wordt voorspeld door het statistisch model.
Je kunt de samenvattingsfunctie() (ook wel summary () function) gebruiken om R² (coefficient of determination) van een lineair model weer te geven in R. Onderaan de output zie je “R-kwadraat” (“R-squared”) staan.
Elke normale verdeling kan worden omgezet in de standaardnormale verdeling door de individuele waarden om te zetten in z-waarden (z-scores). In een z-verdeling geven z-scores aan hoeveel standaarddeviaties elke waarde van het gemiddelde afligt.
De z-waarde en t-waarde (ook wel z-score en t-score) geven aan hoeveel standaarddeviaties je van het gemiddelde van de verdeling verwijderd bent, mits je data een z-verdeling of een t-verdeling volgen.
Als uit je test een z-score van 2.5 naar voren komt, betekent dit dat je schatting 2.5 standaarddeviaties van het gemiddelde afwijkt.
Het voorspelde gemiddelde en de voorspelde verdeling van je schatting worden bepaald door de nulhypothese van de statistische test die je uitvoert. Hoe meer standaarddeviaties van het gemiddelde je schatting afwijkt, hoe kleiner de kans dat je schatting daadwerkelijk onder je nulhypothese heeft kunnen plaatsvinden.
Het betrouwbaarheidsintervalbestaat uit de boven- en ondergrens van de schatting die je verwacht te vinden bij een gegeven betrouwbaarheidsniveau.
Het betrouwbaarheidsniveau (confidence level) is het percentage van de keren dat je verwacht in de buurt van dezelfde schatting te komen als je je experiment nog een keer uitvoert of opnieuw op dezelfde manier een steekproef uit de populatie haalt.
VoorbeeldJe wilt weten wat het gemiddelde aandeel is van het aantal meisjes dat elk jaar geboren wordt. Hiertoe gebruik je een willekeurige steekproef van baby’s. Met een 95%-betrouwbaarheidsinterval vind je een bovengrens van 0.56 en een ondergrens van 0.48. Het betrouwbaarheidsniveau is 95%.
Een kritieke waarde is een waarde van de teststatistiek die de boven- en ondergrens van het betrouwbaarheidsinterval definieert, of de drempelwaarde van statistische significantie in een statistische test. Het beschrijft hoe ver je van het gemiddelde van de verdeling af moet liggen om een bepaalde hoeveelheid van de totale variatie in de data te dekken (i.e., 90%, 95%, 99%).
Als je zowel een 95%-betrouwbaarheidsinterval als een drempelwaarde van statistische significantie van p = 0.05 aanhoudt, dan zullen je kritieke waarden in beide gevallen identiek zijn.
Als je betrouwbaarheidsintervalvoor het verschil tussen groepen een nul bevat, betekent dit dat er een grote kans bestaat dat je geen verschil vindt tussen de groepen als je het experiment nog een keer uitvoert.
Als je betrouwbaarheidsinterval voor een correlatie of regressie nul bevat, betekent dit dat er een grote kans bestaat dat je geen correlatie vindt in je data als je het experiment nog een keert uitvoert.
In beide gevallen zul je ook een hoge p-waarde vinden bij je statistische test. Dit houdt in dat je resultaten zouden kunnen voorkomen onder de nulhypothese. Dit zou betekenen dat de resultaten geen relatie tussen de variabelen ondersteunen.
Als je al deze dingen weet, kun je het betrouwbaarheidsinterval voor je schatting berekenen door ze in de formule voor het betrouwbaarheidsinterval te zetten die overeenkomt met je data. Wat de formule precies is hangt af van het type schatting (e.g., een gemiddelde of een proportie) en van de verdeling van je data.
Rechtsscheef (right skew). Een rechtsscheve verdeling (ook wel positief-scheve verdeling genoemd) is langer aan de rechterkant van de piek dan aan de linkerkant.
Linksscheef (left skew). Een linksscheve verdeling (ook wel negatief-scheve verdeling genoemd) is langer aan de linkerkant van de piek dan aan de rechterkant.
Zero skew. Een verdeling met zero skew (nul scheefheid) is symmetrisch, wat inhoudt dat de linker- en rechterkant spiegelbeelden van elkaar zijn.
Zowel de chi-kwadraattoets en een t-toets kunnen worden gebruikt om het verschil tussen twee groepen te onderzoeken.
Echter, een t-toets wordt gebruikt als je een kwantitatieve afhankelijke variabele hebt en een categorische onafhankelijke variabele (met twee groepen). Een chi-kwadraattoets voor samenhang wordt gebruikt bij twee categorische variabelen.
Er kan een onderscheid worden gemaakt tussen kwantitatieve en categorische variabelen:
Bij kwantitatieve variabelen representeren de data hoeveelheden (zoals een lengte, gewicht, leeftijd).
Bij categorische variabelen representeren de data groepen, zoals een ranking (bijvoorbeeld de eindposities bij het songfestival), classificaties (bijvoorbeeld kledingmerken), en binaire verdelingen (zoals kop of munt).
De nulhypothese wordt vaak afgekort tot H0. Als de nulhypothese wordt beschreven met wiskundige symbolen, bevat deze altijd een gelijkheidssymbool (meestal =, maar soms ook ≥ of ≤).
De alternatieve hypothese wordt vaak afgekort tot Ha of H1. Als de alternatieve hypothese wordt beschreven met wiskundige symbolen, bevat deze altijd een ongelijkheidssymbool (meestal ≠, maar soms ook < of >).
Een onderzoekshypothese is jouw verwachte antwoord op de onderzoeksvraag. De onderzoekshypothese bevat meestal een verklaring (x beïnvloedt y omdat…).
Een statistische hypothese is een wiskundige uitspraak over een populatieparameter. Statistische hypothesen komen altijd in paren: de nul- en alternatieve hypothese.
In een goede onderzoeksopzet komen de nul- en alternatieve hypothese logisch overeen met de onderzoekshypothese. Soms hoef je alleen de alternatieve hypothese te formuleren.
Als er drie of meer vrijheidsgraden zijn, heeft de verdeling de vorm van een rechtsscheve bult (hump).
Naarmate het aantal vrijheidsgraden verder toeneemt, wordt de bult minder rechtsscheef en verschuift de piek van de bult naar rechts. De verdeling gaat steeds meer lijken op een normale verdeling.
Je kunt de Pearson correlatiecoëfficiënt (r) gebruiken als je een correlatie tussen twee variabelen wilt meten en (1) het verband tussen de variabelen lineair is, (2) beide variabelen kwantitatief zijn, (3) beide variabelen continu van aard zijn, (4) normaal verdeeld zijn en (5) geen uitschieters hebben.
Je kunt de cor() functie gebruiken om de Pearson correlatiecoëfficiënt (r) in R te berekenen. Om de significantie van de correlatie te testen, kun je de cor.test() functie gebruiken.
Je kunt de PEARSON() functie gebruiken om de Pearson correlatiecoëfficiënt (r) in Excel te berekenen. Als je variabelen in de kolommen A en B staan, klik je op een lege cel en typ je “PEARSON(A:A, B:B)”.
Er is geen functie om de significantie van de correlatie direct te berekenen.
Je kunt de qt() functie gebruiken om de kritieke waarde van t te vinden in R. De functie geeft de kritieke waarde van t voor de eenzijdige toets. Als je de kritieke waarde van t voor een tweezijdige toets wilt, deel je het significantieniveau door twee.
Voorbeeld: De kritieke waarde van t berekenen in ROm de kritieke waarde van t voor een tweezijdige toets met df = 29 en α = .05 te berekenen, gebruik je de volgende functie:
Je kunt de T.INV() functie gebruiken om de kritieke waarde van t te vinden voor eenzijdige toetsen in Excel. Voor tweezijdige toetsen gebruik je de T.INV.2T() functie.
Voorbeeld: De kritieke waarde van t berekenen in ExcelOm de kritieke waarde van t te berekenen voor een tweezijdige toets met df = 29 en α = .05, klik je op een lege cel en typ je:
Kies het significantieniveau op basis van het gewenste betrouwbaarheidsniveau. Het meest gebruikelijke betrouwbaarheidsniveau is 95%, wat overeenkomt met α = .05 in de tweezijdige t-tabel.
Zoek de kritieke waarde van t in de tweezijdige t-tabel.
Vermenigvuldig de kritieke waarde van t met .
Tel deze waarde bij het gemiddelde op om de bovengrens van het betrouwbaarheidsinterval te berekenen, en trek deze waarde van het gemiddelde af om de ondergrens van het betrouwbaarheidsinterval te berekenen.
Deze extreme waarden kunnen ook de statistische power van je toets beïnvloeden, waardoor het moeilijk wordt een echt effect op te sporen, als er wel een effect is (Type II-fout).
Je kunt outliers het beste alleen verwijderen als je daar een goede reden voor hebt.
Sommige uitschieters vertegenwoordigen natuurlijke variatie in de populatie en deze mogen niet worden verwijderd uit je dataset. Dit zijn echte uitschieters.
Andere uitschieters zijn problematisch en moeten worden verwijderd uit je dataset. Deze uitschieters zijn meetfouten, invoer- of verwerkingsfouten, of data uit een niet-representatieve steekproef.
De e in de formule van de Poissonverdeling staat voor het getal 2.718. Dit getal wordt de constante van Euler genoemd. Je kunt e simpelweg vervangen door 2.718 als je een kans van de Poissonverdeling berekent. De constante van Euler is een heel nuttig getal en is vooral belangrijk in de wiskunde.
In de formule van de Poissonverdeling is lambda (λ) het gemiddelde aantal gebeurtenissen binnen een bepaald tijds- of ruimte-interval. Bijvoorbeeld: λ = 0.748 overstromingen per jaar.
Het enige verschil tussen een one-way ANOVA en een two-way ANOVA is het aantal onafhankelijke variabelen. Een one-way ANOVA heeft één onafhankelijke variabele, terwijl een two-way ANOVA er twee heeft.
One-way ANOVA: Toetst de relatie tussen het merk schoen (Nike, Adidas, Saucony, Hoka) en de finishtijd van een marathon.
Two-way ANOVA: Toetst de relatie tussen het merk schoen (Nike, Adidas, Saucony, Hoka), leeftijdsgroep van de loper (junior, senior, master) en de finishtijd van een marathon.
Alle ANOVA’s zijn bedoeld om te toetsen op verschillen tussen drie of meer groepen. Als je alleen op een verschil tussen twee groepen wilt testen, gebruik dan een t-toets.
Een factoriële ANOVA is elke ANOVA die meer dan één categorische onafhankelijke variabele gebruikt. Een two-way ANOVA is een soort factoriële ANOVA.
Enkele voorbeelden van scenario’s waarin je factoriële ANOVA’s gebruikt, zijn:
Het toetsen van de gecombineerde effecten van vaccinatie (gevaccineerd of niet gevaccineerd) en gezondheidsstatus (gezond of al bestaande aandoening) op de mate van griepinfectie in een populatie.
Het toetsen van de effecten van burgerlijke staat (gehuwd, ongehuwd, gescheiden, weduwnaar), beroepsstatus (zelfstandig, werkend, werkloos, gepensioneerd) en familiegeschiedenis (geen familiegeschiedenis, enige familiegeschiedenis) op de incidentie van depressie in een populatie.
Het toetsen van effecten van het soort voeding (soort A, B of C) en stalbezetting (niet vol, enigszins vol, zeer vol) op het eindgewicht van kippen in een commercieel landbouwbedrijf.
Bij een ANOVA is de nulhypothese dat er geen verschil is tussen de groepsgemiddelden. Als een groep significant verschilt van het algemene groepsgemiddelde, dan zal de ANOVA een statistisch significant resultaat rapporteren.
Significante verschillen tussen groepsgemiddelden worden berekend met behulp van een F-statistiek, die de verhouding weergeeft tussen de gemiddelde som van de kwadraten (de variantie die door de onafhankelijke variabele wordt verklaard) en de gemiddelde kwadratische fout (de variantie die overblijft).
Als de F-statistiek hoger is dan de kritieke waarde (de waarde van F die overeenkomt met je alfa-waarde, meestal 0.05), dan wordt het verschil tussen groepen statistisch significant geacht.
De past participle van “run” is “run“. Aangezien “run” een onregelmatig werkwoord is, wordt het voltooid deelwoord niet gevormd door het suffix -ed toe te voegen. De past simple (onvoltooid verleden tijd) van “run” is “ran”.
De past participle van “ride” is “ridden“. Aangezien “ride” een onregelmatig werkwoord is, wordt het voltooid deelwoord niet gevormd door het suffix -ed toe te voegen. De past simple (onvoltooid verleden tijd) van “ride” is “rode”.
A en an zijn twee vormen van het Engelse onbepaald lidwoord. Je gebruikt “a” voor woorden waar je de “h” uitspreekt, zoals “hotel”, “hat” en “hard”. Als je de “h” niet uitspreekt, gebruik je “an” (zoals bij “hour” dat wordt uitgesproken als “our”). Bij “historic” spreek je de “h” uit, dus je gebruikt “a historic” in plaats van “an historic”.
A en an zijn twee vormen van het Engelse onbepaald lidwoord. Woorden waarbij je de “u” uitspreekt als “you”, zoals “user”, “usual” of “utilized” worden voorafgegaan door “a” in plaats van “an”. Aangezien “unique” begint met de “you-klank” schrijf je “a unique” in plaats van “an unique”.
A en an zijn verschillende vormen van het Engelse onbepaald lidwoord. Woorden waarbij de “h” niet wordt uitgesproken, zoals “honor” en “honest” worden voorafgegaan door “an” in plaats van “a”. Aangezien de “h” bij “hour” niet wordt uitgesproken is het “an hour” in plaats van “a hour”.
A en an zijn twee vormen van het Engelse onbepaald lidwoord. Als de “u” wordt uitgesproken als “you”, zoals bij “unique” wordt het woord voorafgegaan door “a” in plaats van “an”. Aangezien de “u” in “user” wordt uitgesproken als “you”, is het “a user” in plaats van “an user”.
A en an zijn twee vormen van het Engelse onbepaald lidwoord. Je gebruikt “an” voor woorden die qua uitspraak beginnen met een klinker. Hoewel “European” gespeld wordt met een “e”, is de eerste klank een “j”. Daarom zeg je “a European” in plaats van “an European”.
Nowadaysis een Engelse term die vooral in spreektaal wordt gebruikt. In academisch schrijven kan nowadays dus het beste vermeden worden. De term wordt als te vaag beschouwd en kan daardoor de lezer misleiden. Wees specifieker als je het over de tegenwoordige tijd hebt: sinds wanneer speelt de situatie die je beschrijft zich precies af?
All right of alright betekent in het Nederlands “oké”. De term kan enigszins verschillen in betekenis, afhankelijk van de manier waarop het in de zin wordt gebruikt.
Beide schrijfwijzen zijn correct, maar alleen all right wordt als algemeen correct beschouwd. De term kan in een academische tekst het beste helemaal worden vermeden, omdat het woord als te informeel wordt beschouwd.
De -ing-vorm van een Engels werkwoord wordt het onvoltooid deelwoord (present participle) genoemd. Deze vorm kan worden gebruikt als een bijvoeglijk naamwoord (“a thrilling story”) of voor de present continuous, past continuous of future continuous (e.g., “We are partying“).
Fulfillis een werkwoord dat “tot voltooiing brengen”, “aan een eis voldoen” of “erin slagen iemands kwaliteiten of capaciteiten te ontwikkelen” kan betekenen.
Soms wordt ten onrechte “fullfill” in plaats van fulfill gebruikt. “Fullfill” is echter nooit correct.
Tip: Twijfel je over de spelling van je Engelse tekst? Maak gebruik van Scribbrs gratis Grammatica Check en laat je tekst gemakkelijk automatisch nakijken op spelling.
Hoeveel uur je kunt werken naast je studie of stage hangt af van het aantal uur dat je aan je studie of stage zit. Gemiddeld besteden studenten nog 16 uur naast hun studie of stage aan een bijbaan. Maar als je studie meer contacturen dan gemiddeld heeft, of als je stage meer uren vraagt, kan dit voor jou anders zijn. Het is aan te raden in een week maximaal 40 uur te besteden aan werken en studeren samen.
Belangrijk is dat je zeker een dag in het weekend vrij hebt voor jezelf, zodat je ook bij kunt komen van je werk- en studietaken.
Loonheffingskorting is korting die je krijgt over de belasting die je betaalt als je werkt. Loonheffingskorting mag je ook toepassen op je stage als je een stagevergoeding ontvangt. Helaas geldt dat je maar voor één baan de loonheffingskorting aan mag hebben staan, dus als je zowel een stage loopt als een bijbaan hebt, kun je maar voor één van de twee banen de loonheffingskorting aanzetten.
Het is aan te raden de loonheffingskorting aan te zetten bij de baan waar je het meeste aantal uren werkt of het meeste verdient.
Argumentum ad nauseam (argument bij herhaling) betekent dat een argument zo vaak wordt herhaald dat mensen gaan geloven dat het waar is. Dit kan worden versterkt als de tegenstander geen weerwoord meer geeft, bijvoorbeeld omdat iemand niet steeds hetzelfde tegenargument wil herhalen.
Argumentum ad populum (beroep op de meerderheid) betekent dat mensen denken dat iets goed of correct is, omdat de meerderheid het argument steunt. In veel gevallen zijn argumenten die door veel mensen gesteund worden waar, maar het feit dat veel mensen iets steunen maakt het argument niet waar. Het kan nog steeds fout zijn, want de meerderheid heeft niet altijd gelijk.
Vice versa komt uit het Latijn en betekent “omgekeerd”, “andersom”, “heen en terug” of “over en weer”. Je kunt het letterlijk vertalen met “nadat de beurt is omgedraaid”.
Voorbeelden van vice versa in een zin
Je kunt eerst je huiswerk maken en dan schoonmaken, of vice versa.
Je kunt eerst je huiswerk maken en dan schoonmaken, of andersom.
Er zijn verschillende manieren waarop je onderscheid kunt maken tussen verschillende soorten zelfstandig naamwoorden. Een zelfstandig naamwoord kan ook in meerdere categorieën vallen of van categorie veranderen, afhankelijk van de context.
Voornaamwoorden zijn woorden zoals “ik”, “zij” en “hij” die op eenzelfde manier worden gebruikt als zelfstandig naamwoorden. Ze worden ingezet om te verwijzen naar een zelfstandig naamwoorddat al genoemd is of om naar jezelf of andere personen te verwijzen.
Voornaamwoorden kunnen net als zelfstandig naamwoorden de kern van een naamwoordgroep vormen, en ze komen voor als onderwerp of object bij een werkwoord. In tegenstelling tot zelfstandig naamwoorden kunnen voornaamwoorden wel van vorm veranderen (bijvoorbeeld van “ik” naar “mij”) op basis van de grammaticale context waarin het woord voorkomt.
Je gebruikt signaalwoorden in je betoog, zodat de verbanden tussen deelzinnen, zinnen en alinea’s duidelijk zijn voor de lezer. Hierdoor kun je je punt beter overbrengen. Je vindt een volledig overzicht van signaalwoorden en voorbeelden voor alle soorten verbanden in ons artikel over signaalwoorden. Ook kun je onderstaande lijst met signaalwoorden downloaden:
De afkorting van mevrouw in het Engels is Ms., Mrs. of Miss, afhankelijk van iemands leeftijd en burgerlijke staat (relatiestatus, huwelijkse staat).
Ms. is een neutrale optie die kan worden gebruikt voor oudere, ongetrouwde vrouwen, maar ook voor volwassen vrouwen van wie je de relatiestatus niet weet.
Mrs. is een vorm om getrouwde vrouwen mee aan te spreken
Miss is een vorm om jonge en/of ongetrouwde vrouwen mee aan te spreken
Ms. is dus de veiligste optie als de leeftijd en burgerlijke staat onbekend zijn.
De afkorting voor de heer en mevrouw is “dhr. en mevr.” of “dhr. en mw.”, maar het wordt aangeraden om deze afkortingen voluit te schrijven. Dit geldt ook voor de afkorting van de heer en de afkorting van mevrouw als ze individueel voorkomen.
De afkorting van meneer in het Engels is “Mr.” (met een hoofdletter). Deze afkorting staat voor het Engelse “Mister”. De Nederlandse afkorting is ook “mr.”, maar dan met een kleine letter.
De afkorting voor mevrouw is “Ms.”, “Miss”, of “Mrs.”, afhankelijk van de leeftijd en relatiestatus van de vrouw.
Witte sneeuw is een pleonasme (herhaling van een eigenschap die onlosmakelijk verbonden is met het woord). Een tautologie lijkt op een pleonasme, maar in dat geval gebruik je twee woorden die (nagenoeg) hetzelfde betekenen, zoals “ik ben blij en verheugd“.
“Witte” en “sneeuw” betekenen niet hetzelfde, dus het gaat niet om een tautologie. Witte is wel een eigenschap van sneeuw die onlosmakelijk verbonden is met het woord, dus het is een pleonasme.
Groen gras is een pleonasme (herhaling van een eigenschap die onlosmakelijk verbonden is met het woord). Een tautologie lijkt op een pleonasme, maar in dat geval gebruik je twee woorden die (nagenoeg) hetzelfde betekenen, zoals “ik ben nerveus en zenuwachtig“.
“Groen” en “gras” betekenen niet hetzelfde, dus het gaat niet om een tautologie. Groen is wel een eigenschap van gras die onlosmakelijk verbonden is met het woord, dus het is een pleonasme. Verder is “groen gras” door de herhaling van de beginletter “g” ook een alliteratie.
Een alliteratie is een vorm van rijm waarbij dezelfde beginletter een aantal keer achter elkaar wordt herhaald. Aliteratie met één l is een verkeerd gespelde variant op dit woord.
Een alliteratie is een vorm van rijm waarbij dezelfde beginletter een aantal keer achter elkaar wordt herhaald. Een anafoor is een herhaling van een of meerdere woorden in één of meerdere zinnen.
Voorbeeld: alliteratie vs anafoor
Alliteratie: Liesje leerde Lotje lopen langs de lange Lindelaan.
Anafoor:Niemand die het ziet. Niemand die het hoort. Niemand die het merkt.
Een dysfemisme is het tegenovergestelde van een eufemisme. Hierbij beschrijf je iets op een grovere of aanstootgeverende manier dan nodig is, terwijl je bij een eufemisme verzachtende termen gebruikt.
Eufemisme is afgeleid van het Oudgriekse εὖ (“goed”) en φήμη (“bericht”). Een eufemisme is een zachtere, minder grove manier om iets hards of onaangenaams te beschrijven.
Contradictio in terminus is de verkeerde spelling van contradictio in terminis. Dit stijlfiguur bestaat uit een verbinding van twee woorden die onmogelijk is. Vaak wordt een contradictio in terminis bewust gebruikt om ironie over te brengen.
Een humane oorlog (oorlogen zijn nooit humaan)
Duitse humor (ironisch bedoeld: Duitsers staan niet bekend om hun gevoel voor humor)
Over het algemeen genomen wordt een contradictio in terminis gezien als stijlfiguur en niet als stijlfout, omdat sprekers en schrijvers er vaak bewust gebruik van maken. Een doel van dit stijlfiguur is het overbrengen van ironie.
Voor academische teksten, zoals een scriptie, wordt het gebruik van een contradictio in terminis doorgaans afgeraden, maar het stijlfiguur is populair onder schrijvers van opinieartikelen. Ook wordt het stijlfiguur vaak gebruikt in alledaagse gesprekken.
Hoewel stijlfiguren gebruikelijk zijn in een toespraak, betoog, boek of gedicht, wordt het afgeraden om ze te gebruiken in een academische tekst, zoals een scriptie.
Een homerische vergelijking is een hele uitgebreide, niet-noodzakelijke vergelijking die ontzettend lang doorgaat en vaak gebruikmaakt van niet-relevante beeldspraak. Het is een stijlfiguur dat veel voorkomt in de Ilias en de Odyssee (geschreven door Homerus).
Een boutade is een stijlfiguur waarbij een grappige, korte uitspraak wordt gebruikt om ontevredenheid of een ander negatief gevoel uit te drukken. Een voorbeeld hiervan is: “De mensheid wordt intelligenter, maar niet slimmer.”
Elisie is een stijlfiguur waarbij een of meerdere klanken worden weggelaten. Dit stijlfiguur wordt vooral gebruikt in de poëzie om het metrum (ritme) te behouden als er eigenlijk te veel lettergrepen zijn. Bijvoorbeeld:
’t een of ’t ander, mij maakt ’t niet uit.
De weggelaten klank wordt vervangen door een apostrof.
Bij een enallage wordt een bijvoeglijk naamwoord voor een woord geplaatst, terwijl het inhoudelijk beter zou passen bij een ander woord in de zin.
Een enallage is meestal een stijlfiguur. Sommige enallages zijn zo vaak gebruikt dat ze volledig zijn ingeburgerd, waardoor er geen verwarring over de betekenis ontstaat. Bijvoorbeeld:
Een lekker bordje eten (het eten is lekker, niet het bordje).
Ad hominem tu quoque (“jij ook”) is een poging om een bewering te weerleggen door de voorstander ervan aan te vallen op grond van het feit dat hij met twee maten meet of dat hij niet doet wat hij zegt. Bijvoorbeeld, iemand vertelt je dat je langzaam moet rijden anders krijg je een dezer dagen een bekeuring voor te hard rijden, en jij antwoordt “maar die kreeg je vroeger ook altijd!”.
Argumentum ad hominem betekent “argument op de persoon” in het Latijn en het wordt meestal aangeduid als ad hominem argument of persoonlijke aanval. Ad hominem argumenten worden gebruikt in debatten om een argument te weerleggen door het karakter van de persoon die het argument maakt aan te vallen, in plaats van de logica of premisse van het argument zelf.
Een drogreden is een denkfout of verkeerde overtuiging, met name eentje die gebaseerd is op ongegronde argumenten. Veel voorkomende soorten drogredenen die de kwaliteit van je onderzoek in gevaar kunnen brengen zijn:
Onjuiste oorzaak-gevolgrelatie (onjuist beroep op causaliteit): Beweren dat twee gebeurtenissen die samen voorkomen een oorzaak-gevolgrelatie hebben, ook al kan dit niet worden bewezen.
Ecologische denkfout (ecological fallacy): Inferenties maken over de aard van individuen op basis van geaggregeerde data over de groep.
Sunk cost fallacy: Doorgaan met een project of beslissing omdat je er al tijd, moeite of geld in hebt geïnvesteerd, zelfs als de huidige kosten hoger zijn dan de baten.
Base rate fallacy: het negeren van base rate of statistisch significante informatie, zoals de steekproefgrootte of de relatieve frequentie van een gebeurtenis, ten gunste van minder relevante informatie, bijvoorbeeld met betrekking tot een enkel geval of een klein aantal gevallen.
Planningsfout (planning fallacy): Het onderschatten van de tijd die nodig is om een toekomstige taak te voltooien, zelfs als je weet dat soortgelijke taken in het verleden langer hebben geduurd dan gepland.
De sunk cost fallacy en escalatie van inzet (of commitment bias) zijn twee nauw verwante termen. Er is echter een klein verschil tussen beide:
Escalatie van inzet (ook wel commitment bias genoemd) is de neiging om consistent te zijn met wat we in het verleden al hebben gedaan of gezegd dat we daadwerkelijk zullen doen, vooral als we dat in het openbaar hebben gedaan. Met andere woorden, het is een poging om ons gezicht te redden en consistent te lijken.
Sunk cost fallacy is de neiging om vast te houden aan een beslissing of een plan, zelfs als het plan mislukt. Omdat we al waardevolle tijd, geld of energie hebben geïnvesteerd, voelt stoppen alsof deze middelen verspild zijn.
Met andere woorden, een commitment bias is een manifestatie van de sunk cost fallacy: een irrationele escalatie van inzet (i.e., een toenemende betrokkenheid) komt vaak voor wanneer mensen weigeren te accepteren dat de middelen die ze al hebben geïnvesteerd niet kunnen worden terugverdiend. In plaats daarvan dringen ze aan op meer uitgaven om de initiële investering (en de opgelopen verliezen) te rechtvaardigen.
“Überhaupt” is een Duits leenwoord dat gewoon gebruikt mag worden in het Nederlands (net als “sowieso“). Voor formele of academische teksten, zoals een scriptie, is het beter om een alternatief te kiezen, zoals “helemaal”, “toch al” of “over het algemeen”.
“Ik spreek überhaupt maar één woord Duits” is een grapje van cabaretier Herman Finkers. Überhaupt is, net als sowieso, een Duits leenwoord, waardoor dus geïmpliceerd wordt dat “überhaupt” het enige Duitse woord is dat Herman Finkers kent.
Een antoniem voor mits is “tenzij” of “behalve als”.
Luca gaat morgen mee naar de bioscoop, mits hij op tijd klaar is met werk.
Dit betekent dat Luca van plan is om naar de bioscoop te gaan, op voorwaarde dat hij op tijd klaar is met werk. Hij gaat dus alleen mee als hij op tijd thuis is.
Luca gaat morgen mee naar de bioscoop, tenzij hij op tijd klaar is met werk.
Dit betekent dat Luca van plan is om naar de bioscoop te gaan, behalve als hij op tijd klaar is met werk. Hierdoor is de betekenis van de zin omgedraaid.
Luca gaat morgen niet mee naar de bioscoop, tenzij hij op tijd klaar is met werk.
Dit betekent dat Luca niet van plan is om naar de bioscoop te gaan, behalve als hij op tijd klaar is met werk. Hierdoor lijkt de betekenis weer op die van de eerste zin, maar er is nog een subtiel verschil. In het eerste geval is Luca van plan om te gaan als aan de voorwaarde van op tijd thuis zijn wordt voldaan. In het laatste geval is Luca niet van plan om te gaan, behalve als hij (onverwacht) wel op tijd klaar is met werk.
Een synoniem voor door middel van is “met”, “door” of “middels”. Het gebruik van middels kan als ouderwets worden gezien, dus het is beter om dat synoniem te vermijden.
Voorbeelden: Synoniemen voor door middel van
De hypothesen zijn getoetst door middel van een experiment.
De hypothesen zijn getoetst met een experiment.
De hypothesen zijn getoetst middels een experiment. [formeel, ouderwets]
De afkorting van door middel van is d.m.v. met kleine letters die worden gescheiden door punten. In formele teksten, zoals een scriptie, is het beter om de afkorting voluit te schrijven.
De afkorting van naar aanleiding van is “n.a.v.”, met kleine letters die gescheiden worden door punten. In formele of academische teksten, zoals een scriptie, is het beter om deze afkorting voluit te schrijven.
Hoe gaat het met jou is correct. In dit geval is er geen sprake van een bezitsrelatie en “jou” wordt niet gevolgd door een zelfstandig naamwoord, dus de vorm zonder w is correct. Jou is hier een persoonlijk voornaamwoord.
Schikt het jou is correct. In dit geval is er geen sprake van een bezitsrelatie en “jou” wordt niet gevolgd door een zelfstandig naamwoord, dus de vorm zonder w is correct. Jou is hier een persoonlijk voornaamwoord.
Bij jou thuis is correct. Jou is hier een persoonlijk voornaamwoord en thuis is hier een bijwoord (van plaats). In dit geval kun je “thuis” eigenlijk ook weglaten.
Je kunt controleren of je jou of jouw moet gebruiken met een ezelsbruggetje. Als je het door “zijn” kunt vervangen, is het jouw (bezittelijk voornaamwoord). Als je het door “hem” kunt vervangen, is het jou (persoonlijk voornaamwoord).
In dit geval kun je wel zeggen “bij hem thuis”, maar niet “bij zijn thuis”, dus moet het “jou” zijn.
De afkorting van onder andere of onder anderen is o.a. Het maakt voor deze afkorting niet uit of je de vorm met of zonder -n gebruikt.
In de meeste contexten is het prima om deze afkorting te gebruiken, maar in academische of formele teksten is het beter om onder andere(n) uit te schrijven.
Een synoniem voor onder andere of onder anderen is “onder meer“. Dit woord betekent ook “behalve andere dingen, ook”. Je schrijft onder meer altijd met een spatie.
De participanten werden onder andere geworven op de campus.
De participanten werden onder meer geworven op de campus.
Een synoniem voor onder meer is onder andere of onder anderen. Je gebruikt “onder andere” als je naar zaken of dieren verwijst en “onder anderen” als je naar personen verwijst.
Voorbeeld
Ik heb onder meer Veronique en Laetitia om hun mening gevraagd.
Ik heb onder anderen Veronique en Laetitia om hun mening gevraagd.
De verwarring wordt mogelijk veroorzaakt door het verdwijnen van de spatie in andere vaste combinaties die veelvuldig gebruikt worden, zoals daarentegen of evenals.
In die samengesmolten combinaties wordt het ene woord nadrukkelijker uitgesproken dan het andere woord. Er is sprake van een eenheidsaccent. Bij “onder meer” (en zonder meer) geldt dat beide woorden nadruk krijgen. Ze worden dus los geschreven.
Zondermeer is een verkeerd gespelde variant op zonder meer, wat “absoluut”, “zonder twijfel” of “blindelings” betekent.
De verwarring zou kunnen worden veroorzaakt door het verdwijnen van de spatie in andere vaste combinaties die vaak gebruikt worden, zoals evenals of daarentegen.
In die samengesmolten combinaties wordt het ene woord nadrukkelijker uitgesproken dan het andere woord. Er is sprake van een eenheidsaccent. Bij “zonder meer” (en onder meer) geldt dat beide woorden nadruk krijgen. Ze worden dus los geschreven.
In de constructie “sommige(n) van” gebruik je “sommigen” als het gevolgd wordt door een persoonlijk voornaamwoord of een enkelvoudig zelfstandig naamwoord. Jullie is een persoonlijk voornaamwoord, dus “sommigen van jullie” is correct.
Het is moeilijk om te bepalen of je sommige of sommigen moet gebruiken. Je gebruikt sommigen met -n alleen als het woord zelfstandig gebruikt is en naar personen verwijst.
In dit geval staat na “sommige” nog het zelfstandig naamwoord “mensen”, dus het is niet zelfstandig gebruikt. Daarom is de vorm zonder -n, sommige, correct.
In de constructie “de meeste(n) van” gebruik je “meesten” als het gevolgd wordt door een persoonlijk voornaamwoord of een enkelvoudig zelfstandig naamwoord. Jullie is een persoonlijk voornaamwoord, dus “ de meesten van jullie” is correct.
De meeste van jullie moeten je nog aanmelden.
De meesten van jullie moeten je nog aanmelden.
TipBekijk ons uitgebreide artikel over het gebruik van meeste of meesten.
In de constructie “de meeste(n) van” gebruik je “meesten” als het gevolgd wordt door een persoonlijk voornaamwoord of een enkelvoudig zelfstandig naamwoord. U is een persoonlijk voornaamwoord, dus “ de meesten van u” is correct.
Ik heb, net zoals de meeste van u, nog geen update ontvangen.
Ik heb, net zoals de meesten van u, nog geen update ontvangen.
TipBekijk ons uitgebreide artikel over het gebruik van meeste of meesten.
In de constructie “de meeste(n) van” gebruik je “meesten” als het gevolgd wordt door een persoonlijk voornaamwoord of een enkelvoudig zelfstandig naamwoord. Ons is een persoonlijk voornaamwoord, dus “de meesten van ons” is correct.
Sommige van ons hebben het tentamen niet gehaald.
Sommigen van ons hebben het tentamen niet gehaald.
TipBekijk ons uitgebreide artikel over het gebruik van meeste of meesten.
Weids en wijds zijn twee woorden die hetzelfde worden uitgesproken, maar iets anders betekenen. In de vaste uitdrukking “een weids uitzicht” is de vorm met korte ei correct.
Uitweiden en uitwijden zijn woorden die hetzelfde worden uitgesproken, maar iets anders betekenen. Een synoniem voor “uitwijden” is “wijder maken” of “uitzetten”.
Uitweiden en uitwijden zijn woorden die hetzelfde worden uitgesproken, maar iets anders betekenen. Een synoniem voor uitweiden is “uitvoerig praten” of “afdwalen”.
Inwijden en inweiden zijn twee woorden die hetzelfde worden uitgesproken, maar iets anders betekenen. Een ander woord voor inwijden is “zegenen”, “inhuldigen” of “in gebruik nemen”.
Dit komt doordat verwijzingen in de tekst volgens de APA-stijl en MLA-stijl tussen haakjes in de tekst worden geplaatst in plaats van in een voetnoot. Deze verwijzingen zijn al heel kort, dus ze hoeven niet nog korter.
Nee, in de Leidraad voor juridische auteurs wordt het gebruik van ibid. (ibidem), l.c. (locus citatus), t.a.p. (ter aangehaalde plaatse), a.w. (aangehaald werk) en o.c. (opus citatus) afgeraden. Deze afkortingen zijn niet informatief en kunnen juist voor onduidelijkheid zorgen.
Volgens de Chicago-stijl hanteer je het volgende format voor een DOI: https://doi.org/10.1177/0269881118806297.
Nair, Lakshmi S. and Cato T. Laurencin. “Biodegradable polymers as biomaterials.” Progress in polymer science 32, no. 8-9 (2007): 762-798. https://doi.org/10.1016/j.progpolymsci.2007.05.017.
De afkorting “et al.“ (Latijns voor “en anderen”) wordt gebruikt om verwijzingen naar bronnen met meerdere auteurs in te korten.
In APA-stijlwordt “et al.” gebruikt voor bronnen met 3+ auteurs, bijvoorbeeld (Smith et al., 2019). De term “et al.” wordt niet gebruikt in de APA-literatuurlijst.
In MLA-stijl wordt “et al.” toegepast voor 3+ auteurs in verwijzingen in de tekst en bronvermeldingen in de literatuurlijst.
In Chicago-stijl gebruik je “et al.” voor een verwijzing in de tekst naar een bron met 4+ auteurs en voor een bronvermelding in de literatuurlijst naar een bron met 10+ auteurs.
“Et al.“ is een afkorting van de Latijnse term “et alia”, wat “en anderen” betekent. Het wordt gebruikt in bronvermeldingen om ruimte te besparen als er te veel auteurs zijn om ze allemaal te noemen.
Richtlijnen voor het gebruik van “et al.” verschillen afhankelijk van de referentiestijl die je volgt. Zo hanteren APA, MLA en Chicago allemaal andere regels.
Performance bias is een algemene term die de effecten beschrijft van een ongelijke behandeling tussen onderzoeksgroepen. Als gevolg daarvan veranderen participanten hun gedrag.
Er zijn twee subtypen van performance bias: het Hawthorne-effect (of waarnemerseffect) en het John Henry-effect.
In onderzoek zijn vraagkenmerken (demand characteristics) signalen die participanten kunnen wijzen op het doel van het onderzoek. Deze signalen kunnen ertoe leiden dat participanten hun gedrag of reacties veranderen op basis van hun verwachtingen van het onderzoeksdoel.
Vraagkenmerken zijn veelvoorkomende problemen bij experimenten in de psychologie en andere sociaal-wetenschappelijke studies, omdat ze een vertekening (onderzoeksbias) van de onderzoeksresultaten kunnen veroorzaken.
Steekproefbias (sampling bias) treedt op als sommige leden van een populatie systematisch meer kans hebben om in een steekproef te worden geselecteerd dan anderen.
Exploratief onderzoek (exploratory research) is een flexibel type onderzoek waarbij je vragen probeert te beantwoorden die nog niet eerder uitgebreid onderzocht zijn.
Dit type onderzoek is meestal kwalitatief van aard, maar een exploratief onderzoek met een grote steekproef kan ook kwantitatief zijn. Vaak maak je hiervoor gebruik van de Grounded theory-methode.
Het is altijd duidelijk of een getal een parameter of statistiek is. Om te bepalen met welke van de twee je te maken hebt, kun jezelf de volgende vragen stellen:
Beschrijft het getal een gehele, complete populatie waarbij elk lid kan worden bereikt voor de dataverzameling?
Is het mogelijk om binnen een redelijke termijn data voor ieder lid van de populatie te verzamelen?
Als het antwoord op beide vragen ja is, is het getal waarschijnlijk een parameter. Als het antwoord op een van de vragen nee is, is de kans groter dat het om een statistiek gaat.
Een parameter is een waarde die een hele populatie beschrijft (bijvoorbeeld het populatiegemiddelde), terwijl een statistiek een getal is dat een steekproef beschrijft (bijvoorbeeld het steekproefgemiddelde).
Er bestaat een omgekeerd evenredig verband tussen het risico op een Type II-fout en de statistische power van een onderzoek. De power is de mate waarin een toets een daadwerkelijk bestaand effect correct kan detecteren.
Om het risico op een Type II-fout (indirect) te verkleinen, kun je de steekproef vergroten of het significantieniveau verhogen, omdat je zo de statistische power vergroot.
Het significantieniveau is meestal 0.05 of 5%. Dit betekent dat er een kans van 5% is dat de gevonden resultaten zouden voorkomen als de nulhypothese daadwerkelijk waar zou zijn.
Om het risico op een Type I-fout te verkleinen, verlaag je het significantieniveau alfa. Hiermee vergroot je wel het risico op een Type II-fout.
De t-verdeling is een meer conservatieve vorm van de standaardnormale verdeling (ook wel z-verdeling of standard normal distribution genoemd). Dit betekent dat de t-verdeling een lagere kansdichtheid geeft voor het centrum en een hogere kansdichtheid voor de staarten dan de standaard normaleverdeling.
Een t-score is het aantal standaarddeviaties van het gemiddelde in een t-verdeling. Je kunt een t-score opzoeken in een t-tabel of een online calculator voor de t-score gebruiken.
Bij statistiek worden t-scores voornamelijk gebruikt om de volgende waarden te bepalen:
De boven- en ondergrenzen van een betrouwbaarheidsinterval als de data ongeveer normaal verdeeld zijn.
De p-waarde van de teststatistiek voor t-toetsen en regressieanalyses.
De t-verdeling (ook wel t-distribution of Student’s t-distribution genoemd) wordt gebruikt als de data bij benadering normaal verdeeld zijn (en dus een klokvorm volgen), maar waarbij de populatievariantie onbekend is. De variantie in een t-verdeling wordt geschat op basis van het aantal vrijheidsgraden van de dataset (totaal aantal waarnemingen min 1).
De t-verdeling is een variant op de normale verdeling, maar deze wordt gebruikt voor kleinere steekproeven, waarbij de variantie onbekend is.
Statistische power (statistical power) verwijst naar de waarschijnlijkheid dat een hypothesetoets een echt effect vaststelt als dat effect er is. Dit noem je ook wel hetonderscheidend vermogen. Een toets met veel statistische power is beter in staat een Type II-fout (false negative) te voorkomen.
Als je onderzoek onvoldoende power heeft, kan het voorkomen dat je geenstatistisch significantresultaat vindt, zelfs als dit wel aanwezig is en praktische relevantie heeft. Hierdoor zou je ten onrechte de nulhypothese behouden.
Er zijn tientallen maten voor de effectgrootte. De maten die het vaakst gebruikt worden zijn Cohen’s d en Pearson’s r. Cohen’s d meet de grootte van een verschil tussen twee groepen, terwijl Pearson’s r de sterkte van een relatie tussen twee variabelen meet.
Je kunt ze berekenen met behulp van statistische software (zoals SPSS) of op basis van de formules.
Statistische significantie laat zien dat een effect, verschil of relatie bestaat in een onderzoek, terwijl praktische significantie (relevantie) laat zien dat het effect groot genoeg is om betekenisvol te zijn in de echte wereld.
De statistische significantie wordt gerapporteerd met behulp van p-waardes, terwijl de praktische relevantie wordt uitgedrukt met de effectgrootte.
De effectgrootte laat zien hoe betekenisvol de relatie tussen variabelen of het verschil tussen groepen is. Het zegt iets over de praktische relevantie (ook wel praktische significantie genoemd) van een onderzoeksresultaat.
Een klein effect heeft weinig praktische implicaties, terwijl een groot effect juist veel praktische implicaties kan hebben.
Het significantieniveau (alfa, α) geeft de maximale kans weer dat je de nulhypothese ten onrechte verwerpt (een Type I-fout). Je kiest het significantieniveau zelf voordat je een statistische toets uitvoert. Meestal kies je voor een α van 0.05 (5%) of 0.01 (1%).
Praktische significantie (ook wel praktische relevantie genoemd) laat zien of de onderzoeksuitkomst belangrijk genoeg is om betekenisvol te zijn in de echte wereld. Voor deze vorm van significantie rapporteer je de effectgrootte van het onderzoek.
Klinische significantie (ook wel klinische relevantie genoemd) is relevant voor interventie- en behandelingsstudies. Een behandeling wordt als klinisch significant beschouwd als deze het leven van patiënten tastbaar of substantieel verbetert.
Nee, de p-waarde zegt niets over de alternatieve hypothese. De p-waarde geeft aan hoe waarschijnlijk het is dat de data die je hebt gevonden zouden voorkomen als de nulhypothese waar zou zijn.
Als de p-waarde onder je grenswaarde (vaak p < 0.05) valt, kun je de nulhypothese verwerpen, maar dit betekent niet per se dat je alternatieve hypothese waar is.
Je berekent p-waarden meestal automatisch met het programma dat je gebruikt voor je statistische analyse (zoals SPSS of R). Je kunt de p-waarde ook schatten met behulp van tabellen voor de teststatistiek die je gebruikt.
P-waarden vertellen je hoe vaak een teststatistiek waarschijnlijk zou voorkomen onder de nulhypothese, op basis van de positie van de teststatistiek in de nulverdeling.
Als de teststatistiek ver verwijderd is van het gemiddelde van de nulverdeling, dan is de p-waarde klein. Dit laat zien dat het niet waarschijnlijk is dat de teststatistiek zou voorkomen als de nulhypothese waar is.
De standaarddeviatie of standaardafwijking wordt afgeleid van de variantie en vertelt je hoe ver iedere waarde gemiddeld genomen van het gemiddelde verwijderd is. Het is de vierkantswortel van de variantie.
Beide maten zeggen iets over de spreiding in een verdeling, maar de eenheden verschillen:
De standaarddeviatie wordt uitgedrukt in dezelfde eenheid als de oorspronkelijke waarden (bijvoorbeeld meters).
De variantie wordt uitgedrukt in veel grotere eenheden (bijvoorbeeld vierkante meters).
Statistische toetsen, zoals een variantieanalyse (ook wel Analysis of Variance of ANOVA genoemd), gebruiken steekproefvariantie om groepsverschillen te beoordelen. Ze gebruiken de varianties van de steekproeven om te beoordelen of de populaties waaruit ze afkomstig zijn van elkaar verschillen.
Cramer’s V is een gestandaardiseerde maat voor de samenhang tussen variabelen, terwijl chi-kwadraat geen gestandaardiseerde maat is. Met de chi-kwadraattoets kun je enkel beoordelen of het verschil tussen twee of meerdere verdelingen van elkaar verschillen.
Door de waarde voor chi-kwadraat om te zetten in Cramer’s V, kun je waarden met elkaar vergelijken.
Cramer’s V is een maat voor de effectgrootte die informatie geeft over de statistische samenhang tussen twee of meer variabelen van nominaal niveau. De waarde ligt tussen 0 en 1 en geeft aan hoe sterk twee categorische variabelen samenhangen.
De maat is gebaseerd op waarden uit de middelste helft van de dataset, waardoor het onwaarschijnlijk is dat de interkwartielafstand wordt beïnvloed door extreme waarden.
Centrummaten zeggen iets over het punt waar de meeste waarden geclusterd zijn (het midden of het centrum van je dataset). Spreidingsmaten geven informatie over de afstand tussen datapunten (hoe verspreid zijn de data).
Datasets kunnen dezelfde centrale tendens hebben en een verschillende mate van spreiding (of andersom). Door beide soorten maten te combineren, krijg je een compleet beeld van je data.
Nee, het bereik kan alleen 0 of een positieve waarde zijn, omdat je deze spreidingsmaat berekent door de laagste waarde van de hoogste waarde af te trekken.
Het bereik (ook wel spreidingsbreedte of range genoemd) is het interval tussen de laagste en de hoogste waarde in de dataset. Het is een veelgebruikte maat voor de spreiding (variability).
Met een risicoanalyse breng je de interne en/of externe risicofactoren van een bedrijf, organisatie of bepaald project in kaart. Hierbij stel je per bedreiging vast hoe groot de kans is dat het risico werkelijkheid wordt en welke consequenties dat zou hebben voor het bedrijf of project. Tot slot bepaal je de maatregelen om de risico’s te beperken.
Een nawoord is een terugblik op de periode van het schrijven van je scriptie of onderzoek. Je vertelt over je ervaringen en wat je hebt geleerd. In je nawoord kun je tevens mensen bedanken als je dit nog niet hebt gedaan in een voorwoord of dankwoord.
Je aanbevelingen worden meestal in een apart hoofdstuk opgenomen, na je conclusie en discussie. Je kunt ze ook opnemen in een apart adviesrapport als je opdrachtgever daarom vraagt.
In de aanbevelingen geef je je opdrachtgever adviezen over het vraagstuk dat je hebt onderzocht. Je beschrijft welke concrete oplossingen mogelijk zijn op de korte en/of lange termijn en welke maatregelen jij aanraadt op basis van je onderzoek.
De leeswijzer om de structuur van je scriptie te verduidelijken plaats je in de inleiding. Je kunt dit onderdeel eventueel opnemen in een aparte paragraaf op het eind van de inleiding.
De leeswijzer in de inleiding van je scriptie verduidelijkt de structuur van je scriptie. Hierin beschrijf je kort welke informatie ieder hoofdstuk bevat, zodat je lezers kunnen vinden wat ze zoeken en weten wat ze kunnen verwachten.
Een figuren- en tabellenlijst is vaak niet verplicht, maar wordt wel geadviseerd als je van veel figuren of tabellen gebruikmaakt en je scriptie aan de lange kant is.
In de figuren- en tabellenlijst staan alle in je scriptie gebruikte figuren en tabellen met het bijbehorende paginanummer opgesomd. Deze lijsten zorgen ervoor dat de lezer een overzicht heeft en snel kan zien op welke plek in je scriptie je bepaalde figuren en tabellen gebruikt.
Je voegt een begrippenlijst toe als deze de leesbaarheid van je scriptie vergroot. Maak je bijvoorbeeld gebruik van veel technische termen, dan is het aan te raden om een begrippenlijst toe te voegen. Als je slechts enkele begrippen definieert, is de lijst overbodig.
In de begrippenlijst van je scriptie vermeld je alfabetisch belangrijke begrippen en hun definities. Op deze manier kan de lezer deze makkelijk terugvinden zonder te hoeven terugzoeken in de scriptie.
In de afkortingenlijst, ook wel verklaring van afkortingen genoemd, vermeld je alfabetisch afkortingen van belangrijke begrippen in je scriptie. Op deze manier kan de lezer deze makkelijk terugvinden.
De ik-vorm of wij-vorm is toegestaan in het voorwoord. Meestal mag je deze vormen niet gebruiken in academische teksten, maar door het persoonlijke karakter van een voorwoord zijn de ik- en wij-vorm het meest gebruikelijk in dit onderdeel.
In het voorwoord mag je de lezer direct aanspreken met “je” of “u’. In academische teksten is de je-vorm in de regel niet toegestaan, maar in het persoonlijke voorwoord is dit dus wel gebruikelijk.
In je voorwoord kun je ingaan op de aanleiding voor het schrijven van je scriptie, je persoonlijke achtergrond, ervaringen tijdens het schrijven en de doelgroep van je scriptie. Daarnaast is dit de plek om mensen te bedanken die je met je scriptie hebben geholpen als je geen los dankwoord schrijft.
In de meeste gevallen kies je alleen voor een los dankwoord als je heel veel mensen wilt bedanken. Bij een scriptie is dit meestal niet het geval, waardoor je het dankwoord beter kunt opnemen in je voorwoord.
Op de informatiepagina vermeld je de titel (en ondertitel), evenals belangrijke informatie over jezelf (naam, studentenadministratienummer en e-mail), jouw begeleiders en de opleiding. Je sluit af met de datum waarop de scriptie wordt ingeleverd.
Een goede titel geeft kort en krachtig de inhoud van je scriptie weer. Je geeft informatie over het onderwerp door sleuteltermen te gebruiken en probeert de lezer enthousiast te maken voor je tekst.
Het woordje “er” kan verschillende functies vervullen in een zin.
Als “er” gebruikt wordt als plaatsaanduiding of in combinatie met een voorzetsel, mag je het niet weglaten.
Als onderwerp van een passieve zin, als voorlopig onderwerp en in combinatie met een telwoord mag “er” worden gebruikt, maar het is vaak beter om een andere formulering te kiezen.
In andere gevallen mag of moet “er” worden weggelaten.
Mijn is een bezittelijk voornaamwoord. Me is de onbenadrukte vorm van mij, zoals in “ik heb me vergist” en is nooit een bezittelijk voornaamwoord. Informele bezittelijke voornaamwoorden, zoals “m’n”, gebruik je nooit in academische teksten. “Mij” mag alleen gebruikt worden als er een voorzetsel voor staat: “dit onderzoek is van mij”.
Een bijvoeglijk naamwoord (adjectief) is een woord dat iets zegt over een zelfstandig naamwoord. Zo kan een bijvoeglijk naamwoord een eigenschap (kenmerk) of toestand beschrijven.
De rode auto
De vermoeide vrouw
De vertraagde trein
Woorden die iets zeggen over een ander soort woord, zoals een werkwoord of de gehele zin, zijn geen bijvoeglijk naamwoorden, maar bijwoorden.
Sommige opleidingen beschouwen passieve zinnen als fout en keuren scripties er zelfs op af. Veelvuldig gebruik van de lijdende vorm kan je tekst namelijk langdradig of moeilijk leesbaar maken. Probeer de lijdende vorm daarom te vervangen door de actieve vorm indien mogelijk.
Ieder woord is vrouwelijk, mannelijk of onzijdig. Daar hoort een vast lidwoord bij. Het woordgeslacht zie je aan een (o), (m) of (v)achter het woord in het woordenboek.
Bij onzijdige woorden gebruik je altijd het lidwoord “het” of “een”. Mannelijke en vrouwelijke woorden krijgen altijd “de” of “een” als lidwoord.
Je mag Engelse woorden gebruiken zonder ze te cursiveren of tussen aanhalingstekens te zetten, behalve als de kans groot is dat de lezer ze niet kent. In dat geval kun je de Engelse termen introduceren door ze te cursiveren.
Als je een tekst schrijft, is het makkelijk om voorzetseluitdrukkingen en vage voorzetsels zoals “middels” of “omtrent” te gebruiken, want ze passen in bijna elke zin.
Maar ze kunnen je tekst ook omslachtig en vaag maken. Gebruik ze daarom zo weinig mogelijk.
Voorzetsels zijn woorden zoals op, onder, in, door, behalve, tussen en tegen. Ze geven de relatie (bijvoorbeeld tijd, plaats of reden) aan tussen het woord waar ze voor staan en de andere woorden in de zin: tijdens de vakantie, in de scriptie, vanwege het slechte weer.
Een contaminatie is een verhaspeling van twee uitdrukkingen (of woorden) die samenhangen. Hierdoor ontstaat een nieuw woord of een nieuwe uitdrukking. Voorbeelden hiervan zijn:
Optelefoneren (opbellen en telefoneren)
Mond-op-mondreclame (mond-op-mondbeademing en mond-tot-mondreclame)
Iets is een samentrekking als een deel van een woord, een woord of meerdere woorden worden weggelaten in een zin. Bij een woordafbreking wordt een streepje neergezet zodat je weet waar iets is weggelaten.
Een puntkomma gebruik je tussen twee hoofdzinnen en bij opsommingen. Hiermee geef je aan dat de twee losse zinnen met elkaar verbonden zijn. In veel gevallen kan een puntkomma ook worden vervangen door een punt.
Na een puntkomma volgt nooit een hoofdletter, tenzij dat woord altijd met een hoofdletter wordt geschreven (zoals een naam).
De dubbele punt betekent in het eerste deel van de zin meestal “het volgende” of “als volgt” en in het tweede deel van de zin meestal “namelijk”, “want” of “immers”.
Komma’s gebruik je om een tekst beter leesbaar te maken. Een komma staat voor een rustpunt in de zin.
Je plaatst meestal een komma als je een pauze hoort in een zin als je deze hardop voorleest. In sommige gevallen moet je altijd een komma gebruiken, en in andere gevallen juist niet. Soms moet je eerst de context snappen om te weten of een komma aan de orde is.
Een verwijswoord wordt gebruikt om naar andere woorden, woordgroepen of hele zinnen te verwijzen. Hiermee zorg je voor variatie in de tekst. Hetgeen waarnaar je verwijst, wordt het antecedent genoemd.
Je presenteert belangrijke (of nieuwe) informatie aan het eind van de zin (niet per se het allerlaatste woord). Het accent ligt op deze plaats in de zin, waardoor informatie opvalt.
Als je de APA-richtlijnen volgt, mag je spelfouten in citaten niet zomaar verbeteren. In plaats daarvan zet je [sic] achter de fout om aan te geven dat je deze gezien hebt en dat je deze niet zelf geïntroduceerd hebt.
Van Wijck zegt hierover: “Ik vind vind [sic] dat millennials beter getraind moeten worden.”
Als je een fout ziet in een stuk tekst dat je wilt citeren, dan is de regel dat je de spelfouten en interpunctiefouten mag verbeteren, behalve wanneer je de APA-regels volgt.
De voor- en achternaam van personen schrijf je met hoofdletters. Als de achternaam begint met een tussenvoegsel, krijgt dat tussenvoegsel ook een hoofdletter als het vooraan staat: De Vries, Van der Laan.
Tussenvoegsels zoals de, van, el of da krijgen een kleine letter als er voorletters, een voornaam, een ander tussenvoegsel, of de achternaam van de partner voor staan: B. de Vries, Gert van der Laan, Caro Blok-de Lint, Van de Geijn. In scripties is het gebruikelijk om alleen achternamen te noemen.
Hoofdletters gebruik je in twee situaties: aan het begin van een zin en bij namen.
Je gebruikt ze bij namen van personen, bedrijven, instellingen, merken, wetten, boeken, aardrijkskundige plaatsen, talen, dialecten, volkeren, feestdagen en historische gebeurtenissen. Ook afleidingen van eigennamen en eigennamen in samenstellingen schrijf je met een hoofdletter.
Het is een goed idee om je tekst te controleren met een spellingchecker als je veel algemene spelfouten maakt. Een spellingchecker lost echter niet altijd alle problemen op en geeft af en toe zelfs een verkeerd advies.
TipAls je echt veel moeite hebt met spelling en zelfs met behulp van onze spellingscontrole nog twijfelt aan je tekst, kun je beter je tekst laten nakijken door een professional. Scribbr biedt een nakijkservice, waarbij een taalexpert je scriptie nakijkt en verbetert.
Als de laatste letter van de stam van het werkwoord voorkomt in “‘t exkofschip“, zoals bij de stam van het werkwoord werken (werk), dan eindigt het voltooid deelwoord op een –t: gewerkt.
Als de laatste letter van de stam van het werkwoord niet voorkomt in “’t ex-kofschip”, zoals bij het werkwoord zagen (stam is zag-, g zit niet in ’t exkofschip), dan eindigt het voltooid deelwoord op een –d: gezaagd.
Let op: De ik-vorm is niet altijd hetzelfde als de stam. Bepaal daarom altijd de stam van het werkwoord door -en van het hele werkwoord af te halen.
Het voltooid deelwoord van regelmatige werkwoorden wordt meestal gevormd door het prefix ge-, ver- of be- aan het werkwoord toe te voegen en door een –d of een –t aan het einde van het werkwoord te plakken, zoals bij ge-werk-t of be-antwoor-d.
Ook staat er een hulpwerkwoord in de zin (een vorm van “hebben” of “zijn”).
Als je een vraag stelt met de je- of jij-vorm, voeg je geen -t toe aan de stam, zoals “ga jij?” of “neem jij?”
Bij een werkwoord waarvan de stam eindigt op een -d hoor je echter niet dat je de -t moet weglaten, maar zo’n werkwoord vervoeg je wel precies hetzelfde als andere werkwoorden in de vragende vorm.
Je kunt veel voorbeelden van scripties vinden in gratis toegankelijke, online scriptiebanken (scriptie-databases). Deze worden meestal beheerd door een universiteit of hogeschool en bevatten (bijna) alle scripties en proefschriften die studenten hebben geschreven.
Een scriptiebank wordt vaak beheerd door een universiteit of hogeschool, en bevat (bijna) alle scripties en proefschriften die geschreven zijn door studenten. Scriptiebanken kunnen over het algemeen gratis worden gebruikt, waardoor onderwijsinstellingen bijdragen aan gratis, online toegang tot wetenschappelijke kennis.
Met een wetenschappelijkrelevant onderzoek draag je bij aan het bevorderen van de beschikbare wetenschappelijke kennis door bijvoorbeeld:
een gat (hiaat) in de literatuur op te vullen
een theoretisch probleem te helpen oplossen
aan bestaande literatuur bij te dragen
een nieuw perspectief op het onderwerp te introduceren
Als je een universitaire opleiding volgt, moet je de wetenschappelijke relevantie (ook wel theoretische relevantie genoemd) van je onderzoek bewijzen. Vaak is je onderzoek daarmee ook praktisch relevant.
Je kunt ervoor zorgen dat je onderzoek wetenschappelijk relevant is door na te gaan waar nog geen onderzoek naar gedaan is. Je kunt bijvoorbeeld kijken naar (nog niet uitgevoerde) vervolgonderzoeken die worden aangeraden in de discussie van wetenschappelijke artikelen of andere scripties.
Het doel van een probleemanalyse is om je onderwerp te verkennen en af te bakenen, zodat je vervolgens een specifieke probleemstelling en doelstelling kunt formuleren. Ook helpt de probleemanalyse je op weg om de juiste hoofd- en deelvragen op te stellen.
De probleemanalyse (ook wel probleemoriëntatie of probleemverkenning genoemd) is een van de belangrijkste stappen in het scriptieproces.
Tijdens je probleemanalyse oriënteer je je op het onderwerp en probeer je dit zo goed mogelijk af te bakenen. Je begint hierbij met een globaal vraagstuk dat zowel praktisch als theoretisch kan zijn.
In de probleemstelling geef je aan welk probleem of vraagstuk moet worden onderzocht. De probleemstelling is een bondige en concrete weergave van je probleem, die je afleidt uit je probleemanalyse.
Je probleemstelling wordt vaak opgenomen in de introductie (inleiding) van je scriptie. Eventueel kun je hiervoor een aparte paragraaf gebruiken. Ook komt deze stelling kort terug in je samenvatting.
Er is geen vast aantal deelvragen dat je moet opstellen. Wel is het zo dat hoe complexer je onderwerp is, hoe meer deelvragen je nodig zult hebben. Probeer je te beperken tot 4 à 5 deelvragen.
Als je er (veel) meer nodig hebt, moet je wellicht je hoofdvraag vereenvoudigen of beter afbakenen.
Deelvragen zijn de subvragen van je hoofdvraag. Vaak kun je de officiële onderzoeksvraag van je scriptie of onderzoek niet in één keer beantwoorden. Daarom gebruik je deelvragen die zich op een kleiner deel van je onderzoeksvraag focussen.
De antwoorden op al je deelvragen leiden tot de beantwoording van je hoofdvraag.
Het 5w- of 6w-model van Ferrell is een methode om meer inzicht te krijgen in het gedrag en de wensen van klanten. Door de 5 w’s (wie, wat, waar, wanneer en waarom) mee te nemen in je marktonderzoek, voer je een gedegen afnemersanalyse uit. De uitkomsten kunnen eventueel ook dienen als input van je SWOT-analyse.
Het waardestrategiemodel, ook wel waardedisciplinemodel, van Treacy en Wiersema wordt gebruikt om een marketingplan op te stellen, zodat een bedrijf zich kan onderscheiden van de rest.
Hierbij kies je prominent voor een van de drie waardestrategieën, maar je zorgt er ook voor dat de andere twee niet worden verwaarloosd. Het doel is om uit te blinken in één strategie, en de overige twee voldoende te onderhouden.
Treacy en Wiersema spreken van drie waardestrategieën in hun waardestrategiemodel:
Product leadership: Als een bedrijf zich richt op deze strategie, dan richt dit bedrijf zich op de ontwikkeling en innovatie van producten of diensten.
Customer intimacy: Als een bedrijf vooral klantgericht is, dan richt het zich op een langdurige klantrelatie.
Operational excellence: Een bedrijf dat zich richt op operationele uitmuntendheid optimaliseert zijn processen, van inkoop tot aflevering, om de kosten zo laag mogelijk te houden.
Voor de interne analyse van een bedrijf gebruik je het 7S-model van McKinsey. Je achterhaalt hiermee of de harde elementen (structuur, strategie en systemen) en de zachte elementen (staf, sleutelvaardigheden, stijl en significante waarden) in overeenstemming zijn.
Strategische doelstellingen (strategic): doelen die zijn bedoeld om je missie en visie te verwezenlijken.
Operationele doelstellingen (operations): de effectiviteit en efficiëntie van processen.
Doelstelling met betrekking tot de informatievoorziening (reporting): de betrouwbaarheid van de interne en externe informatievoorziening.
Doelstellingen met betrekking tot de naleving van wet- en regelgeving en richtlijnen (compliance): in hoeverre relevante wet- en regelgeving worden nageleefd.
Het COSO-ERM-model uit 2004 is een risicomanagementmodel waarmee je de relaties tussen risicocategorieën kunt identificeren om te bepalen in hoeverre een organisatie controle heeft over de situatie, oftewel in control is. Op basis van dit model kun je aanbevelingen doen om het risicomanagement te verbeteren.
Je kunt het SERVQUAL-modelgebruiken om te achterhalen hoe consumenten de kwaliteit van de dienstverlening ervaren. Hiervoor gebruik je vijf dimensies. Zo kun je bepalen welke gaps het verschil tussen de klantverwachting en klantervaring veroorzaken.
Je kunt het model handig toepassen als:
een bedrijf niet precies weet wat zijn klanten verwachten;
een bedrijf merkt dat klanten ontevreden zijn, maar niet weet waarom;
een bedrijf zijn dienstverlening beter wil afstemmen op de klant.
Een Gap-analyse met behulp van het SERVQUAL-model is een kwalitatieve onderzoeksmethode om de verwachtingen van klanten te vergelijken met hun daadwerkelijke ervaringen met een bedrijf.
Met de Waardeketen van Porter (Value Chain) kun je identificeren welke primaire en ondersteunende activiteiten van een bedrijf waarde creëren voor klanten.
Op basis hiervan kun je achterhalen hoe deze primaire en ondersteunende activiteiten aan elkaar gelinkt zijn. Zo kun je bepalen wat het effect is van de gecreëerde waarde en welke kosten hieraan verbonden zijn. Hiermee bepaal je de marge van een organisatie.
Volgens het Vijfkrachtenmodel (Five Forces Framework) van Porter wordt de concurrentie bepaald door de sterkte van de volgende vijf krachten in te schatten:
Het Vijfkrachtenmodel(Five Forces Framework) van Michael Porter kan een goed beeld geven van de concurrentie in een bepaalde bedrijfstak.
De winstgevendheid van een bedrijf of organisatie is sterk afhankelijk van de concurrentie, dus het is van belang om de concurrenten goed te analyseren als je een strategie opstelt. Het Vijfkrachtenmodel kan hierbij helpen.
De piramide van Maslow kan worden gebruikt om de behoeften van consumenten of mensen in het algemeen te verklaren. De theorie stoelt op de aanname dat mensen basisbehoeften hebben en dat andere, meer verfijnde behoeften pas ontstaan als eerdere behoeftelagen vervuld zijn.
Primaire biologische levensbehoeften. Dit zijn de eerste basisbehoeften, zoals zuurstof, voedsel en water.
Bestaanszekerheid. Als de primaire biologische levensbehoeften vervuld zijn, gaan mensen op zoek naar veiligheid en zekerheid (zoals onderdak).
Sociale behoeften. Als iemand bestaanszekerheid ervaart, is de volgende stap een sociaal leven ontwikkelen (zoals vriendschappen of andere relaties opbouwen).
Erkenning. Als mensen eenmaal sociaal contact hebben, vinden ze het belangrijk hoe anderen over ze denken in termen van waardering, erkenning en respect.
Zelfontplooiing. Zijn alle bovenstaande behoeften vervuld? Dan wil dat zeggen dat die mensen voldoende tijd (en geld) hebben om zichzelf te ontwikkelen als mens (bijvoorbeeld door een studie te volgen).
In de BCG-matrix worden de marktgroei en het marktaandeel van bepaalde producten of diensten van een bedrijf met elkaar vergeleken. Zo kunnen bedrijven bepalen in welke producten en diensten ze moeten investeren, in welke ze moeten des-investeren en welke producten of diensten ze zelfs niet meer aan moeten bieden.
Het doel van de Balanced Scorecard is om de missie en visie van een bedrijf of organisatie te communiceren. De Scorecard kan zo als hulpmiddel dienen om een strategie te ontwikkelen. Om de effectiviteit van deze strategie te controleren, worden meetbare indicatoren gebruikt.
De marketingmix bestaat uit verschillende instrumenten die samen de marketingstrategie van een bedrijf vormen. Eerst waren er 4 p’s, namelijk product, prijs, promotie en plaats.
Booms en Bitner hebben hier nog personeel, proces en physical evidence, waardoor er nu 7 p’s zijn.
Politiek-juridische factoren tonen aan in welke mate de overheid invloed heeft op de economie. De overheid kan grote invloed hebben op prijzen, de inkomstenverdeling, economische groei, arbeidsmarkt, de gezondheidszorg, onderwijs en infrastructuur van een land.
Ecologische factoren hebben betrekking op de fysieke omgeving van het bedrijf die een kans of bedreiging kunnen vormen. Zo moet een bedrijf rekening houden met geldende milieuvoorschriften, natuurlijke bronnen en weersomstandigheden van een gebied of land bij het aanbieden van producten of diensten en de productieprocessen.
Een bedrijf moet op de hoogte zijn van technologische factoren, zodat het hierop kan inspelen voordat concurrenten dit doen. Ook is het van belang inzicht te hebben in deze ontwikkelingen, om te bepalen of een product of dienst wel kan worden gecreëerd.
Sociaal-culturele factoren gaan over de sociale en culturele normen en waarden van een gebied of land. Met behulp van deze factoren kunnen de kenmerken van (potentiële) consumenten worden geïnventariseerd. Als je de potentiële klanten in kaart brengt, kun je inschatten hoe groot hun vraag zal zijn naar de producten en diensten van de organisatie.
Met economische factoren kun je de economische gesteldheid van een land of bepaald gebied in kaart brengen. Hierbij is het belangrijk om te kijken naar trends, oftewel of er op basis van voorgaande maanden of jaren sprake is van groei of niet.
Demografische factoren gaan over ontwikkelingen in de bevolkingssamenstelling, -groei en -omvang binnen de markt waarin het bedrijf zich bevindt. Hiermee krijg je inzicht in de potentie van de markt, de grootte van de potentiële doelgroep en de ontwikkelingen die als kans en bedreiging kunnen worden beschouwd.
Met de DESTEP-analyse kun je de macro-omgeving van een bedrijf in kaart brengen om inzicht te krijgen in belangrijke marktontwikkelingen. Zo kun je kansen en bedreigingen voor je opdrachtgever inzichtelijk maken.
Je richt je op demografische, economische, sociaal-culturele, technologische, ecologische en politiek-juridische factoren.
In een confrontatiematrix verbind je de zwakten, sterkten, bedreigingen en kansen van de SWOT-analyse door deze tegenover elkaar te zetten. Hierbij geldt:
De sterke punten en de kansen creëren samen groeimogelijkheden.
De zwakten en de kansen bieden ruimte voor verbetering.
De sterkten kunnen het bedrijf of de organisatie verdedigen tegen bedreigingen.
De zwakke punten en bedreigingen leiden tot verandering of terugtrekking.
De confrontatiematrix is vaak een handig hulpmiddel om een marketingplan op te stellen. De matrix verbindt de zwakten, sterkten, bedreigingen en kansen van de SWOT-analyse, waardoor je conclusies kunt trekken.
Met een SWOT-analyse kun je de sterktes, zwaktes, kansen en bedreigingen van een bepaalde situatie onderzoeken, zoals de verkoopmarkt van mobiele telefoons. Op die manier kun je bepalen welke aspecten goed gaan en welke punten nog meer aandacht verdienen.
De SWOT-analyse heeft betrekking op de sterktes (strengths), zwaktes (weaknesses), kansen (opportunities) en bedreigingen (threats) van een bepaalde situatie or organisatie.
Strengths zijn de interne positieve punten en weaknesses de interne negatieve punten. Deze twee aspecten van de SWOT-analyse vormen samen de interne analyse.
Opportunities zijn de externe positieve punten en threats de externe negatieve punten. Deze twee aspecten van de SWOT-analyse vormen samen de externe analyse.
Je kunt sociale media als bron in je onderzoek gebruiken om te kijken wat gezegd wordt over een bepaald onderwerp. Met Twitter zou bijvoorbeeld onderzocht kunnen worden hoeveel klachten er dagelijks binnenkomen over de NS. De meeste reizigers dienen namelijk geen officiële klacht in, maar uiten wel hun frustratie op Twitter.
Het Hawthorne-effect kan een probleem vormen bij observatie-onderzoek.
Als mensen weten dat ze geobserveerd worden, kunnen zij (onbewust) hun gedrag veranderen of verbeteren. De uitkomsten van het onderzoek kunnen hierdoor vertekend raken, omdat de participanten zich anders zouden gedragen als ze niet zouden weten dat ze geobserveerd worden.
Je gebruikt de functie “wijzigingen bijhouden” (track changes) in Word, zodat eventuele wijzigingen zichtbaar blijven als suggesties, en niet direct worden doorgevoerd. Op deze manier kan iemand anders bepalen of een wijziging moet worden doorgevoerd of kan iemand zien welke aanpassingen je hebt gedaan.
Deze functie is bijvoorbeeld handig als je feedback geeft op iemands anders’ werk of als je met meerdere mensen aan een project werkt.
Je kunt enkele technieken gebruiken om teksten sneller te lezen dan normaal.
Lees de tekst niet in gedachten voor
Iets wat we allemaal (vaak onbewust) doen is een tekst hardop of in gedachten voorlezen, maar dit vertraagt de leessnelheid enorm. Lees alleen hardop of in gedachten voor als je een stukje niet goed begrijpt.
Gebruik een aanwijzer om je ogen te begeleiden
Maak gebruik van een pen, potlood, vinger of muisaanwijzer als hulpmiddel om je ogen te begeleiden door de tekst. Je zult merken dat je een tekst veel sneller leest, omdat je niet hoeft te zoeken.
Het aantal woorden in een scriptie hangt af van het niveau, het aantal studiepunten dat je krijgt en de richtlijnen van individuele opleidingen (controleer deze goed).
Een hbo-scriptie is gemiddeld 15.000 woorden lang, een bachelorscriptie heeft tussen de 7.000 en 12.000 woorden en een masterscriptie is meestal tussen de 12.000 en 20.000 woorden lang (zonder bijlagen).
Let op: een grote scriptie is niet per se beter dan een kleine scriptie. Het belangrijkste is om kort en krachtig te schrijven, zodat je scriptie goed leesbaar is.
De studielast voor een vak of opleiding wordt uitgedrukt in studiepunten (ECTS of credits). Hierdoor kunnen vakken met elkaar worden vergeleken en weten studenten en docenten hoeveel tijd ze ongeveer kwijt zijn aan de voorbereiding, de colleges en de opdrachten.
Zo staat 1 ECTS voor 28 uur werk. Stel dat je 12 studiepunten krijgt voor je scriptie, dan rekent je opleiding op minimaal 8 weken fulltime werk (of 336 uur).
De gemiddelde duur van een scriptie ligt tussen de 3 en 12 maanden, waarbij je meestal 6 maanden bezig bent (ongeveer 1 semester). Hoe lang het proces precies duurt, hangt af van het soort onderzoek en hoeveel studiepunten ervoor staan. Het allerbelangrijkste is dat je je houdt aan een goede planning.
Een afstudeerpresentatie waarin je uitlegt hoe je onderzoek is verlopen en wat de resultaten zijn. Meestal mag je hiervoor een scherm gebruiken, zodat je een PowerPoint kunt laten zien.
Een kritische vragenronde waarbij het publiek vragen kan stellen. De meeste vragen zullen afkomstig zijn van je begeleider en tweede lezer, waardoor ze mogelijk een klein deel van het cijfer bepalen.
De bepaling van het cijfer. De begeleider en tweede lezer trekken zich even terug, waarna ze het cijfer bekendmaken.
De verdediging vormt maar een klein onderdeel van het scriptieproces en is vaak niet van grote invloed op het cijfer.
Wie aanwezig is bij je scriptieverdediging, hangt af van je opleiding en onderwijsinstelling. Je vaste begeleider en een tweede lezer zijn er altijd bij.
Op de universiteit is het bij sommige opleidingen ook gebruikelijk dat er publiek aanwezig is. Het publiek kun je zelf uitnodigen. Denk hierbij aan familie, vrienden, collega’s (van je stagebedrijf), studiegenoten, et cetera.
In de meeste gevallen biedt de onderwijsinstelling richtlijnen voor de opmaak, of moet je je bijvoorbeeld aan de APA-stijl opmaakrichtlijnen houden. Enkele algemene adviezen zijn:
Gebruik een duidelijk en zakelijk lettertype. Enkele voorbeelden zijn Verdana, Times New Roman en Arial.
Gebruik lettergrootte 11 (en soms 10 voor tabellen en figuren).
In wetenschappelijke artikelen en scripties wordt vaak regelafstand 1,15, 1,5 of zelfs 2,0 gebruikt. Dit maakt de tekst beter leesbaar en zo kan je begeleider eenvoudig opmerkingen tussen de regels plaatsen.
Het is ontzettend vervelend als je scriptie wordt afgekeurd. Probeer ondanks de teleurstelling toch proactief in overleg te gaan met je begeleider. Stel je begeleider de volgende vragen:
Waarom moet ik mijn scriptie herkansen?
Kunt u mij aangeven wat de verbeterpunten zijn?
Kunnen we een nieuwe deadline plannen voor het inleveren van mijn scriptie?
Zorg dat de afspraken schriftelijk bevestigd worden, bijvoorbeeld door in een mail om bevestiging te vragen. Vervolgens kun je aan de slag met een nieuwe planning.
In dezestartfase van je tijdsplanning verzamel je informatie en bepaal je je onderwerp. Lees veel onderzoeken om het onderwerp te leren kennen en te begrijpen wat al onderzocht is. Je begint breed en maakt het onderwerp steeds specifieker, zodat je onderzoek haalbaar is.
Hoe hoger de kwaliteit van de artikelen die je gebruikt in het literatuuronderzoek, hoe steviger jouw eigen onderzoek staat. Als je artikelen gebruikt die laag staan aangeschreven, loop je het risico dat de conclusies die je trekt ongefundeerd zijn. Je begeleider zal dan ook altijd controleren op basis van welke artikelen je bepaalde conclusies trekt.
De tekst wordt links uitgelijnd en verschijnt op alle pagina’s, inclusief de titelpagina. Het is niet nodig om het label “Running head” toe te voegen voor de titel (zoals dat wel moest voor de 6de editie van APA).
Je voegt in principe alleen een running head toe bij officiële publicaties, en niet als je student bent (tenzij instructies anders voorschrijven).
Een “running head” is een verkorte versie van de titel van je tekst. Deze wordt in de paginakoptekst van je document geplaatst, samen met een paginanummer. De running head is alleen nodig voor professionele manuscripten die bedoeld zijn voor publicaties en niet voor teksten van studenten (tenzij instructies anders voorschrijven).
De datumnotatie voor de APA-stijl in het Nederlands verschilt ten opzichte van het Engels. In het Nederlands schrijf je de maanden zonder hoofdletter en begin je met de dag van de maand. In het Engels is dit precies andersom.
Nederlands Streefkerk, R. (2019, 22 oktober). APA-handboek 7e druk: De belangrijkste wijzigingen. Geraadpleegd op 6 april 2021, van https://www.scribbr.nl/apa-stijl/wijzigingen-7e-druk.
Engels Streefkerk, R. (2010, October 22). APA-handboek 7e druk: De belangrijkste wijzigingen. Retrieved October 22, 2021, from https://www.scribbr.nl/apa-stijl/wijzigingen-7e-druk
Shi, F., & Zhu, L. (2019). Analysis of trip generation rates in residential commuting based on mobile phone signaling data. Journal of Transport and Land Use, 12(1), 201–220. Geraadpleegd op 12 maart 2021, van https://www.jstor.org/stable/26911264
Noot. Overgenomen uit “Analysis of Trip Generation Rates in Residential Commuting Based on Mobile Phone Signaling Data”, door F. Shi en L. Zhu, 2019, Journal of Transport and Land Use, 12(1), p. 212 (https://www.jstor.org/stable/26911264). CC BY-NC.
Je kunt gebruikmaken van onze APA Bronnengenerator om automatisch foutloze bronvermeldingen te genereren.
Als je de APA-stijl gebruikt voor de opmaak, kun je deze richtlijnen volgen voor de informatie op titelpagina (ook wel titelblad, voorpagina of omslag genoemd):
Titel van je tekst.
Je naam (en eventueel namen van andere auteurs).
Naam van je hogeschool of universiteit (en eventueel de faculteit).
Naam van je vak (en eventueel vakcode).
Naam van je begeleider(s).
Inleverdatum van je opdracht.
Alle tekst met dubbele regelafstand en gecentreerd.
Een inhoudsopgave is volgens de APA-richtlijnen niet verplicht. Er zijn dan ook geen specifieke APA-opmaakrichtlijnen voor dit onderdeel. Toch is het zeker in lange teksten verstandig om een inhoudsopgave toe te voegen. Voor wat houvast kun je hierbij deze opmaakrichtlijnen volgen:
Voeg alle koppen met niveau 1 en 2 toe (andere niveaus zijn optioneel).
Geef de niveauverschillen tussen koppen aan met inspringing. Houd je aan de algemene APA-opmaakrichtlijnen voor het lettertype, regelafstand, en dergelijke.
Je introduceert afkortingen volgens de APA-stijl door eerst de volledige term te noemen en vervolgens de afkorting tussen haakjes te plaatsen. Vanaf dat moment gebruik je alleen nog de afkorting.
Het beheersen van Kwaliteit, Arbo en Milieu (KAM) is voor veel organisaties moeilijk. KAM krijgt vaak te weinig aandacht.
Homoscedasticiteit houdt in dat de variantie van een variabele gelijk is voor meerdere groepen of dat de variantie van de foutterm gelijk is.
Bij het uitvoeren van een t-toets of ANOVA, analyseer je de variantie tussen de meerdere groepen. Dit kan getoetst kan worden met Levene’s test.
Bij regressie moet de variantie van de foutterm gelijk zijn voor alle waarden van de verklarende variabele. Er mag dus niet meer of minder spreiding in de foutterm zijn voor grotere of lagere waarden van de verklarende variabele.
Als er een sterk lineair verband is tussen verklarende variabelen, spreek je van multicollineariteit.
Multicollineariteit kan ertoe leiden dat de regressiecoëfficiënten in je regressiemodel slechter worden geschat. De verklarende variabelen voorspellen elkaar dan en daardoor wordt er geen extra variantie verklaard in het regressiemodel.
Voorbeeld:
Je voegt zowel lengte in centimeters als lengte in inches toe als verklarende variabelen aan je regressievergelijking. Deze twee variabelen voorspellen elkaar, aangezien lengte in centimeters 2,54 maal de lengte in inches is, en zijn dus perfect lineair gecorreleerd. Er kunnen dan geen twee regressiecoëfficiënten worden berekend.
Bij het uitvoeren van een lineaire regressie is het belangrijk dat het verband tussen de verklarende variabele en de afhankelijke variabele lineair is. Dit betekent dat voor zowel lage als hoge waarden van de verklarende variabele de invloed gelijk is.
Voorbeeld:
De verklarende variabele lengte beïnvloedt de afhankelijke variabele gewicht. Een lineair verband betekent dat het gewicht net zoveel toeneemt als iemand van 150 cm naar 160 cm lengte groeit als van 180 cm naar 190 cm.
In het Nederlands gebruik je komma’s als decimaalteken, terwijl je in het Engels een punt gebruikt.
Nederlands: De appels kosten maar €5,12.
Engels: The apples only cost €5.12.
Voor duizendtallen gebruik je in het Nederlands punten, terwijl je in het Engels een komma gebruikt.
Nederlands: De koptelefoon kost €1.600.
Engels: The headphones cost €1,600.
Als je statistische resultaten rapporteert, is het wel gebruikelijk om ook in het Nederlands een punt als decimaalteken te gebruiken. Dit is zeker het geval als je de APA-stijl gebruikt.
Gebruik spaties, dus a + b = c in plaats van a+b=c
Sluit vergelijkingen af met een punt
Cursiveer de variabelen (in dit geval a, b en c)
Gebruik haakjes om de volgorde van bewerkingen aan te geven, bijvoorbeeld: (a / b) + c in plaats van a / b + c
Vergelijkingen mogen in de tekst worden geplaatst, maar gecentreerd op een aparte regel heeft de voorkeur. Nummer deze vergelijkingen, zodat je ernaar kunt verwijzen. Dit nummer is altijd rechts uitgelijnd.
Vervolgens selecteer je de vragen waarvan je de interne consistentie wilt meten.
Zorg er daarna voor dat “Alpha” geselecteerd is. Klik vervolgens op “Statistics” en vink “Scale if item deleted” aan. Alles staat nu goed: klik nu op “Continue” en “ok” om de analyse uit te voeren.
Hoewel SPSS Cronbach’s alpha voor je kan berekenen, kan het soms ook handig zijn om zelf de formule te kennen. Stel dat n (vragen) samen de score klanttevredenheid Y geven, dan is Cronbach’s alpha:
Hierbij staat s2(Xi) voor de steekproefvariantie van vraag i, en s2(Y) voor de steekproefvariantie van de totale score.
Je rapporteert Cronbach’s alpha meestal in de methodologie om aan te tonen dat je gebruikte vragenlijst betrouwbaar is. Je vermeldt het aantal items in je vragenlijst en de bijbehorende Cronbach’s alpha. Dit kun je op de volgende manier doen:
De klanttevredenheidsschaal is betrouwbaar, Cronbach’s alpha voor de drie items is .850.
De schaal voor klanttevredenheid is betrouwbaar (3 items; ⍺ = .850).
Als je variabeleniet normaal verdeeld is, kun je kijken of je de data kunt transformeren. Het kan namelijk zijn dat een variabele zelf niet normaal verdeeld is, maar het logaritme of het kwadraat wel.
Als ook dit niet het geval is, kun je niet-parametrische toetsen gebruiken, zoals de Wilcoxon- of Mann-Whitney-toets, in plaats van de t-toets.
Binnen één standaarddeviatie ligt 68,2% van de observaties (34,1% + 34,1%), binnen twee standaarddeviaties 95,2% en binnen drie standaarddeviaties 99,6%.
Veel statistische toetsen, zoals een t-toets of ANOVA, kunnen alleen geldige resultaten opleveren als sprake is van een normale verdeling. Als je data scheef verdeeld zijn, kan het voorkomen dat je resultaten niet valide zijn.
De aanname van een normale verdeling is vooral belangrijk bij steekproeven kleiner dan 30 observaties. Als je steekproef meer dan 30 observaties bevat, dan kun je volgens de centrale limietstelling (central limit theorem) aannemen dat aan de aanname van normaliteit wordt voldaan.
De standaarddeviatie (standard deviationof s) is de gemiddelde hoeveelheid variabiliteit in je dataset. Deze maat vertelt je hoe ver iedere score gemiddeld van het gemiddelde verwijderd is. Des te groter de standaarddeviatie, des te meer variabel je dataset is.
Regressieanalyses worden gebruikt om het effect te bepalen van een (of meerdere) verklarende variabele(n), zoals lengte of leeftijd, op een afhankelijke variabele zoals gewicht.
Je kunt regressieanalyse gebruiken om:
Samenhang tussen twee variabelen te bepalen (leeftijd en waarde van een auto)
Verandering van de afhankelijke variabele te voorspellen (waarde van een auto naarmate deze ouder wordt)
Toekomstige waarde te voorspellen (waarde van een zes jaar oude auto)
Voorbeeld: Je meet de gemiddelde lengte van respondenten in 2008, 2013, en 2018. Je vergelijkt dan de gemiddelde lengte van dezelfde persoon over een bepaalde periode om te kijken of deze verandert.
Je gebruikt een multivariate ANOVA (ook wel MANOVA) als je meerdere afhankelijke variabelen gebruikt. Je kunt deze ANOVA zowel gebruiken met één als meerdere groepsvariabelen (onafhankelijke variabelen).
Voorbeeld: Je wilt niet alleen niet alleen de gemiddelde lengte, maar ook het gemiddelde gewicht van verschillende groepen sporters vergelijken.
Je kunt beter een MANOVA uitvoeren dan meerdere losse ANOVA’s, om het risico op een Type I-fout te voorkomen.
Je gebruikt een two-way-ANOVA (ook wel factorial ANOVA) als je twee of meer groepsvariabelen (onafhankelijke variabelen) in je conceptueel model hebt.
Voorbeeld: Je vergelijkt de gemiddelde lengte van verschillende typen sporters én hun gender. Er wordt dan niet alleen getest of het gemiddelde verschilt voor volleyballers en turners en voetballers, maar ook voor mannen, vrouwen en mensen met een ander gender, én of er eventuele interactie-effecten zijn.
Je gebruikt een one-way-ANOVA wanneer één groepsvariabele (onafhankelijke variabele) de groepen bepaalt en er maar één afhankelijke variabele is.
Voorbeeld: Je vergelijkt de gemiddelde lengte van verschillende typen sporters, zoals voetballers, turners en volleyballers. Het type sport dat iemand beoefent, is in dit geval de enige groepsvariabele en lengte is de enige afhankelijke variabele.
ANOVA staat voor Analysis of Variance, oftewel variantieanalyse, en wordt gebruikt om gemiddelden van meer dan twee groepen met elkaar te vergelijken. Het is een uitbreiding van de t-toets, die het gemiddelde van maximaal twee groepen met elkaar vergelijkt.
Je gebruikt een gepaarde t-test (paired samples t-test) om twee gemiddelden van gepaarde steekproeven met elkaar te vergelijken. Gepaarde steekproeven zijn afhankelijk van elkaar.
Voorbeeld: Paired samples t-testJe meet de lengte van dezelfde personen in 2015 en 2018. Deze waarden zijn afhankelijk van elkaar (omdat je dezelfde persoon meet), en daarom gebruik je een paired samples t-test.
De onafhankelijke t-test (ook wel independent samples t-test of ongepaarde t-test genoemd) gebruik je om te onderzoeken of twee steekproefgemiddelden significant van elkaar verschillen.
Voorbeeld: Independent samples t-testJe wilt weten of de gemiddelde sprintsnelheid van kinderen uit groep 7 afwijkt van die van kinderen uit groep 8.
Je gebruikt de one sample t-test om te analyseren of het gemiddelde van een steekproef significant verschilt van een bepaalde waarde.
Voorbeeld: One sample t-testJe wilt controleren of chocoladerepen daadwerkelijk gemiddeld 300 gram wegen, zoals op de verpakking wordt vermeld. Om dit te onderzoeken weeg je 40 repen en vergelijk je het echte gewicht met wat het zou moeten zijn (300 gram). Hiervoor gebruik je de one sample t-test.
De t-test, ook wel t-toets genoemd, wordt gebruikt om de gemiddelden van maximaal twee groepen met elkaar te vergelijken. Je kunt de t-test bijvoorbeeld gebruiken om te analyseren of moedertaalsprekers gemiddeld sneller spreken dan niet-moedertaalsprekers.
Als je meer dan twee groepen wilt vergelijken, moet je een andere toets gebruiken, zoals de ANOVA.
De p-waarde (p-value) is een getal tussen 0 en 1, waarmee je bepaalt of een steekproefuitkomst statistisch significant is. Wanneer de p-waarde kleiner is dan het gekozen significantieniveau kun je stellen dat dat de gevonden uitkomst extreem genoeg is om je nulhypothese te verwerpen.
SPSS staat oorspronkelijk voor Statistical Package for the Social Sciences. Het is een statistisch computerprogramma ontwikkeld voor de sociale wetenschappen, maar wordt tegenwoordig ook veel gebruikt binnen andere sectoren zoals de economische wetenschappen.
SPSS helpt je bij het verzamelen, invoeren, lezen, bewerken en/of analyseren van gegevens, maar ook bij het verspreiden van de resultaten en het nemen van beslissingen.
Bronvermelding in de literatuurlijst
In de literatuurlijst wordt voor iedere bron een volledige bronvermelding opgenomen. Elke bronvermelding kan uit negen elementen bestaan. Voor ieder brontype gebruik je alleen de relevante elementen.
Verwijzing in de tekst
Dit zijn korte verwijzingen in de tekst die de lezer helpen de volledige bronvermelding in de literatuurlijst te vinden. Alleen de achternaam van de auteur en het paginanummer worden gebruikt, bijvoorbeeld (Smith 205).
Bekijk ons uitgebreide artikel over de MLA-stijl voor meer uitleg en voorbeelden.
Over het algemeen gebruiken de meeste onderwijsinstellingen in Nederland de APA-stijl, met uitzondering van juridische opleidingen en medische opleidingen.
De onderwijsinstelling of begeleider zou duidelijk moeten aangeven welke referentiestijl je dient te gebruiken. Als je de informatie nergens kunt vinden, is het belangrijk om eerst na te vragen welke stijl je moet gebruiken, omdat ze erg van elkaar verschillen.
De populairste referentiestijl in Nederland is de APA-stijl. Wij hebben hiervoor een gratis te downloaden, Nederlandstalige handleiding met uitleg, formats en voorbeelden gemaakt.
Een uitzondering hierop wordt gevormd door de juridische opleidingen. Juridische opleidingen in Nederland maken gebruik van de Leidraad voor juridische auteurs.
Een referentiestijl is een verzameling van regels die voorschrijven op welke manier je naar bronnen moet verwijzen in je scriptie. Een referentiestijl wordt vaak gepubliceerd in een officieel handboek met daarin uitleg, voorbeelden en adviezen.
Wij raden aan om voor je argumentatie vooral artikelen uit wetenschappelijke tijdschriften te gebruiken. Mocht je geen of weinig artikelen over jouw onderwerp kunnen vinden in wetenschappelijke tijdschriften, dan kun je eventueel ook bronnen raadplegen die niet wetenschappelijk van aard zijn, maar die wel betrouwbaar zijn. Een goed voorbeeld hiervan is een rapport of een handboek.
Als je de actualiteit van je onderwerp of de aanleiding van je onderzoek wilt onderbouwen, is de wetenschappelijke achtergrond van een bron minder van belang. Hiervoor kun je dus ook prima nieuwsartikelen gebruiken.
Als je niet zelf een experiment uitvoert of de primaire gegevens verzamelt, kun je het best primaire bronnen opsporen via secundaire bronnen. Meestal is het vrij eenvoudig te achterhalen op welke primaire bron een secundaire bron is gebaseerd.
Deze informatie vind je op twee belangrijke plaatsen in de secundaire bron:
Een secundaire bron interpreteert, analyseert of verklaart primaire bronnen. Deze bronnen zijn een stap verwijderd van de oorspronkelijke gebeurtenis en zijn daarom niet altijd even relevant als de originele bron.
Primaire bronnen zijn het oorspronkelijke bewijs van gebeurtenissen, objecten, personen of uitgevoerd werk. Voorbeelden hiervan zijn:
Onderzoeksresultaten
Statistische gegevens
Ooggetuigenverslagen
Enquêtes en interviews
Juridische documenten
Via primaire bronnen kunnen studenten en onderzoekers de werkelijke gebeurtenis zo dicht mogelijk benaderen. De informatie in primaire bronnen is nog niet geanalyseerd, samengevat of geïnterpreteerd door iemand buiten het onderzoek. Dit geeft je de mogelijkheid om dit zelf te doen.
Lees de passage goed door, zodat je deze volledig begrijpt.
Stap 2
Noteer de belangrijkste begrippen.
Stap 3
Schrijf jouw versie van de tekst zonder naar het origineel te kijken (zie onderstaande tips als je bij deze stap vastloopt).
Stap 4
Vergelijk je eigen versie van de tekst met de oorspronkelijke versie. Let daarbij op gedeelten die nog te veel in dezelfde woorden staan.
Stap 5
Maak kleine aanpassingen waar nodig. Soms lukt het niet om alle zinnen te wijzigen.
Stap 6
Noteer de bron waaruit de passage afkomstig is, inclusief alle informatie die je nodig hebt voor een juiste bronvermelding (auteursnaam, titel boek, tijdschrift of artikel, publicatiejaar, et cetera.
Om snel & eenvoudig je tekst te herschrijven, je zinsstructuur te verbeteren en handige synoniemen te vinden, kun je ook gebruikmaken van Scribbrs gratis Parafraseertool.
De definitie van parafraseren is andermans idee in je eigen woorden uitdrukken. Het doel is de betekenis van de oorspronkelijke tekst behouden zonder de tekst woordelijk te kopiëren (citeren). Je kunt een tekst zelf herschrijven of je kunt de tekst laten herschrijven door een tool van Scribbr.
Hierdoor blijft je eigen stem dominant en laat je zien dat je de inhoud hebt begrepen. Je parafraseert vaker dan dat je citeert.
Als je parafraseert, druk je een idee van iemand anders uit in je eigen woorden. Parafraseren is de belangrijkste manier om onderzoeken van anderen te delen die relevant zijn voor je eigen onderzoek.
Naast parafraseren zijn er nog twee manieren om de ideeën van anderen te delen: citeren en samenvatten.
Er zijn verschillende online paraphrasing tools beschikbaar om je te helpen parafraseren en je tekst vloeiender te maken (zoals Scribbrs gratis Parafraseertool). Zo kun je een betere schrijver worden. Je kunt onze analyse van de beste paraphrasing tool (Engelstalig) en de beste parafraseringstool (Nederlandstalig) bekijken voor meer informatie.
Citeren is het letterlijk kopiëren van andermans woorden. Dit kan een zinsdeel, een zin of een alinea zijn. Hierbij is het belangrijk dat je de geciteerde tekst tussen aanhalingstekens plaatst en dat je correct verwijst naar de originele auteur(s) in de tekst en in de literatuurlijst.
Een samenvatting van een bron is een beknopt, maar volledig overzicht van de inhoud van een bron, geschreven in je eigen woorden. Een samenvatting is veel korter dan de tekst waaruit de informatie is overgenomen.
Een samenvatting is een volledige of gedeeltelijke beschrijving van een bron. Dit is iets anders dan parafraseren. Dat houdt namelijk in dat je slechts een gedeelte van een tekst in je eigen woorden uitlegt. Dat gedeelte heeft vaak ongeveer dezelfde lengte als de brontekst.
Tip: Je kunt gebruikmaken van tools van Scribbr om teksten te herschrijven of te samenvatten om gratis & snel een handige samenvatting te maken.
Behandel je argumenten voor je essay in een logische volgorde. Je kunt je argumenten (voor en tegen) op verschillende manieren in een logische volgorde presenteren:
Thematisch: bespreek voor- en tegenargumenten per deelthema.
Chronologisch: bespreek voor- en tegenargumenten in chronologische volgorde.
Argumentatief: bespreek eerst de argumenten voor het standpunt en daarna de argumenten tegen het standpunt.
De conclusie van jeessay eindig je met een krachtige slotzin om je lezer nog meer te overtuigen, aan het denken te zetten of aan te sporen tot actie. Je slotzin kan zijn:
Als je sentence case gebruikt voor Engelse kopjes en titels, krijgen alleen het eerste woord van de (sub)titel en namen een hoofdletter. Alle andere woorden worden met een kleine letter geschreven, in tegenstelling tot bij title case.
Als je title case gebruikt voor Engelse titels en kopjes, krijgen het eerste woord en alle belangrijke (kern)woorden een hoofdletter. Je gebruikt alleen een kleine letter voor de onbelangrijke woorden, zoals lidwoorden en voorzetsels (tenzij ze het eerste woord van de titel vormen).
Als je het woordje “enkele” gebruikt, is meestal sprake van vaag taalgebruik.
Het is belangrijk om zo weinig mogelijk ruimte over te laten voor een kritische lezer om te vragen: “Hoeveel respondenten waren dat? Over welke respondenten gaat het?”. In plaats van “enkele” kun je altijd beter het precieze aantal noemen.
In academische teksten moet je zo precies mogelijk schrijven zodat de tekst wetenschappelijk, objectief en duidelijk is en niet op meerdere manieren geïnterpreteerd kan worden. Andere onderzoekers moeten op basis van jouw verslaglegging een onderzoek kunnen repliceren.
Leer daarom vaag taalgebruik herkennen en schrap het wanneer je het tegenkomt.
Het is beter om geen spreekwoorden en gezegden te gebruiken in een scriptie of andere academische tekst, omdat deze vaak onder spreektaal vallen. Een uitzondering hierop is het voorwoord, dat wat persoonlijker van aard is.
Getallen onder de twintig, tientallen tot honderd, honderdtallen tot duizend en duizendtallen tot en met twaalfduizend worden in de meeste gevallen uitgeschreven. Hetzelfde geldt voor de woorden ‘miljoen’, ‘miljard’ en de bijbehorende rangtelwoorden (miljoenste, miljardste).
Andere getallen worden in principe in cijfers weergegeven.
Exacte waarden en symbolen, percentages en de nummers van hoofdstukken, paragrafen en figuren worden ook in cijfers weergegeven.
Het algemeen gebruik van het woord “je” kun je het beste vermijden, net als het gebruik van “men”. Dat doe je door te noemen naar wie of wat hiermee verwezen wordt.
Het gebruik van men wordt vaak gezien als spreektaal, en kan zorgen voor verwarring (want wie is “men”?).
Soms is dat lastig, bijvoorbeeld als niet bekend of relevant is naar wie “je” of “men” verwijst. Dan is het gebruik van deze woorden niet verboden, maar wel af te raden.
Een handige manier om de ik-vorm te voorkomen, is de lijdende vorm gebruiken. Een overdaad aan de lijdende vorm kan teksten echter minder goed leesbaar maken, dus probeer te variëren tussen de lijdende en actieve vorm.
In de actieve vorm wordt het onderwerp van de zin genoemd; in de lijdende vorm wordt dat juist achterwege gelaten.
Afkortingen voor woorden en uitdrukkingen, zoals enz. en n.a.v., mag je niet gebruiken in een scriptie. In plaats daarvan gebruik je het volledige woord of de gehele woordgroep.
Afkortingen voor zelfstandig naamwoorden en namen mag je wel gebruiken, en deze hoef je niet te introduceren als ze algemeen bekend zijn.
Mocht je twijfelen of je lezerspubliek de afkorting kent, introduceer deze dan voor de zekerheid.
Je introduceert afkortingen door eerst de volledige term te noemen en vervolgens de afkorting tussen haakjes te plaatsen. Vanaf dat moment gebruik je alleen nog de afkorting.
Het beheersen van Kwaliteit, Arbo en Milieu (KAM) is voor veel organisaties moeilijk. KAM krijgt vaak te weinig aandacht.
In de resultatensectie presenteer je je bevindingen op basis van je onderzoek. Dit zijn voornamelijk feiten. Je gebruikt dan de onvoltooid tegenwoordige tijd. Je doet dit ook als je conclusies trekt of je conclusies bediscussieert.
Je gebruikt de voltooid tegenwoordige tijd als je verwijst naar het onderzoek dat je gedaan hebt en wanneer je schrijft over afgeronde zaken.
In je methodologie ga je in op de manier waarop je zelf onderzoek doet en hoe je dit aanpakt en/of aangepakt hebt. Het is sterk afhankelijk van je begeleider of je de methoden voornamelijk in de onvoltooid of voltooid tegenwoordige tijd schrijft.
Wij raden aan om de methoden in de voltooid tegenwoordige tijd te schrijven. Je hebt je onderzoek immers al gedaan op het moment van schrijven. Gebruik in ieder geval niet de toekomende tijd; deze werkwoordstijd mag je alleen gebruiken voor iets dat in de toekomst zal plaatsvinden.
Je kunt op verschillende manier achterhalen wat de missie en visie van je opdrachtgever zijn. Vaak worden de missie en visie van een bedrijf simpelweg op de website beschreven. Mocht dit niet zo zijn, dan kun je jouw opdrachtgever vragen wat de missie en visie zijn.
De missie beschrijft de identiteit van een organisatie en wat deze in de huidige situatie wil bereiken. De visie daarentegen gaat in op het ideaalbeeld van de organisatie voor de toekomst (wat de organisatie op de lange termijn wil bereiken).
Het model van Korthagen is een methode die je kunt gebruiken in je reflectieverslag om te reflecteren op je handelen. Het reflectiemodel van Korthagen bestaat uit 5 stappen:
Je ervaart een betekenisvolle situatie.
Je blikt hierop terug (de reflectie).
Je begrijpt de meest belangrijke kenmerken van de ervaring.
Je bedenkt wat anders zou kunnen in het vervolg; alternatieven.
Je probeert deze alternatieven uit in de praktijk.
De meestgebruikte methode om te reflecteren op je eigen handelen, bijvoorbeeld in een reflectieverslag, is de STARR-methode. STARR staat voor situatie, taak, actie, resultaat en reflectie.
Zelf je uren inplannen. Je kunt zelf bepalen wanneer je werkt. Heb je een tentamenweek of een feestje, dan kun je zelf bepalen dat je vrij bent. Als je tentamenweek is afgelopen, kun je weer meer werk oppakken.
Meer loon. Als freelancer verdien je vaak meer dan in loondienst. Je bepaalt zelf je uurloon. Als je echt heel goed bent in wat je doet, kun je veel verdienen.
Flexibiliteit. Je kunt zelf bepalen waar en voor wie je werkt. Afhankelijk wat het werk, kun je werken vanuit huis, vanuit een kantoor of onderweg.
Een afstudeerstage is het moment waarop je je theoretische kennis van de studie in de praktijk brengt. Je gaat aan het werk als stagiair bij een bedrijf en voert een afstudeeropdracht uit.
Bij hbo-studies vormen afstudeerstages bijna altijd een verplicht onderdeel van het laatste jaar, terwijl je bij wo-studies minder vaak een stage loopt. De meeste afstudeerstages duren ongeveer een half jaar.
Een stage is bedoeld om je theoretische kennis in de praktijk te kunnen brengen. Zoek dus naar een stage die aansluit bij je studie. Verder is het belangrijk om een uitdagende stage te vinden die past bij je niveau, zodat je nog kunt leren en je jezelf niet gaat vervelen.
Ook is het handig om goed uit te zoeken of het bedrijf bereid is een goede leeromgeving te vormen. Dit betekent dat ze een plan moeten hebben met activiteiten die je kunt oppakken. Soms stelt de onderwijsinstelling enkele activiteiten of vaardigheden verplicht. Vraag dus goed na of ze deze begeleiding kunnen bieden.
Een thematische analyse (thematic analysis) kan inductief en deductief van aard zijn.
Een inductieve benadering houdt in dat je je thema’s laat bepalen door de data die je vindt. Daarentegen houdt een deductieve benadering in dat je tot de data komt op basis van een aantal vooraf bepaalde thema’s, waarvan je verwacht dat ze weerspiegeld worden in de data. Deze thema’s baseer je op een literatuuronderzoek naar bestaande kennis.
Een thematische analyse (thematicanalysis) kan worden gebruikt om kwalitatieve data te analyseren. De methode wordt meestal toegepast op een reeks teksten, zoals interviewtranscripten. De onderzoeker analyseert de gegevens nauwkeurig om gemeenschappelijke of overkoepelende thema’s, ideeën en patronen te identificeren.
De meeste taalkundige benaderingen focussen op de regels die ten grondslag liggen aan een taal, terwijl je bij discoursanalyse focust op de contextuele betekenis van taal.
Je let hierbij op de sociale aspecten van communicatie en de manieren waarop mensen taal gebruiken om bepaalde doelen te bereiken (zoals vertrouwen winnen, twijfel creëren, emoties opwekken en conflicten oplossen).
Daarom focus je vaak op grotere taaleenheden (zoals een heel gesprek) in plaats van op kleine taaleenheden (zoals klanken).
Discoursanalyse (discourse analysis) is een veelvoorkomende kwalitatieve onderzoeksmethode die vooral wordt gebruikt in de geesteswetenschappen en sociale wetenschappen (zoals taalkunde, antropologie en psychologie).
Discoursanalyse wordt gebruikt om geschreven of gesproken taal te onderzoeken in relatie tot de sociale context. Het doel is om te begrijpen hoe taal wordt gebruikt in het dagelijks leven.
Onderzoekers gebruiken een inhoudsanalyse (content analysis) om meer te weten te komen over het doel, de boodschap en het effect van communicatie. Ze willen ook vaak conclusies trekken over de maker van de tekst en het (beoogde) publiek.
Inhoudsanalyses kunnen worden gebruikt om de aanwezigheid van bepaalde woorden, uitdrukkingen, onderwerpen of concepten in een reeks historische of moderne teksten te kwantificeren.
Inhoudsanalyse (content analysis) is een onderzoeksmethode die wordt gebruikt om patronen in bewaarde communicatie te vinden. Een inhoudsanalyse of content-analyse bestaat uit de systematische analyse van een reeks teksten, die geschreven, gesproken of visueel kunnen zijn.
Als je interview wilt opnemen, is het belangrijk om ervoor te zorgen dat je audio-opnamen van goede kwaliteit zijn.
Kies goede opname-apparatuur. Zo kun je de audio later goed transcriberen.
Kies een rustige interviewlocatie. Probeer plekken met veel achtergrondgeluid te vermijden.
Plaats de opnameapparatuur op de goede manier. Leg de opname-apparatuur dicht bij de respondent neer, zodat diegene goed kan worden verstaan.
Test je opnameapparatuur en interviewomgeving. Neem een testinterview af om de locatie en apparatuur te testen. Het is ook verstandig om bij het echte interview eerst een testopname te maken.
Sommige vragen kun je als interviewer beter vermijden:
Lange vragen: Respondenten herinneren zich vaak maar een deel van de vraag en geven daardoor incomplete antwoorden.
Dubbelzinnige of meerledige vragen: Bijvoorbeeld, “Wat vind je van hedendaagse popmuziek in vergelijking met de popmuziek van vijf jaar geleden?”. Een oplossing is om de vraag op te splitsen in makkelijkere vragen.
Vragen met vaktermen: Over het algemeen moet je jargon in je vragen vermijden (behalve bij expert-interviews).
Sturende vragen: De vraag “Wat vind je leuk aan Amsterdam?” stuurt je respondent in een bepaalde (positieve) richting. Probeer zo neutraal mogelijke vragen te stellen. Dit verhoogt ook de validiteit van je onderzoek.
Ten eerste is het belangrijk dat je van tevoren een goed interview ontwerpt met betrouwbare en validevragen, zodat je de resultaten kunt verwerken in je scriptie.
Daarnaast is het van belang dat je ervoor zorgt dat respondenten zich vrij voelen om eerlijke antwoorden te geven.
Theoretische saturatie ontstaat als de antwoorden op interview- of enquêtevragen je geen nieuwe informatie meer opleveren. Als dit gebeurt, heb je voldoende personen geïnterviewd of geënquêteerd om valide uitspraken te kunnen doen op basis van je onderzoek.
Als je een kwalitatief onderzoek doet, moet je eerst nagaan of je onderzoek doet naar een gelijksoortige (homogene) of een ongelijksoortige (heterogene) groep personen. Het is van belang dat er of theoretische saturatie (verzadiging) optreedt of dat je in staat bent de onderzoeksvraag te beantwoorden op basis van de afgenomen interviews.
Voordat je begint aan je dataverzameling is het van belang om te bepalen hoe je je data gaat organiseren en opslaan. Dit doe je in een datamanagementplan. Als je mensen onderzoekt, moet je dit plan waarschijnlijk indienen bij een ethische toetsingscommissie.
Als je data verzamelt door mensen te onderzoeken, moet je de data waarschijnlijk anonimiseren en veilig opslaan, zodat de (gevoelige) informatie niet kan worden bekeken door anderen.
Als je data verzamelt met behulp van interviews, is het van belang om de data te transcriberen, zodat je de data zo min mogelijk interpreteert (en mogelijk vertekent).
Je kunt verlies van data voorkomen door een systeem te gebruiken waarvan regelmatig een back-up wordt gemaakt.
Operationaliseren betekent dat je abstracte, conceptuele ideeën vertaalt naar meetbare variabelen. Als je je dataverzamelingsmethode uitwerkt, moet je de conceptuele definitie (wat je wilt onderzoeken) omzetten in de operationele definitie (wat je gaat meten).
In sommige gevallen kunnen je variabelen direct worden gemeten (zoals “leeftijd”), maar het zal vaker voorkomen dat je geïnteresseerd bent in ingewikkeldere constructen of variabelen die je niet direct kunt meten of observeren (zoals “geluk”).
In het dataverzamelingsproces verzamel je op basis van je onderzoeksopzet data voor je scriptie of onderzoek om zo je onderzoeksvraag te beantwoorden. Het is van belang dat je de data op een gestructureerde, valide en betrouwbare manier verzamelt.
Hierbij denk je van tevoren na over het doel van je onderzoek, het type data dat je wilt verzamelen en de methoden en procedures die je gebruikt om data te verzamelen, op te slaan en te verwerken.
Voor de betrouwbaarheid van literatuuronderzoek is de mate van wetenschappelijkheid van je bronnen bepalend maar ook of je geen toevallige fouten maakt tijdens het zoeken, en het waarderen en het combineren van de bevindingen uit de relevante en gewaardeerde literatuur.
Willekeurige fouten worden ook wel toevallige fouten genoemd. Des te groter de kans is dat deresultatenuit je onderzoek op toeval berusten, des te lager de betrouwbaarheid van je onderzoek is.
Deze toevallige fouten kun je voorkomen door op een zorgvuldige en consistente wijze te werken en door ervoor te zorgen dat jesteekproefgroot genoeg is.
Bij validiteit gaat het om de vraag of de resultaten uit jouw scriptie wel juist zijn en of je op basis hiervan harde conclusies kunt trekken. Zo corresponderen de resultaten van een valide onderzoek met de werkelijke eigenschappen, fenomenen en variaties in de fysieke en sociale wereld.
Het gaat bij de validiteit voornamelijk om het “instrument” waarmee je onderzoek hebt gedaan.
Bij betrouwbaarheid gaat het om hoe consistent een methode iets meet. Hierbij is het van belang dat de uitkomsten hetzelfde zijn als je de meting of het gehele onderzoek op exact dezelfde wijze nog een keer uitvoert (reproduceert of repliceert).
Met een goed opgesteld onderzoeksplan, bestaande uit je onderzoeksopzet en probleemanalyse, kun je ervoor zorgen dat je onderzoeks- en analysemethoden passen bij je onderzoeksdoelen. Zo kan een begeleider beoordelen of je onderzoek goed in elkaar zit voordat je begint met het daadwerkelijke onderzoek.
Ook vormt het plan een leidraad tijdens je onderzoek.
Een onderzoeksplan is een strategie om je onderzoeksvraag te beantwoorden met behulp van empirische data. Als je een onderzoeksdesign maakt, moet je beslissingen nemen met betrekking tot:
Je kunt je hypothese(n)op verschillende manieren formuleren, maar iedere hypothese bevat ten minste:
De variabelen die je onderzoekt
De groep die je bestudeert
De verwachte uitkomst
Je formuleert eerst een hoofdvraag, waarna je oriënterend onderzoek uitvoert (vaak een literatuuronderzoek). Vervolgens formuleer je op basis van de literatuur een voorlopig antwoord.
Een hypothese is een voorlopige stelling waarin je aangeeft wat je verwacht te vinden in je onderzoek. Vervolgens test je deze hypothese met behulp van je wetenschappelijke onderzoek, zoals een experiment of correlationeel onderzoek. Je stelt de hypothese altijd op voordat je het onderzoek uitvoert.
Als je theorie standhoudt, stop je na stap 6. Als je ontkrachtend bewijs vindt, ga je op basis van deze nieuwe kennis opnieuw data verzamelen en analyseren.
Met de grounded theory-methode van Strauss en Glaser kun je een nieuwe wetenschappelijke theorie ontwikkelen over je onderwerp die gebaseerd (gegrond) is op data die je verzamelt met kwalitatief of kwantitatief onderzoek.
Je doorloopt hierbij een cyclus van dataverzameling, -analyse en reflectie om categorieën te formuleren waarin je de data indeelt, totdat je theoretische saturatie bereikt. Vervolgens ontwikkel je een theorie die je toetst met behulp van wetenschappelijke literatuur.
Als je meer wilt lezen over grounded theory, kun je de volgende boeken raadplegen:
Glaser, B., & Strauss, A. (1967). The discovery of grounded theory: Strategies for qualitative research. Aldine.
Glaser, B. (1992). Basics of grounded theory analysis. Sociology Press.
Strauss, A., & Corbin, J. (1994). Grounded theory methodology: An overview. In N. Denzin & Y. Lincoln (Reds.), Handbook of qualitative research (pp. 273–285). Sage Publications.
Strauss A., & Corbin, J. (1998). Basics of qualitative research – techniques and procedures for developing grounded theory (2e ed.). Sage Publications.
Het doel van een etnografie is om rijke data te verzamelen door jezelf onder te dompelen in een gemeenschap en de lezer er vervolgens van te overtuigen dat je observaties en interpretaties overeenkomen met de werkelijkheid.
Etnografie (ethnography) is een vorm van kwalitatief onderzoek waarbij de onderzoeker zich onderdompelt in een gemeenschap of organisatie om gedragingen en interacties van dichtbij te kunnen observeren. De term etnografie verwijst ook naar het geschreven rapport dat de etnograaf na afloop opstelt.
Etnografie is een flexibele onderzoeksmethode waarmee je inzicht kunt verkrijgen in een gedeelde cultuur, conventies en de sociale dynamiek van een bepaalde groep. De onderzoeksbenadering gaat wel gepaard met praktische en ethische uitdagingen.
Of je jouw enquêteonline of offline afneemt, is afhankelijk van je doelgroep, de aard van het onderzoek en de tijd die je hiervoor hebt. Zo zijn oudere participanten vaak moeilijk online te bereiken, terwijl jongeren wellicht liever online deelnemen.
Je enquête moet betrouwbaar en valide zijn om op basis van de resultaten conclusies te kunnen trekken.
Voor debetrouwbaarheidmoet je de vragenlijst op consistente wijze afnemen en willekeurige fouten voorkomen bij dedata-analyse.
Voor devaliditeit is het van belang dat je begrippen correct zijn geoperationaliseerd, zodat je meet wat je daadwerkelijk beoogt te meten. Zorg er bovendien voor dat je steekproef representatief is voor je doelgroep.
Bij een participerende observatie maak je als observator deel uit van de context waarin het gedrag van mensen bestudeerd wordt. Meestal weten participanten dat ze geobserveerd worden, maar soms ook niet.
Bij een niet-participerende observatie maak je als observator geen deel uit van de sociale setting die geobserveerd wordt. In de meeste gevallen wordt de observator niet gezien door de individu(en) die geobserveerd worden, bijvoorbeeld omdat de onderzoeker videobeelden observeert.
Voorbeeld: “Hoe gedragen probleemjongeren zich in de klas ten aanzien van hun docent?”
Als er nog weinig bekend is over het menselijk gedrag in een bepaalde situatie.
Voorbeeld: Observeren hoe mensen zich in de supermarkt zich gedragen de dag na de aankondiging van nieuwe maatregelen met betrekking tot het coronavirus.
Als fenomenen of personen in hun natuurlijke setting moeten worden bestudeerd.
Voorbeeld: Het gedrag van mensen in hun werkomgeving.
Als het waarschijnlijk is dat respondenten met zelfrapportage (in een interview of enquête) hun gedrag anders beschrijven dan het daadwerkelijk is.
Voorbeeld: Observeren hoeveel een persoon rookt op een dag.
Als je voor observaties hebt gekozen als onderzoeksmethode, kijk en luister je naar wat mensen doen en zeggen (menselijk gedrag) in een bepaalde situatie. Alles wat je waarneemt, leg je vast in een verslag.
Na je observaties analyseer en interpreteer je de verkregen data om je onderzoeksonderwerp te kiezen, hypothesen op te stellen, antwoord te geven op hoofd- of deelvragen of eventueel een conclusie te trekken.
In het geval van een scriptie gebruik je de observaties meestal om je hoofd- of deelvragen te beantwoorden.
Oorspronkelijk werden focusgroep-interviews met name gebruikt voor marktonderzoek (naast interviews en enquêtes), omdat veel consumenten beslissingen nemen in sociale context.
Tegenwoordig worden focusgroepen in bijna alle domeinen van sociaal onderzoek ingezet. Denk daarbij bijvoorbeeld aan politiek onderzoek (hoe mensen op een bepaald beleid reageren) of aan de gezondheidszorg (hoe patiënten bijwerkingen ervaren).
Een focusgroep (ook wel focusgroep-interview genoemd) is een kwalitatieve onderzoeksmethode waarbij een groep mensen wordt samengebracht om te discussiëren over een vooraf bepaald onderwerp.
Een focusgroep is dus een soort interview waaraan meerdere respondenten tegelijkertijd deelnemen. De onderzoeker stelt vragen aan de groep en faciliteert de discussie. Het doel van een focusgroep is om data te verzamelen.
Voorbereiden: Je oriënteert je, bakent het onderwerp af, en bepaalt zoekwoorden.
Literatuur verzamelen: Je verzamelt relevante literatuur door te zoeken in databases, via zoekmachines, en in literatuurlijsten van gevonden publicaties.
Literatuur beoordelen en selecteren: Je maakt een selectie, waarbij je alleen relevante en kwalitatief hoge bronnen overhoudt.
Literatuur verwerken: Je kunt je bronnen uitgebreid beschrijven en evalueren, of de informatie verwerken in je probleemanalyse of theoretisch kader.
Literatuuronderzoek (ook literatuurstudie of literature review genoemd) is een methode om bestaande kennis over je onderwerp of probleemstelling te verzamelen. Deze kennis vind je in verschillende bronnen, zoals wetenschappelijke tijdschriftartikelen, boeken, papers, scripties en archiefmateriaal.
Het resultaat is niet alleen een beschrijving van de gevonden informatie, maar ook een kritische bespreking van de meest relevante informatie. Een literatuuronderzoek kan op zichzelf staan of deel uitmaken van een groter geheel.
Er is sprake van triangulatie als je verschillende bronnen, theorieën, onderzoeksmethoden of data-analysemethoden gebruikt om iets te onderzoeken. Hierdoor bekijk je je onderzoeksvraag vanuit verschillende richtingen.
Verbindingswoorden of signaalwoorden zijn belangrijk, omdat de lezer hierdoor weet wat het verband is tussen alinea’s of zinnen. Bovendien zorgt het gebruik van deze woorden ervoor dat de tekst fijner en dynamischer leest.
Verbindingswoorden worden ook wel signaalwoorden of indicatoren genoemd. Het zijn woorden of woordgroepen waarmee een verband wordt aangegeven tussen alinea’s of zinnen.
Hierdoor kan de lezer makkelijker afleiden op welke manier verschillende delen van de tekst verbonden zijn. Er zijn onder andere signaalwoorden om een vergelijkend, tegenstellend of opsommend verband aan te geven, zoals:
Een acroniem bestaat uit de eerste letter van ieder woord in een woordgroep. Je spreekt acroniemen uit alsof het woorden zijn (zoals havo voor hoger algemeen voortgezet onderwijs).
Sommige acroniemen schrijf je met hoofdletters, terwijl je andere acroniemen met kleine letters schrijft.
Een afkorting is een verkorte versie van een woord of een woordgroep die gevormd wordt door alleen bepaalde letters van het woord of de woordgroep te gebruiken.
Je kunt de modus bepalen met behulp van de volgende stappen:
Als je data numeriek van aard zijn, rangschik je de waarden van laag naar hoog. Als je data categorisch zijn, verdeel je de waarden over de juiste categorieën.
Zoek de waarde of waarden die het vaakst voorkomen.
Om de mediaan te vinden, zet je de waarden in je dataset van laag naar hoog. Vervolgens bepaal je de middelste positie op basis van n (het aantal waarden in je dataset).
Als n een oneven getal is, vind je de mediaan op positie .
Als n een even getal is, is de mediaan het gemiddelde van de waarden op posities en .
De mediaan is de meest informatieve centrummaat voor scheve verdelingen of verdelingen met uitbijters. De mediaan wordt bijvoorbeeld vaak gebruikt als centrummaat voor de variabele “inkomen”, die over het algemeen niet normaal verdeeld is.
Aangezien je voor de mediaan slechts één of twee waarden in het midden gebruikt, wordt deze maat niet beïnvloed door extreme uitbijters of niet-symmetrische verdelingen. Het gemiddelde en de modus zijn hier wel gevoelig voor.
Ook moet je op de verdeling van je data letten. Voor normaal verdeelde data kun je alle drie de centrummaten gebruiken, maar bij scheve verdelingen is de mediaan de beste keuze.
Statistische significantie is een term die door onderzoekers wordt gebruikt om aan te geven dat het onwaarschijnlijk is dat hun resultaten op toeval gebaseerd zijn. Significantie wordt meestal aangeduid met een p-waarde (overschrijdingskans).
Statistische significantie is enigszins willekeurig, omdat je zelf de drempelwaarde (alfa) kiest. De meest voorkomende drempel is p < 0.05, wat betekent dat de kans 5% is dat de resultaten worden gevonden terwijl de nulhypothese waar is. Een andere drempel die vaak wordt gekozen is p < 0.01.
Als de p-waarde lager is dan de gekozen alfa-waarde, mag je stellen dat het resultaat van de toets statistisch significant is.
Met beschrijvende statistiek (ook wel descriptieve statistiek genoemd) vat je de kenmerken van een dataset samen. Met toetsende statistiek (ook wel inferentiële of verklarende statistiek genoemd) toets je een hypothese of bepaal je of je data generaliseerbaar zijn naar een bredere populatie.
Statistische analyseis de meest belangrijke methode om kwantitatieve onderzoeksgegevens te analyseren. Hierbij wordt gebruikgemaakt van kansen en modellen om voorspellingen over een populatie te toetsen op basis van steekproefdata.
Bij een getrapte steekproef of meertrapssteekproef (multistage sampling) trek je een steekproef uit een populatie met in elke fase kleinere groepen (steekproefeenheden).
Deze methode wordt vaak gebruikt om gegevens te verzamelen voor een grote, geografisch verspreide groep mensen. Meestal volg je hierbij een vaststaande hiërarchie (bijvoorbeeld: provincies, gemeenten, buurten, huishoudens) om vervolgens op een relatief snelle en goedkope manier gegevens te verzamelen.
De twee soorten externe validiteit zijn populatievaliditeit (of je je resultaten naar andere groepen kunt generaliseren) en ecologische validiteit (of je je resultaten naar andere contexten kunt generaliseren).
Interne validiteit is de mate waarin je met zekerheid kunt stellen dat een vastgestelde oorzaak-gevolgrelatie (causaal verband) niet door andere factoren kan worden verklaard.
Je kunt de wetenschappelijke integriteit waarborgen door onderzoek te verrichten dat voldoet aan de vijf principes (eerlijkheid, zorgvuldigheid, transparantie, onafhankelijkheid, verantwoordelijkheid). Hiervoor kun je onder andere letten op de volgende punten:
Wetenschappelijk onderzoek ligt ten grondslag aan vele belangrijke beslissingen, bijvoorbeeld op medisch, sociaal of politiek vlak. Daarom is het essentieel dat de wetenschappelijke integriteit niet wordt geschaad, zodat anderen op de resultaten kunnen vertrouwen (of ze kunnen controleren door te repliceren).
De wetenschappelijke integriteit (scientific integrity) wordt gewaarborgd als onderzoek wordt verricht volgens vijf principes: eerlijkheid, zorgvuldigheid, transparantie, onafhankelijkheid en verantwoordelijkheid.
De vijf principes zijn vertaald naar 61 normen voor goede onderzoekspraktijken (best practices).
Een topiclijst (topic list) is een lijst van alle onderwerpen die je tijdens je interviews wilt behandelen. Het is handig om deze alvast in een logische volgorde te zetten, maar tijdens het interview mag je afwijken van de bedachte structuur.
Het belangrijkste verschil tussen inductief en deductief redeneren is dat je bij inductief redeneren een nieuwe theorie probeert te creëren, terwijl je bij deductief redeneren een bestaande theorie probeert te toetsen.
Deductief redeneren is een top-downonderzoeksmethode, waarbij je op basis van een generalisatie naar specifieke gevallen zoekt. Met behulp van deductief onderzoek toets je theorieën enhypothesen. Het proces bestaat over het algemeen uit dezelfde vier stappen: er is een theorie (generalisatie), je formuleert een hypothese, je observeert of analyseert, je bevestigt of ontkracht de hypothese.
Inductief redeneren is een bottom-up onderzoeksmethode, waarbij je onderzoekt of je op basis van een specifieke observatie resultaten kunt generaliseren. Het proces bestaat over het algemeen uit dezelfde vier stappen: een observatie doen, data verzamelen, een patroon ontdekken en een hypothese of theorie formuleren (generalisatie).
Een ongestructureerd interview is een interview waarin alleen trefwoorden en onderwerpen vaststaan, maar de vragen niet van tevoren worden geformuleerd. Het interview is vergelijkbaar met een alledaags gesprek en heeft als doel zoveel mogelijk over een onderwerp te weten te komen.
Een gestructureerd of gestandaardiseerd interview is een interviewvorm waarbij de vragen van tevoren worden opgesteld (en waarvan niet wordt afgeweken). Ook ligt de volgorde van vragen vast en geef je respondenten meestal maar enkele antwoordopties waaruit ze kunnen kiezen.
Een deel van de gestelde vragen wordt vooraf door de interviewer bepaald. De volgorde waarin de vragen worden gesteld is flexibel en de respondenten kunnen volledig vrij antwoorden. Ook kan de interviewer bij deze onderzoeksmethode doorvragen op de antwoorden van de geïnterviewde.
Hoewel interval– en ratiodata beide kunnen worden gecategoriseerd, gerangschikt en gelijke afstanden hebben tussen aangrenzende waarden (gelijke intervallen), hebben alleen ratiodata een absoluut of betekenisvol nulpunt.
De temperatuur in Celsius of Fahrenheit is een voorbeeld van een intervalschaal, omdat nul niet de laagst mogelijke temperatuur is. Je kunt namelijk ook nog te maken hebben met min-temperaturen. Een Kelvin-temperatuurschaal is een voorbeeld van een ratioschaal, omdat nul het absolute nulpunt is. Er zijn geen min-temperaturen.
Je onderzoek is empirisch van aard als je het onderzoek zelfuitvoert, waardoor je nieuwe resultaten verkrijgt. Je beantwoordt je onderzoeksvraag door systematisch data te verzamelen met behulp van een empirische onderzoeksmethode. Vervolgens analyseer je de data.
Eensystematische steekproef (systematic sampling) is een aselecte steekproefmethode waarbij onderzoekers leden van de populatie selecteren op basis van een regelmatig interval. Zo kunnen ze bijvoorbeeld iedere 20e persoon op een lijst van de populatie selecteren.
Als de volgorde van participanten op de lijst willekeurig is, kun je hiermee het willekeurige karakter van een enkelvoudige aselecte steekproef nabootsen. Dit draagt bij aan de validiteit van je resultaten.
Een externe variabele is een variabele waarin je niet geïnteresseerd bent (die je niet onderzoekt), maar die wel van invloed kan zijn op de afhankelijke variabele in je onderzoek.
Een confounding variabele valt onder externe variabelen. Dit type beïnvloedt niet alleen de afhankelijke variabele, maar is ook gerelateerd aan de onafhankelijke variabele.
Om het verschil beter te illustreren, gebruiken we het voorbeeld van de hand: alle duimen zijn vingers, maar niet alle vingers zijn duimen. In het geval van deze variabelen zijn alle confounding variabelen externe variabelen, maar niet iedere externe variabele is een confounding variabele.
Een storende variabele (confounding variabele) is een derde variabele die de relevante variabelen beïnvloedt, waardoor ze gerelateerd lijken terwijl ze dat niet zijn.
Een mediërende variabele verklaart daarentegen hoe twee variabelen gerelateerd zijn.
Een mediërende variabele verklaart het proces waardoor twee variabelen gerelateerd zijn, terwijl een modererende variabele de sterkte en richting van die relatie beïnvloedt.
Als je niet controleert voor relevante externe variabelen, kunnen deze de uitkomsten van je onderzoek beïnvloeden en kun je mogelijk niet aantonen dat de resultaten daadwerkelijk het gevolg zijn van een manipulatie van de onafhankelijke variabele.
Controlevariabelen zijn alle variabelen die constant worden gehouden in een onderzoek. Het zijn variabelen waarin je niet geïnteresseerd bent, maar waarvoor wordt gecontroleerd, omdat ze resultaten kunnen beïnvloeden.
Als je een gestratificeerde steekproef wilt gebruiken, moet je je populatie volledig kunnen verdelen in subpopulaties die elkaar uitsluiten. Dat betekent dat elk lid van de populatie duidelijk in maar één subgroep kan worden ingedeeld.
Een gestratificeerde steekproef is de beste keuze als je denkt dat subgroepen verschillende gemiddelde waarden zullen hebben voor de variabele(n) die je bestudeert.
Bij gestratificeerde steekproeven verdelen onderzoekers participanten over subgroepen (strata) op basis van een of meerdere gemeenschappelijke kenmerken (zoals etniciteit, gender, opleidingsniveau, et cetera).
Eenmaal verdeeld, wordt een aselecte steekproef getrokken voor iedere subgroep.
Met een quasi-experimenteel design probeer je een oorzaak-gevolgrelatie vast te stellen. Het belangrijkste verschil met een echt experiment is dat de participanten niet willekeurig worden verdeeld over controlegroepen en experimentele groepen. Er is dus geen sprake van randomisatie.
Een meta-analyse is een onderzoek naar al bestaande studies over een bepaald onderwerp. Het is een kwantitatieve of statistische onderzoeksmethode. Bij dit type analyse vergelijk je de resultaten van diverse onderzoeken (primaire studies) om je eigen hoofdvraag te beantwoorden.
Helaas biedt deze methode ook minder statistische zekerheid dan andere methoden, zoals een enkelvoudige aselecte steekproef, omdat het moeilijk is om te bepalen of de clusters representatief zijn voor de gehele populatie.
Als je gebruik wilt maken van randomisatie, ken je ieder lid van de steekproef een nummer toe.
Vervolgens gebruik je bijvoorbeeld een random number generator om ieder nummer willekeurig toe te wijzen aan een controlegroep of experimentele groep. Je kunt ook andere methoden gebruiken, zoals de loterijmethode, het opgooien van een muntje, of de dobbelsteenmethode.
Randomisatie wordt gebruikt bij experimenten met een between-subjects design. Bij zulke designs is er meestal sprake van een controlegroep en een of meerdere experimentele groepen. Randomisatie zorgt ervoor dat de groepen vergelijkbaar zijn aan het begin van het onderzoek.
Over het algemeen gebruik je altijd randomisatie bij dit type experimenteel onderzoek, mits het bij het onderwerp van je onderzoek past en het ethisch is.
Bij experimenteel onderzoek is randomisatie een manier om participanten uit je steekproef over verschillende groepen te verdelen. Door deze methode te gebruiken, heeft ieder lid van de steekproef een even grote kans om in een controlegroep of experimentele groep te worden geplaatst.
Je data kunnen twee meetniveaus hebben: ordinaal of interval. De data-analysemethode is afhankelijk van het meetniveau van de data.
data van de individuelelikertvragen zijn ordinaal.
data van de totale likertschaal worden beschouwd als intervaldata.
Bij ordinale schalen zijn de verschillen tussen de antwoordopties niet gelijk verdeeld of onbekend. Zo weet je bijvoorbeeld niet zeker of het verschil tussen “Helemaal mee oneens” en “oneens” even groot is als het verschil tussen “oneens” en “neutraal”.
Bij intervalschalen zijn deze verschillen tussen antwoordopties wel gelijk. Zo is het verschil tussen “1” en “2” bijvoorbeeld net zo groot als het verschil tussen “2” en “3”.
De data van de totale likertschaal worden vaak gezien als intervaldata, omdat het een totaalscore is waarbij scores van vier of meer vragen bij elkaar zijn opgeteld.
Een likertschaal wordt ook wel een waarderingsschaal of gedwongen-keuzeschaal genoemd (zeker als er geen neutrale antwoordoptie is). Likertschalen worden gebruikt om meningen, houdingen of gedrag te onderzoeken. Ze worden meestal ingezet bij enquêteonderzoek, omdat dit type schaal het mogelijk maakt om persoonlijkheidskenmerken of waarnemingen eenvoudig te operationaliseren.
Longitudinale onderzoeken kunnen weken, maar ook tientallen jaren duren, omdat je dezelfde participanten op meerdere tijdstippen test. Over het algemeen nemen ze minimaal een jaar in beslag. Daarom is dit type onderzoek vaak minder geschikt voor scripties.
Longitudinale onderzoeken zijn heel handig om de juiste volgorde van gebeurtenissen vast te stellen. Ook kun je veranderingen door de tijd heen onderzoeken en krijg je inzicht in oorzaak-gevolgrelaties.
Helaas zijn longitudinale onderzoeken over het algemeen wel duurder en tijdrovender dan andere soorten onderzoek.
Je kunt met cross-sectionele onderzoeken geen oorzaak-gevolgrelaties (causaliteit) vaststellen. Ook is het niet mogelijk om veranderingen als gevolg van tijd te onderzoeken. Om causaliteit te onderzoeken, moet je een longitudinale of experimentele studie uitvoeren.
Cross-sectionele onderzoeken zijn vaak minder duur en minder tijdrovend dan andere soorten onderzoek. Je kunt nuttige inzichten verkrijgen in de eigenschappen van een populatie. Ook is het mogelijk om correlaties vast te stellen die je in een vervolgonderzoek kunt onderzoeken.
Soms zijn er alleen cross-sectionele data beschikbaar voor je onderzoek, maar in andere gevallen zijn cross-sectionele data ook daadwerkelijk voldoende om een onderzoeksvraag te beantwoorden.
Longitudinale onderzoeken en cross-sectionele onderzoeken zijn twee soorten onderzoeksdesigns. Bij een cross-sectioneel onderzoek verzamel je data van een populatie op één moment in de tijd, terwijl je bij een longitudinaal onderzoek data verzamelt van dezelfde participanten op meerdere momenten in de tijd.
Longitudinaal onderzoek
Cross-sectioneel onderzoek
Herhaalde observaties
Observaties op één moment
Je observeert dezelfde groep meerdere keren
Je observeert verschillende groepen (een “cross-sectie”) in de populatie één keer
Je onderzoekt veranderingen door de tijd heen
Je geeft een momentopname van de maatschappij op een specifiek punt
Een sampling bias treedt op als bepaalde individuen uit een populatie een grotere kans hebben om in de steekproef te worden opgenomen dan andere individuen uit die populatie.
Het is bijna altijd nodig om een steekproef te gebruiken, omdat populaties over het algemeen te groot zijn om ieder individueel lid te onderzoeken. Door een representatieve subsectie (steekproef) te onderzoeken en een valide en betrouwbaar onderzoek uit te voeren, kun je uitspraken doen over een grotere populatie.
Een enkelvoudige aselecte steekproef (simple random sampling) is de eenvoudigste versie van een aselecte steekproef. De onderzoeker kiest willekeurig participanten uit een populatie om een steekproef te vormen. Ieder lid van de populatie heeft een even grote kans om in de steekproef te belanden. Vervolgens vindt de dataverzameling plaats.
Je kunt bijvoorbeeld willekeurig participanten kiezen door een random number generator te gebruiken.
Tekstuele analyse is een overkoepelende term voor verschillende onderzoeksmethoden die worden gebruikt om teksten te beschrijven, interpreteren en te begrijpen. Er zijn veel soorten informatie die je kunt afleiden uit een tekst. Vaak ben je op zoek naar de letterlijke betekenis, subtekst, symbolisme, aannames en normen en waarden die in de tekst naar voren komen.
Een tekst hoeft niet per se een traditionele tekst te zijn. Het kan ook gaan om een film, afbeelding of plaats.
Het nominale meetniveau verschilt van het ordinale meetniveau, omdat nominale data alleen gecategoriseerd kunnen worden, maar ordinale data ook gerangschikt kunnen worden.
Een voorbeeld van een nominale variabele is “Kledingwinkels”. Je kunt de data bijvoorbeeld verdelen over Zara, H&M, Only en Primark, maar je kunt die kledingwinkels niet op een natuurlijke, logische manier rangschikken.
Een voorbeeld van een ordinale variabele is “Leeftijd”. Je kunt de data bijvoorbeeld verdelen over 0-18, 19-34, 35-49 en 50+, en deze categorieën kun je in een logische volgorde zetten.
Nominale data kunnen worden verdeeld over categorieën (waarbij ieder datapunt maar in één categorie hoort) en de categorieën kunnen niet worden gerangschikt op een logische of natuurlijke manier.
Een voorbeeld van een nominale variabele is “vervoersmiddel”. Deze zou bijvoorbeeld uit de categorieën fiets, auto, bus, trein, metro en tram kunnen bestaan. Die vervoersmiddelen kunnen niet op een logische manier worden geordend, want het maakt bijvoorbeeld niet uit of je start met de fiets of de auto.
In het geval van een ordinale variabele, zoals “opleidingsniveau” zou je de opleidingsniveaus vmbo, havo, vwo wel op een logische manier kunnen rangschikken.
Het nominale meetniveau is het minst complexe en minst precieze meetniveau.
De data kunnen worden verdeeld over verschillende categorieën van de variabele.
De categorieën kunnen op een logische, natuurlijke manier worden gerangschikt.
Het ordinale meetniveau verschilt van het intervalmeetniveau, omdat de afstand tussen twee categorieën niet gelijk is of onbekend is.
Stel je hebt de categorieën beginner, gevorderde en expert. Het is niet mogelijk om aan te geven of een beginner net zoveel verschilt van een gevorderde als een gevorderde van een expert.
Een case study is een gedetailleerd onderzoek naar een specifiek onderwerp, zoals een persoon, groep, plaats, gebeurtenis, organisatie of fenomeen. Case studies worden veelal gebruikt in sociaal, onderwijskundig, medisch, klinisch of business-gerelateerd onderzoek.
Bij deskresearch of bureauonderzoek verzamel je zelf geen nieuwe data (zoals bij veldonderzoek of fieldresearch wel het geval is). In plaats daarvan gebruik je data die al verzameld zijn door anderen, zoals interne documenten van je stagebedrijf.
Met veldonderzoek (of fieldresearch) verzamel, analyseer en interpreteer je primaire data, ofwel nieuwe informatie, door bijvoorbeeld enquêtes af te nemen, interviews te houden of observaties uit te voeren. Je doel is om zo een antwoord te vinden op je onderzoeksvragen.
Het verschil tussen veldonderzoek (fieldresearch) en bureauonderzoek (deskresearch) is dat je bij veldonderzoek zelf het “veld” betreedt om data te verzamelen, terwijl je bij bureaonderzoek gebruikmaakt van eerder verzamelde data door anderen.
In grafieken wordt de verklarende variabele over het algemeen op de x-as (horizontale as) geplaatst, terwijl de responsvariabele op de y-as (verticale as) wordt geplaatst.
Als je kwantitatieve variabelen hebt, gebruik je een scatterplot of lijndiagram.
Als je responsvariabele categorisch is, gebruik je een scatterplot of lijndiagram.
Als je verklarende variabele categorisch is, gebruik je een staafdiagram.
In sommige gevallen gebruiken onderzoekers liever de term “verklarende variabele” in plaats van “onafhankelijke variabele“, omdat onafhankelijke variabelen in natuurlijke situaties toch vaak worden beïnvloed door andere variabelen. Dat betekent dat ze niet zuiver onafhankelijk zijn.
Een verklarende variabele (explanatory variable) is de variabele die je manipuleert of waar je veranderingen in waarneemt, terwijl de responsvariabele(response variable) verandert als gevolg van die manipulatie.
Het is mogelijk om meerdere variabelen te onderzoeken in een experiment, maar je dient dan ook meerdere onderzoeksvragen te formuleren.
Je bent bijvoorbeeld geïnteresseerd in het effect van dieet op gezondheid. Je kunt meerdere maten gebruiken om de gezondheid te meten, zoals de bloedsuikerspiegel, hartslag en bloeddruk. Iedere maat is een aparte afhankelijke variabele die gepaard gaat met een eigen onderzoeksvraag.
Je bent niet alleen geïnteresseerd in iemands dieet, maar ook in de mate van fysieke activiteit (of zelfs het effect van een combinatie van die twee). Je spreekt dan van twee onafhankelijke variabelen.
In een experiment manipuleer je slechts één onafhankelijke variabele per keer om de interne validiteit te waarborgen.
In één experiment kan een variabele niet zowel onafhankelijk als afhankelijk zijn. Je variabele wordt of gezien als vermoedelijke oorzaak of als gevolg.
Het kan wel voorkomen dat een variabele in het ene onderzoek een onafhankelijke variabele is en in een ander, ongerelateerd onderzoek een afhankelijke variabele.
Als je onderzoekt of iemands zelfbeeld een effect heeft op het aantal berichten dat iemand plaatst op sociale media, is het zelfbeeld de onafhankelijke variabele.
Als je onderzoekt of het aantal complimenten dat iemand ontvangt een effect heeft op het zelfbeeld, is het zelfbeeld de afhankelijke variabele.
De onafhankelijke variabele is de variabele waarvan je denkt dat deze de oorzaak is.
De afhankelijke variabele is de variabele waarvan je denkt dat deze het gevolg is.
In een experiment manipuleer je de onafhankelijke variabele en meet je de afhankelijke variabele. Je wilt onderzoeken of de onafhankelijke variabele invloed uitoefent op de afhankelijke variabele.
Een voorbeeld is een onderzoek naar het effect van verschillende soorten muziek op de productiviteit op werk. De onafhankelijke variabele (vermoedelijke oorzaak) is de muziek en de afhankelijke variabele (vermoedelijk gevolg) is de productiviteit op werk.
Correlationeel onderzoek wordt gebruikt om de relatie tussen twee (of meer) variabelen te onderzoeken zonder dat de onderzoeker de variabelen manipuleert of controleert. Het is een niet-experimentele variant van kwantitatief onderzoek, waardoor je geen causaliteit kunt vaststellen.
Een correlatie laat zien of er een verband is tussen twee of meerdere variabelen. Een correlatiecoëfficiënt kan de richting van het verband (positief, negatief) laten zien en geeft ook aan hoe sterk het verband is.
Een positieve correlatie betekent dat beide variabelen samen toenemen of afnemen.
Een negatieve correlatie betekent dat de ene variabele toeneemt, terwijl de andere variabele afneemt.
Als de correlatiecoëfficiënt gelijk is aan 0, is er geen verband tussen de variabelen (zero correlation).
Een correlatie is een statistische indicator voor een verband tussen variabelen: als de ene variabele verandert, verandert de andere variabele ook, maar er hoeft geen oorzaak-gevolgrelatie te zijn. Correlaties worden onderzocht in correlationeel onderzoek.
Causaliteit betekent dat een verandering in de ene variabele een verandering in de andere variabele veroorzaakt. Er is dus wel sprake van een oorzaak-gevolgrelatie. De variabelen correleren én er is een causaal verband. Causaliteit wordt onderzocht in experimenteel onderzoek.
Andere variabelen (third variable problem): er zijn confounding variabelen die de twee onderzochte variabelen kunnen beïnvloeden, waardoor er onterecht een causaal verband lijkt te bestaan.
Directionaliteit of richting(directionalityproblem): twee variabelen correleren en zouden een causale relatie kunnen hebben, maar het is niet mogelijk om vast te stellen of variabele A invloed uitoefent op variabele B, of andersom.
Met gecontroleerde experimenten kun je causaliteit aantonen, terwijl je met correlationeel onderzoek alleen verbanden tussen variabelen kunt aantonen.
In een experimenteel onderzoek manipuleer je een onafhankelijke variabele en meet je de invloed op een afhankelijke variabele. Je controleert voor andere variabelen, zodat deze geen invloed kunnen uitoefenen op de resultaten.
In correlationeel onderzoek meet je de variabelen zonder ze te manipuleren. Je kunt hierdoor vaststellen dat de variabelen samen veranderen (allebei toename, allebei afname of de een neemt toe en de ander neemt af), maar je kunt niet vaststellen of de verandering in variabele A de verandering in variabele B veroorzaakt.
Over het algemeen wordt correlationeel onderzoek gekenmerkt door een hoge externe validiteit, terwijl experimenteel onderzoek gepaard gaat met een hoge interne validiteit.
Within-subjects designs gaan over het algemeen gepaard met een hoge statistische power, maar de eigenschappen van het design kunnen wel de interne validiteit schaden.
Voordelen
Kleine steekproef nodig;
Grote statistische power;
Geen effect van verschillen in participant-eigenschappen (want je test dezelfde participanten meerdere keren).
Nadelen
De interne validiteit is vaak lager, omdat variabelen direct gerelateerd (niet onafhankelijk) zijn.
Tijdgerelateerde effecten, zoals fysieke en mentale veranderingen, kunnen de uitkomsten beïnvloeden.
Carryover effects (overdraagbaarheidseffecten) kunnen ervoor zorgen dat de uitkomsten beïnvloed worden door de specifieke volgorde van condities.
In een factorieel design (factorial design) worden meerdere onafhankelijke variabelen onderzocht.
Als je twee variabelen onderzoekt, wordt ieder niveau van de ene onafhankelijke variabele gecombineerd met ieder niveau van de andere variabele om verschillende condities te creëren.
Ja, je kunt een between-subjects design en een within-subjects design combineren in hetzelfde onderzoek als je twee of meer onafhankelijke variabelen hebt (factorieel design). In een mixed factorial design wordt (minimaal) één variabele between-subjects gevarieerd en (minimaal) één variabele within-subjects.
Hoewel een between-subjects design vaak gepaard gaat met een hogere interne validiteit dan een within-subjects design, heb je wel meer participanten nodig voor dezelfde hoge statistische power.
Voordelen
Voorkomt carryover-effecten, zoals een leereffect of vermoeidheidseffect.
Zorgt voor kortere experimenten, waardoor participanten wellicht eerder willen meedoen.
Nadelen
Vereist grotere steekproeven voor hoge statistische power.
Vereist meer middelen om participanten te werven, onkosten te vergoeden, et cetera.
Individuele verschillen tussen participanten kunnen alternatieve verklaringen vormen voor de resultaten.
Sommige variabelen gaan gepaard met een vaststaand meetniveau. Zo worden gender of etniciteit altijd op nominaal niveau gemeten, omdat je de categorieën niet kunt rangschikken.
Bij andere variabelen kun je het meetniveau wel kiezen. De variabele “studenteninkomen” kan bijvoorbeeld op ordinaal of rationiveau worden gemeten.
Op ordinaal niveau zou je vijf groepen kunnen creëren met een bepaald bereik (bijvoorbeeld 0 – 499, 500 – 799, 800 – 1099, 1100 – 1999 en 2000 – 2299). Participanten kruisen dan het juiste bereik aan.
Op rationiveau zou je naar het exacte inkomen vragen.
Als je kunt kiezen, is het beter om op rationiveau te meten, zodat je de data op meer manieren kunt analyseren. Hoe hoger je meetniveau, hoe preciezer de data.
Het niveau waarop je een variabele meet, bepaalt hoe je je data kunt analyseren.
Afhankelijk van het meetniveau kun je diverse descriptieve statistieken gebruiken om je data samen te vatten. Ook kun je inferentiële statistiek (ook wel toetsende of verklarende statistiek genoemd) gebruiken om te bepalen of je resultaten de hypothese ondersteunen of weerleggen.
Meetniveaus laten zien hoe precies variabelen worden gemeten. Er zijn vier meetniveaus (of meetschalen) die van laag naar hoog kunnen worden gerangschikt.
Nominaal: De data kunnen alleen worden gecategoriseerd (geen rangorde).
Ordinaal: De data kunnen worden gecategoriseerd en gerangschikt.
Interval: De data kunnen worden gecategoriseerd en gerangschikt en er zijn gelijke intervallen tussen de categorieën.
Ratio: De data kunnen worden gecategoriseerd en gerangschikt, de intervallen zijn gelijk, en er is een absoluut of betekenisvol nulpunt.
Participanten die tot de experimentele groep behoren krijgen een of meerdere experimentele condities aangeboden, terwijl participanten in de controlegroep geen enkele experimentele conditie aangeboden krijgen. Zo kun je controleren welk effect optreedt als je niets manipuleert. De samenstelling van de experimentele groep moet zo gelijk mogelijk zijn aan die van de controlegroep.
Voorbeeld: Experimentele groep versus controlegroepJe wilt onderzoeken welke voorleesmethode beter werkt om kinderen nieuwe woorden te leren. Daarom ontwerp je een experiment met drie groepen:
Groep 1 wordt interactief voorgelezen (eerste experimentele groep)
Groep 2 wordt passief voorgelezen (tweede experimentele groep)
Groep 3 wordt helemaal niet voorgelezen (controlegroep)
Groep 3 krijgt geen enkele experimentele conditie of manipulatie aangeboden, waardoor je kunt onderzoeken hoeveel nieuwe woorden kinderen zouden aanleren zonder voorgelezen te worden. Het zou bijvoorbeeld kunnen voorkomen dat beide voorleesmethoden niet voor een toename in het aantal geleerde woorden zorgen.
In een between-subjects design ervaart iedere participant maar één conditie en onderzoekers bekijken de verschillen tussen de gemiddelden van de groepen.
In een within-subjects design ervaart iedere participant alle condities van een experiment en onderzoekers testen dezelfde participanten meerdere keren (na iedere conditie) om verschillen te onderzoeken.
Voorbeeld: Between-subjects design vs within-subjects designStel je doet onderzoek naar het effect van verschillende muziekstijlen op de snelheid waarmee scholieren hun huiswerk maken.
Bij een between-subjects design zou je de ene groep bijvoorbeeld naar rockmuziek kunnen laten luisteren, terwijl je de andere groep klassieke muziek aanbiedt. De leden van een groep krijgen dus of alleen rockmuziek of alleen klassieke muziek. Op het eind vergelijk je de gemiddelde huiswerksnelheid van beide groepen met elkaar.
Bij een within-subjects design zou je de participanten eerst naar de ene muziekstijl kunnen laten luisteren en daarna naar de andere muziekstijl. Het ene deel van de participanten start met rockmuziek en het andere deel met klassieke muziek, zodat je zeker weet dat de volgorde geen invloed heeft. Je meet de participanten meerdere keren en kijkt wanneer ze sneller zijn: na rockmuziek of na klassieke muziek.
Je kunt kwalitatieve data op meerdere manieren analyseren, maar de methoden hebben vijf stappen gemeen:
Bereid je data voor
Bekijk en verken je data
Ontwikkel een codeersysteem voor je data
Ken codes toe aan de data
Identificeer terugkerende thema’s
De uitvoering van iedere stap hangt af van de focus van je analyse. Veelvoorkomende analyses zijn tekstuele analyse, thematische analyse en discourseanalyse.
Grounded theory: Onderzoekers verzamelen rijke data over het onderwerp en ontwikkelen theorieën op inductieve wijze
Etnografie: Onderzoekers dompelen zich onder in groepen of organisatie om de heersende cultuur te begrijpen
Actieonderzoek: Onderzoekers en participanten verbinden gezamenlijk theorie aan de praktijk om sociale verandering teweeg te brengen
Fenomenologisch onderzoek: Onderzoekers onderzoeken een fenomeen of gebeurtenis door de ervaringen van participanten te beschrijven en te interpreteren
Narratief onderzoek: Onderzoekers bekijken hoe verhalen worden verteld om te begrijpen hoe participanten deze waarnemen en interpreteren
Kwantitatief onderzoek heeft betrekking op getallen en statistiek, terwijl kwalitatief onderzoek over woorden en betekenissen gaat.
Met kwantitatieve onderzoeksmethoden kun je een hypothese toetsen door systematisch data te verzamelen en te analyseren, terwijl je met kwalitatieve methoden diepgaand onderzoek kunt doen naar ideeën en ervaringen.
Beschrijvend onderzoek kan een verkennend karakter hebben, bijvoorbeeld als er nog weinig bekend is over het onderzoeksonderwerp. Toch zijn er enkele verschillen tussen beschrijvend/descriptief onderzoek en verkennend/exploratief onderzoek.
Het doel
Flexibiliteit van het design
Einde van de tekst
Beschrijvend of descriptief onderzoek
Verkennend of exploratief onderzoek
Het doel is om inzicht te krijgen in mensen, gebeurtenissen, objecten of fenomenen
Het doel is om informatie te verzamelen, zodat je je onderzoeksvraag en -doel kunt bepalen
Met de CLI-zoekmachine kun je jurisprudentie van het Hof van Justitie van de Europese Unie vinden. Ook kun je eur-lex.eu, curia.eu en niet-digitale uitgaven van het hof raadplegen. De meest belangrijke bron voor jurisprudentie van het Europees Hof voor de Rechten van de Mens en de Europese Commissie voor de Rechten van de Mens is hudoc.echr.coe.int.
Als je wilt verwijzen naar een buitenlandse regeling, vermeld je het artikelnummer, de titel of citeertitel van de regeling in de oorspronkelijk taal, een eventuele vertaling tussen haakjes (voorafgegaan door ‘=’ of de naam van het land), het jaartal, het nummer en/of de datum van de regeling op een voor dat land gebruikelijke wijze, en eventueel de vindplaats.
Voorbeeld: Verwijzing naar een buitenlandse regelingArt. 2. Kaffeesteuergesetz (= Koffiebelasting) 2009 BGBl. I S. 1870, 1919 gesetze-im-internet.de.
Verwijzingen naar Europese jurisprudentie lijken sterk op verwijzingen naar Nederlandse jurisprudentie. Je voegt wel altijd het zaaknummer toe na de datum, en indien mogelijk de roepnaam. Je vermeldt geen website.
EHRM 25 maart 1999, ECLI:CE:ECHR:1999:0325 (Iatridis/Griekenland).
Volgens de Leidraad voor juridische auteurs mag je een nootnummer maar één keer gebruiken. Als je meerdere keren naar één voetnoot wilt verwijzen, moet je de voetnoot herhalen en deze een nieuw nootnummer geven. Zo hoeft de lezer niet terug te bladeren om de voetnoot te zoeken.
Als een bron geen auteur heeft, begin je de voetnoot met de (verkorte) titel (schuingedrukt). Vervolgens noteer je de overige broninformatie die wel beschikbaar is.
Voorbeeld: Verwijzing naar een bron zonder auteurAansprakelijkheid werkgevers 2021, p. 23.
Als je naar meerdere bronnen wilt verwijzen om je tekst te ondersteunen, gebruik je maar één nootnummer. De bijbehorende voetnoot kan vervolgens meerdere verwijzingen bevatten voor verschillende bronnen. Je plaatst dus nooit meerdere nootnummers achter een tekstdeel.
De volgorde voor de verwijzingen mag je zelf kiezen, maar het is goed om belangrijke bronnen eerst te noemen.
Voorbeeld: Meerdere verwijzingen in één voetnoot2. Oostervink 2020, p. 23. Smits, NJB, 2020/783. Pellet & Kurz 2021.
Je kunt op twee plaatsen afkortingen gebruiken: in de lopende tekst en in de voetnoten. In de lopende tekst kun je afkortingen beter vermijden, zodat deze goed leesbaar blijft. In de voetnoten gebruik je juist afkortingen om deze zo kort mogelijk te houden.
Je mag wel afkortingen gebruiken als de afkorting:
ook in de spreektaal wordt gebruikt;
ook gebruikelijk is in de Nederlandse taal;
voorkomt dat je een lange term veelvuldig herhaalt.
De Juridische Leidraad hanteert een lijst met standaard afkortingen die je kunt vinden in paragraaf 6.6 van de Leidraad.
Je introduceert de afkorting net als bij APA door de volledige term eerst uit te schrijven en de afkorting tussen haakjes te plaatsen. Daarna gebruik je alleen nog de afkorting.
Voorbeeld: Het introduceren van een afkortingHet Europees Hof voor de Rechten van de Mens (EHRM).
Afkortingen die gebruikelijk zijn in het Nederlandse taal, zoals art. en e.d., hoef je niet te introduceren en neem je niet op in een afkortingenlijst. Afkortingen in voetnoten worden ook niet geïntroduceerd.
We hebben een kleine selectie van veelvoorkomende afkortingen opgenomen in ons artikel over afkortingen. De volledige lijst bestaat uit honderden afkortingen en deze kun je vinden in paragraaf 6.6 van de Leidraad voor juridische auteurs.
De lijst is alfabetisch geordend, maar je kunt deze ook doorzoeken met de toets F3, Ctrl + F (Windows) of Command + F (Mac).
Als je wilt verwijzen naar Kamervragen of antwoorden op Kamervragen, verwijs je naar ‘Aanhangsel Handelingen I (of II)’, gevolgd door het zittingsjaar, de afkorting ‘nr.’, en het nummer.
Voorbeeld: Verwijzing naar antwoorden op KamervragenAanhangsel Handelingen I 2020/21, nr. 4.
Je verwijst op de volgende manier naar een Kamerstuk:
Kamerstukken I (of II, schuingedrukt), gevolgd door het parlementaire zittings- of vergaderjaar, een komma, het dossiernummer, een komma, de afkorting ‘nr.’, het ondernummer, een komma, de afkorting ‘p.’ en het paginanummer.
Voorbeeld: Verwijzing naar Eerste en Tweede Kamerstukken
Kamerstukken zijn schriftelijk uitgewisselde stukken tussen de Regering en het Parlement, en worden ook wel ‘witte stukken’ of ‘gedrukte stukken’ genoemd. Alle Kamerstuknummers zijn voorzien van een uniek kamerstuknummer. Kamerstukken die onder een ander Kamerstuk met hoofdnummer vallen, krijgen een vervolg- of ondernummer.
Niet alle regelingen krijgen een citeertitel. Als een regeling deze wel heeft, kun je de citeertitel meestal vinden in het slotartikel van de regeling. Vaak wordt de titel voorafgegaan door de zinsnede: “Deze wet wordt aangehaald als:”.
Als je een online versie van een gedrukte bron raadpleegt, verwijs je in principe gewoon naar de gedrukte versie. Het format hangt dan af van het type bron (zoals een boek of tijdschrift). De verkorte verwijzing in de voetnoot en de bronvermelding in de literatuurlijst voor een online boek zouden hetzelfde zijn als voor een gedrukt boek.
Je voegt alleen (online, bijgewerkt [datum]) toe aan de bronvermelding voor een online bron als deze heel frequent geactualiseerd wordt.
Voorbeeld: Verwijzing naar een frequent geactualiseerde bronBorman 2020
T.C. Borman, commentaar op art. 10:15 Awb, in: T.C. Borman & J.C.A. de Poorter (red.), Tekst & Commentaar Algemene wet bestuursrecht, Deventer: Wolters Kluwer 2017 (online, bijgewerkt 16 januari 2020).
Als je verwijst naar een webpagina of website, neem je geen bronvermelding op in de literatuurlijst. Je verwijst wel naar deze bronnen in een voetnoot. Hierbij zet je de naam van het artikel tussen enkele aanhalingstekens, gevolgd door een komma en de kortste versie van het webadres.
Voorbeeld: Verwijzing naar een webpagina‘Reproduceerbaarheid, repliceerbaarheid en herhaalbaarheid’, scribbr.nl
Een persistente identifier is een uniek label dat wordt toegewezen aan een online informatiebron. De labels maken het makkelijk om een bron op te zoeken op basis van een verwijzing. De Juridische Leidraad maakt onderscheid tussen drie soorten persistente identifiers, namelijk een Handle, DOI en JCDI. Deze kunnen er als volgt uitzien:
De Leidraad voor juridische auteurs biedt een zeer compleet overzicht van afkortingen, waaronder die van tijdschriften. Het is belangrijk dat je de juiste afkorting kiest, omdat je nergens de volledige naam van het tijdschrift noemt.
De volledige lijst met afkortingen kun je vinden in subparagraaf 6.6.2 van de Juridische Leidraad. Dit zijn veelvoorkomende afkortingen van tijdschriften en andere publicatiebronnen:
Naam tijdschrift
Afkorting
Advocatenblad
Adv.bl.
BMM Bulletin
BMM Bulletin
European Journal of International Law
EJIL
Familie & Recht
F&R
Jurisprudentie: Onderneming & Recht
JOR
Jurisprudentie: Personen- en Familierecht
JPF
Jurisprudentie: Vreemdelingenrecht
JV
Jurisprudentienieuwsbrief Bestuursrecht
JnB
Juristenkrant
Juristenkrant
Milieu & Recht
M en R
Modern Law Review
MLR
Nederlands Internationaal Privaatrecht
NIPR
Nederlands Juristenblad
NJB
Nederlands Tijdschrift voor Bestuursrecht
NTB
Nederlands Tijdschrift voor Burgerlijk Recht
NTBR
Nederlands Tijdschrift voor de Mensenrechten
NTM/NJCM-bull.
Nederlands Tijdschrift voor Internationaal Recht
NTIR
Nederlandse Jurisprudentie
NJ
Nederlandse Jurisprudentie Feitenrechtspraak civiele uitspraken
NJF
Nederlandse Jurisprudentie Feitenrechtspraak Strafzaken
NJFS
Publicatieblad van de Europese Unie
PbEU
Publications of the European Court of Human Rights
Als de auteur van een bron onbekend is, vermeld je de titel op de plaats van de auteursnaam. Dit geldt zowel voor de verkorte verwijzing in de voetnoot als voor de volledige bronvermelding in de literatuurlijst. In tegenstelling tot de auteursnaam wordt de titel gecursiveerd.
Verwijzing naar rapportRapport toekomst zorgstelsel 2020 Rapport over de toekomst van het Nederlands zorgstelsel, bijlage bij Kamerstukken II 2017/18, 38162, 12.
Bij een verwijzing naar een vertaald werk voeg je het oorspronkelijke publicatiejaar toe aan de voetnoot. Bovendien neem je de originele titel, het oorspronkelijke publicatiejaar en de naam van de vertaler op in de bronvermelding in de literatuurlijst. De informatie staat in beide gevallen tussen haakjes.
Voorbeeld: Verwijzing naar een vertalingHaidar (1973) 2020
S.A. Haidar, Over gerechtigheid, Meppel: Boom 2020 (On Justice 1973, vertaald door T. Szabo).
De bronvermelding in de literatuurlijst voor een bijdrage uit een boek of bundel bevat de initialen en achternaam van de auteur, de initialen en achternaam van de redacteur, de afkorting ‘red’ (tussen haakjes), de titel en eventuele subtitel (cursief), de plaats van uitgave, de uitgever, het jaartal en het paginabereik van de bijdrage.
Lagerhand 2019
K.T Lagerhand, ‘Het recht van spreken’, in: A.R. Bernts e.a. (red.), Spreekrecht voor nabestaanden. Een evaluatie, Apeldoorn: Spinhuis 2019, p. 111-134.
Om naar een latere bewerking van een boek te verwijzen, noem je de achternaam van de oorspronkelijke auteur, gevolgd door een schuine streep (/) en de achternaam van degene die het boek bewerkt heeft.
Voorbeeld: Voetnoot voor een latere bewerking van een boekKamerling-te Pas/Konings 2021
Dit zou een verwijzing zijn voor de bewerking van een boek van Kamerling-te Pas door Konings.
Bij een boek of tijdschrift met meerdere auteurs plaats je de auteursnamen in dezelfde volgorde als op het titelblad. Bij twee of drie auteurs plaats je een ampersand (&) voor de achternaam van de laatste auteur, zowel in de voetnoot als in de volledige bronvermelding.
Voorbeeld: Verwijzen naar een bron met twee of drie auteurs
Namutebi & Wassink 2021
Karper, De Man & Sjöberg 2020
Bij vier of meer auteurs vermeld je alleen de eerste auteursnaam, gevolgd door ‘e.a’ (wat ‘en anderen betekent). Dit doe je ook zowel in de voetnoot als in de literatuurlijst.
Verwijzen naar een bron met vier of meer auteursJones e.a.
De bronvermeldingen in je literatuurlijst komen op alfabetische volgorde te staan. Je baseert de plaats in de rangschikking op het eerste woord van de verkorte verwijzing in de voetnoot. Het maakt hierbij niet uit of dit een auteursnaam of titel is.
Bij de alfabetisering op basis van achternaam, wordt een eventueel tussenvoegsel genegeerd. Een bron van “De Rooij” komt dus bij de “R” van “Rooij” te staan, en niet bij de “D” van “De”.
In 2019 werd een nieuwe editie van de Leidraad voor Juridische auteurs uitgegeven. Deze bevat twee belangrijke wijzigingen ten opzichte van de versie uit 2016:
Je probeert in de voetnoot altijd zo kort mogelijk te verwijzen naar bronnen.
De toevoeging ‘online’ vermeld je alleen nog bij frequent geactualiseerde internetbronnen.
Daarnaast zijn enkele cosmetische aanpassingen gedaan:
Voor regelingen met citeertitels hoef je geen datum, plaats of vindplaats te vermelden. De vindplaats in het tijdschrift en het jaartal vermeld je alleen bij een nieuwe regeling met citeertitel.
Voorbeeld: Verwijzing naar een regeling met citeertitelBesluit uitvoering Crisis- en herstelwet (Stb. 2021, 193).
In veel gevallen is een verwijzing in de voetnoot niet nodig voor wet- of regelgeving. Of je wel of geen voetnoot toevoegt, hangt af van het onderwerp van de tekst, de aard van de regeling en het lezerspubliek.
Voorbeeld: Verwijzen naar een wetsartikel in de lopende tekstVolgens artikel 1:4 van de Algemene wet bestuursrecht heeft de term ‘bestuursrechter’ betrekking op een onafhankelijk orgaan.
Een verwijzing naar jurisprudentie heeft een vaste basisvorm die de afkorting van de instantie, de datum en de ECLI bevat. Je kunt echter nog aanvullende informatie toevoegen aan de voetnoot om de verwijzing te specificeren, zoals de plaats van de instantie, een paragraafnummer, de vindplaats, annotaties en de roepnaam.
Voorbeeld: Verwijzen naar jurisprudentie
ABRvS 12 mei 2021, ECLI:NL:RVS:2021:1015.
PHR 29 september 2020, ECLI:NL:PHR:2020:841 (concl. A-G B.F. Keulen), JM 2020/152, m.nt. S. Pieters.
Het format voor de verwijzing naar een online bron hangt af van het type bron. Als je wilt verwijzen naar een stabiele, niet-veranderlijke publicatie die ook in gedrukte vorm bestaat, zoals een tijdschrift, hanteer je het format voor de gedrukte versie van de bron.
Als je wilt verwijzen naar een veranderlijke publicatie die ook in gedrukte vorm bestaat, hanteer je het format voor de gedrukte versie van die bron. Echter, in dit geval voeg je (online, bijgewerkt …) toe aan de volledige verwijzing in de literatuurlijst, met op de plaats van … de meest recente bijwerkdatum.
Als je wilt verwijzen naar een website of webpagina voeg je alleen de naam van de website of de titel van de pagina toe, gevolgd door het webadres (zo kort mogelijk, dus zonder www.).
Verwijzen naar een frequent geactualiseerde bron of een website
Borman 2020
T.C. Borman, commentaar op art. 10:15 Awb, in: T.C. Borman & J.C.A. de Poorter (red.), Tekst & Commentaar Algemene wet bestuursrecht, Deventer: Wolters Kluwer 2017 (online, bijgewerkt 16 januari 2020).
‘Samenvatting Leidraad voor juridische auteurs’, scribbr.nl.
De voetnoot voor een tijdschrift bevat de achternamen van de auteurs, de verkorte titel van het tijdschrift (schuingedrukt), het jaartal en het publicatienummer. Als het publicatienummer ontbreekt, gebruik je het paginabereik.
De bronvermelding in de literatuurlijst bevat de initialen en achternamen van de auteurs, de titel van het artikel (tussen aanhalingstekens), de verkorte titel van het tijdschrift (schuingedrukt), het jaartal, publicatienummer, afleveringsnummer en paginabereik.
Bronvermelding voor een tijdschriftBauw, Van Dijk & Van Delden, NJ 2007/82
E. Bauw, F. van Dijk & A.H. van Delden, ‘Kwaliteit van rechtspraak’, NJ 2007/82, afl. 3, p. 144-151.
De voetnoot voor een boek bevat de achternamen van de auteurs, het jaartal en eventueel een paginanummer. De bronvermelding in de literatuurlijst bevat de initialen en achternamen van de auteurs, de titel en eventuele ondertitel van het boek (schuingedrukt), de plaats en naam van de uitgever en het jaartal.
Voorbeeld: Bronvermelding voor een boekVan Drongelen & Fase 2004, p. 178
J. van Drongelen & W.J.P.M. Fase, CAO-recht. Het recht met betrekking tot CAO’s en de verbindendverklaring en onverbindendverklaring van bepalingen ervan, Deventer: Wolters Kluwer 2004.
Als je naar een bron verwijst met een, twee of drie auteurs, vermeld je alle auteursnamen in de voetnoot en in de bronvermelding.
Voorbeeld: Bronvermelding met drie auteursAl Hamad, Neeltjes & Gjoka 2021, p. 34
H.S. al Hamad, J.L.L.C. Neeltjes & A. Gjoka, Recht van spreken, Dokkum: Juridische Pers 2021.
Als je naar een bron verwijst met vier of meer auteurs, vermeld je alleen de eerste auteursnaam, gevolgd door ‘e.a.’. Dit geldt zowel voor de voetnoot als de bronvermelding in de literatuurlijst.
Voorbeeld: Bronvermelding met vier of meer auteursFelixen e.a. 2020, p. 198
W.A.C. Felixen e.a., Rechtspraak in het digitale tijdperk, Woudsend: Baten juridisch 2020.
Het format voor een voetnoot hangt af van het type bron (zoals een boek, tijdschrift, online bron, jurisprudentie of regeling). Een voetnoot is altijd zo kort mogelijk, maar moet wel essentiële informatie bevatten, zodat lezers een bron kunnen opzoeken.
Een voetnoot begint met een hoofdletter, eindigt met een punt, en bevat meestal de auteursnaam, het jaartal en eventueel de vindplaats (zoals de locatie in een tijdschrift) of een specificering (zoals een paginanummer).
Voorbeeld: Literatuur in de voetnoot
Bacchus 2021, p. 34.
Shevchenko e.a. 2020.
Geertsema e.a., NJB 2021/979
In het geval van jurisprudentie is de verwijzing in de voetnoot veel vollediger, omdat de jurisprudentie in de regel niet wordt opgenomen in een lijst.
Voorbeeld: Jurisprudentie in de voetnootABRvS 14 april 2021, ECLI:NL:RVS:2021:786.
Het format voor een bronvermelding hangt af van het type bron (zoals een boek, tijdschrift of online bron). Een bronvermelding in de literatuurlijst bestaat in ieder geval altijd uit:
een lemma (herhaling van de verkorte verwijzing in de voetnoot: dikgedrukt en zonder punt);
een volledige verwijzing (zonder bijzondere opmaak, met afsluitende punt).
Voorbeeld: Bronvermelding boekDe Hullu 2021, p. 34
J. de Hullu, Materieel strafrecht. Over algemene leerstukken van strafrechtelijke aansprakelijkheid naar Nederlands recht, Deventer: Wolters Kluwer 2021.
De Leidraad wordt vooral gebruikt door redacties van juridische boeken en tijdschriften, juridische auteurs, en door rechtenstudenten en -academici.
De Juridische Leidraad is opgesteld, omdat er een gebrek was aan eenduidige gedragsregels. Hierbij is rekening gehouden met bestaande richtlijnen en de praktijk. Met behulp van de Leidraad kun je volledig en consistent verwijzen. Wij hebben de richtlijnen zo goed mogelijk afgestemd op brongebruik in scripties.
Een ECLI wordt toegevoegd aan rechterlijke uitspraken om ze te nummeren, zodat ze makkelijk kunnen worden opgezocht via de ECLI-zoekmachine. De ECLI bestaat altijd uit dezelfde onderdelen: ECLI:landcode:instantiecode:uitspraakjaar:volgnummer
Een paar voorbeelden van ECLI’s zijn:
ECLI:NL:RVS:2020:2533
ECLI:BE:CASS:2019:ARR.20191119.2N10
ECLI:NL:PHR:2021:80
Je kunt een ECLI beter niet zelf reconstrueren. In plaats daarvan kun je de ECLI opzoeken.
Een jurisprudentielijst is volgens de Leidraad voor juridische auteurs niet nodig, omdat de verwijzingen in een voetnoot al volledig zijn. Als je je toch een jurisprudentielijst toevoegt aan je scriptie, kun je de bronnen het beste sorteren op basis van instantie. Zo vormt de lijst ook direct een jurisprudentieregister.
Volgens de Leidraad voor juridische auteurs hanteer je in dit geval een territoriaal-hiërarchische volgorde (zie onderstaande lijst), waarbij je meerdere bronnen van één instantie chronologisch ordent.
Internationaal Gerechtshof
Internationaal Strafhof
Permanent Hof van Arbitrage
VN-Mensenrechtencomité
Europees Hof voor de Rechten van de Mens
Europese Commissie voor de Rechten van de Mens
Hof van Justitie van de Europese Unie
Gerechten van de Europese Unie
Hoge Raad
Afdeling bestuursrechtspraak van de Raad van State
Centrale Raad van Beroep
College van Beroep voor het bedrijfsleven
Gemeenschappelijk Hof van Justitie van Aruba, Curaçao en Sint-Maarten en van Bonaire, Sint Eustatius en Saba.
Als je verwijst volgens de Leidraad voor juridische auteurs, hoef je in principe geen jurisprudentielijst toe te voegen. De verwijzingen naar jurisprudentie in de voetnoten zijn al volledig, waardoor de lezer de bron goed kan terugvinden. Ook wordt jurisprudentie niet opgenomen in de literatuurlijst.
Als je document erg lang is of als je heel veel naar jurisprudentie verwijst, kun je wel een jurisprudentielijst toevoegen. Verder kan je begeleider aangeven een voorkeur te hebben voor een lijst. Ook in dat geval adviseren we om toch een jurisprudentielijst toe te voegen.
Achternamen hebben vaak een of meerdere tussenvoegsels (of voorvoegsels), zoals:
van, van der, van de
de, den, del
el, al
la, las
Het tussenvoegsel maakt deel uit van de rest van de achternaam, en je sorteert je bronvermeldingen in de literatuurlijstalfabetisch op basis van de achternaam van de eerste auteur.
Literatuurlijst: De Maat, I. (2020). Marketingmodellen in scripties. ART19.
Verwijzing in de tekst: Daarom suggereert De Maat (2020) dat …
Bij verwijzingen wordt de voornaam weggelaten. Daarom krijgen tussenvoegsels in die gevallen een hoofdletter volgens de APA-richtlijnen. Bij een achternaam met meerdere tussenvoegsels krijgt alleen het eerste tussenvoegsel een hoofdletter.
Net als de meeste stijlgidsen raadt APA aan om religieuze boeken op te nemen in de verwijzing in de tekst, in combinatie met het hoofdstuk- en versnummer. Bijvoorbeeld:
(De Nieuwe Bijbelvertaling, 2007, Petr. 3:5)
Titels van religieuze boeken mogen worden verkort om ruimte te besparen. Je kunt hier een lijst met standaardafkortingen voor Bijbelboeken vinden. Paginanummers worden niet gebruikt bij verwijzingen naar religieuze werken.
In de 6de editie van de APA-handleiding werd geadviseerd om voor religieuze werken alleen een verwijzing in de tekst op te nemen en om deze weg te laten uit de literatuurlijst.
Als je een podcastaflevering citeert in APA-stijl, noteer je de host van de podcast als auteur, inclusief een label om de rol te verduidelijken:
Gorgels, K. (Host)
Als je een hele podcastserie citeert en de afleveringen verschillende hosts hebben, noem je de uitvoerend producent. Ook hierbij voeg je een label toe om de rol aan te geven:
Als je een specifiek moment in een video- of audiobron wilt uitlichten, raadt APA aan om een tijdstempel te gebruiken bij je verwijzing in de tekst. Voeg hiervoor de tijdstempel toe waarop het geciteerde deel begint. Bijvoorbeeld:
Als je naar een openbaar bericht op sociale media wilt verwijzen, gebruik je de eerste 20 woorden als titel, voeg je de publicatiedatum toe, neem je een URL op, en noem je de gebruikersnaam van de auteur als diegene er een heeft.
Rijkswaterstaat Verkeersinformatie. [@RWSverkeersinfo]. (2021, 11 maart). Het @KNMI heeft voor vandaag #codegeel afgegeven voor het hele land. Ga je de weg op? Wees dan extra alert [Tweet]. Twitter. https://twitter.com/RWSverkeersinfo/status/1369878958410321921
Als je naar socialemedia-inhoud wilt verwijzen die niet openbaar is (zoals privéberichten, berichten uit besloten groepen of gebruikersprofielen), behandel je de inhoud als persoonlijke communicatie in de lopende tekst. Je neemt hierbij geen bronvermelding op in de literatuurlijst.
Toen de schrijver van de bestseller online werd gecontacteerd, stelde hij dat het schrijfproces voor zijn nieuwe boek “geheel volgens plan” verliep (M. Merkus, privébericht op Twitter, 27 november, 2020).
Copyright-informatie kan meestal worden gevonden op de plek waar de tabellen of figuren zijn gepubliceerd. Stel dat je een diagram uit een wetenschappelijk tijdschrift wilt citeren, dan kun je op de website van het tijdschrift kijken of in de database waar je het artikel hebt gevonden. Afbeeldingen die je vindt op websites zoals Flickr worden gepubliceerd met duidelijke copyright-informatie.
Volgens de APA-stijl vallen alle bronnen die niet kunnen worden geraadpleegd door de lezer onder persoonlijke communicatie. Als jouw bron privé of ontoegankelijk is voor het lezerspubliek van je tekst, dan valt deze onder persoonlijke communicatie.
Veelvoorkomende voorbeelden zijn gesprekken, e-mails, berichten, brieven en interviews of optredens die niet zijn opgenomen.
Gepubliceerde of opgenomen interviews worden wel toegevoegd aan de literatuurlijst. Je citeert ze in het gebruikelijke bronvermelding-format voor dat brontype (bijvoorbeeld een krantenartikel, boek of YouTube-video).
Voeg de DOI toe op het eind van de APA-bronvermelding in de literatuurlijst. Als je de 6de editie van de APA-richtlijnen gebruikt, dan wordt de daadwerkelijke DOI voorafgegaan door het label “doi:”. In de 7de editie wordt de DOI voorafgegaan door “https://doi.org/”.
Voorbeeld van APA-bronvermelding in de literatuurlijst (7de editie)
Hawi, N. S., & Samaha, M. (2016). The relations among social media addiction, self-esteem, and life satisfaction in university students. Social Science Computer Review, 35(5), 576–586. https://doi.org/10.1177/0894439316660340
Als een artikel geen DOI heeft en je het hebt geraadpleegd via een database of in gedrukte versie, dan laat je de DOI weg.
Als een artikel geen DOI heeft en je het hebt geraadpleegd op een website (geen database, maar bijvoorbeeld de website van het tijdschrift zelf), dan voeg je een URL toe waarmee je naar het artikel verwijst.
Als je uit een andere editie citeert dan de eerste (bijvoorbeeld de 2de of een herziene editie), noem je deze in de bronvermelding in de literatuurlijst. Je kort de editie af en zet deze tussen haakjes achter de titel van het boek (bijvoorbeeld 2de ed. of herz. ed.).
Als de hoofdstukken uit een boek door verschillende auteurs zijn geschreven, moet je voor teksten in de APA-stijl het specifieke hoofdstuk citeren.
Als alle hoofdstukken door dezelfde auteur (of groep auteurs) zijn geschreven, kun je het hele boek citeren, zelfs als je citeert of parafraseert uit één hoofdstuk.
Als je een tabel of figuur aanpast of overneemt uit een andere bron, moet je die bron opnemen als bronvermelding in je literatuurlijst. Je moet de originele bron ook noemen in de noot of het bijschrift van je tabel of figuur.
Tabellen en figuren die je zelf hebt gemaakt en die je gebaseerd hebt op je eigen data worden niet opgenomen in je literatuurlijst.
APA schrijft niet voor dat je een lijst van tabellen en figuren moet opnemen. Het kan toch handig zijn om deze toe te voegen als je tekst veel tabellen en/of figuren bevat en lang genoeg is voor een inhoudsopgave.
Een lijst van tabellen en figuren (in die volgorde) komt na je inhoudsopgave en wordt op eenzelfde manier vormgegeven.
In een tekst in APA-stijl gebruik je een tabel of figuur als dit een duidelijkere manier is om belangrijke informatie te presenteren dan wanneer je de informatie zou beschrijven in de hoofdtekst. Dit is vaak het geval als je veel informatie moet overbrengen.
Voordat je tabellen of figuren toevoegt, moet je jezelf altijd afvragen of deze bijdragen aan het begrip van de tekst:
Kan deze informatie kort worden samengevat in de tekst?
Is de informatie belangrijk voor de punten die je wilt maken?
Heeft het figuur of de tabel te veel uitleg nodig om efficiënt te zijn?
Als de data die je wilt presenteren maar enkele relevante getallen bevatten, kun je beter proberen om deze samen te vatten in de tekst (met wellicht een volledige weergave van de data in een bijlage). Als je tekst onnodig lang en moeilijk leesbaar wordt door de beschrijving van je data, kun je beter wel een tabel of figuur toevoegen.
Ja, in het geval van relevante bronnen kan en moet je naar de bronnen verwijzen in je bijlagen. Gebruik hetzelfde auteur-datumsysteem als in de hoofdtekst.
Alle bronnen die je citeert in de bijlage moet je ook opnemen in je literatuurlijst. Maak geen aparte literatuurlijst voor je bijlagen.
Het is het alleen waard om iets toe te voegen als bijlage als je naar informatie uit die bijlage verwijst in je lopende tekst (bijvoorbeeld citeren uit een interviewtranscript). Als je niet naar de bijlage verwijst, dan kun je deze beter verwijderen (tenzij je instructies anders voorschrijven).
Populaire tekstverwerkers, zoals Microsoft Word en Google Docs, kunnen lijsten alfabetisch rangschikken, maar ze volgen hierbij niet de APA-stijl richtlijnen voor alfabetisering.
Als je Scribbrs APA Generator gebruikt om bronvermeldingen te genereren, dan worden je deze automatisch gerangschikt op basis van de APA-richtlijnen voor de literatuurlijst. Hierbij wordt rekening gehouden met alle uitzonderingen.
De samenvatting moet de focus leggen op jouw originele onderzoek en niet op de publicaties van anderen.
De samenvatting moet op zichzelf staan en volledig te begrijpen zijn zonder naar andere bronnen te verwijzen.
Er zijn omstandigheden waarin je wel andere bronnen moet noemen in een samenvatting. Voorbeelden hiervan zijn onderzoeken die een directe reactie of vervolg vormen op een andere studie of onderzoeken die focussen op het werk van een bepaalde theoreticus. Over het algemeen geldt echter dat je geen verwijzingen toevoegt, tenzij het absoluut noodzakelijk is.
Een samenvatting in APA-stijl heeft een lengte van ongeveer 150 tot 250 woorden. Vergeet niet om altijd te kijken naar de richtlijnen van het tijdschrift waarin je wilt publiceren en overschrijd het aangegeven maximale woordenaantal niet.
Hulp nodig bij het samenvatten van je tekst? Gebruik Scribbrs samenvatter om gratis een handige samenvatting te maken.
Een samenvatting weergeeft kort de strekking van een academische tekst (zoals een artikel uit een wetenschappelijk tijdschrift of een scriptie). Dit tekstonderdeel heeft twee hoofddoelen:
De samenvatting helpt potentiële lezers om te beoordelen hoe relevant jouw tekst is voor hun onderzoek.
De samenvatting bevat de belangrijkste bevindingen voor lezers die geen tijd hebben om je hele tekst te lezen.
Samenvattingen en bijbehorende sleutelwoorden worden vaak in academische databases getoond, zodat je publicatie makkelijker kan worden gevonden. Aangezien de samenvatting het eerste is wat lezers zien, is het belangrijk dat deze de inhoud van je tekst duidelijk en juist samenvat.
Hulp nodig bij het samenvatten van je tekst? Gebruik Scribbrs samenvatter om gratis een handige samenvatting te maken.
De APA-opmaak wordt veel gebruikt door professionals, onderzoekers en studenten.
Zorg ervoor dat je de richtlijnen van je universiteit of van het tijdschrift waarin je publiceert bekijkt om te controleren welke stijl je moet gebruiken.
Ja, je voegt paginanummers toe op alle pagina’s, inclusief de titelpagina, inhoudsopgave en literatuurlijst. Paginanummers moeten rechts worden uitgelijnd in de koptekst op de pagina.
Om paginanummers toe te voegen in Microsoft Word of Google Docs klik je op “Invoegen” en dan op “Paginanummers”.
Volgens de APA-opmaakrichtlijnen moet je tekst worden geschreven in een leesbaar en breed toegankelijk lettertype. Voorbeelden hiervan zijn:
Times New Roman (12)
Arial (11)
Calibri (11)
Georgia (11)
Je gebruikt hetzelfde lettertype en dezelfde lettergrootte in je gehele document. Dit geldt ook voor de running head, paginanummers, koppen en literatuurlijst. De tekst in voetnoten en figuren mag kleiner zijn en hierbij mag ook enkele regelafstand worden gebruikt.
De makkelijkste manier om je tekst op te maken volgens APA-richtlijnen is door Scribbrs gratis APA-opmaak sjabloon te downloaden. Je kunt ook kijken naar ons artikel over APA-opmaak met voorbeelden.
Om op de juiste wijze een precieze definitie of argument te presenteren
Gebruik niet te veel citaten, want jouw eigen stem moet het sterkst aanwezig zijn. Als je simpelweg informatie wil geven uit een bron is het meestal beter om te parafraseren of samen te vatten.
Volg deze regels om een citaat op te nemen in je tekst in APA-stijl:
Citaten van minder dan 40 woorden worden tussen dubbele aanhalingstekens geplaatst (met het eindpunt als leesteken buiten de aanhalingstekens na de bronvermelding).
Citaten van 40 woorden of meer worden opgemaakt als een blokcitaat.
De auteur, het jaar en het paginanummer worden toegevoegd aan de verwijzing in de tekst.
Als een artikel meer dan 20 auteurs heeft, vervang je de namen tussen de 19de auteur en de laatstgenoemde auteur door een beletselteken (. . .), maar je laat de laatste auteur niet weg:
De Bruin, T. C., Maartens, J. R., Wilgers, G. L., Evers, B. B., Kelfkens, R. S., Turner, S. T., Abdullahi, A., Daniels, A. T., Hogenbosch, J., Schaars, L., De Wit, A., Strik, T., De Graaf, J. E., Kippersluis, C., Ourahou, S., Megens, M. D., Van der Vaart, R., Philips, T. F. G., Duinkerken, E., . . . Mertens, L.
Volgens de 7de editie van het APA-stijlhandboek is informatie over de locatie van een uitgever niet meer nodig. De 6de editie schreef wel voor om de stad en het land waar de uitgever gevestigd is te noemen, maar dit is niet langer het geval.
Bij een APA-verwijzing in de tekst gebruik je de zinsnede “geciteerd in” als je een indirecte bron wilt citeren (bijvoorbeeld als je de originele bron niet kunt vinden).
Verwijzing tussen haakjes: (De Bruin, 1998, geciteerd in Megens, 2019).
Narratieve verwijzing: De Bruin (1998, geciteerd in Megens, 2019) stelt dat …
In de literatuurlijst voeg je alleen de secundaire bron toe (Megens, 2019).
Voeg altijd een paginanummer toe aan de APA-verwijzing in de tekst als je direct citeert uit een bron. Voeg geen paginanummers toe als je verwijst naar een publicatie als geheel, bijvoorbeeld een boek of een volledig wetenschappelijk artikel uit een tijdschrift.
Als je bron geen paginanummers heeft, kun je een alternatieve plaatsaanduiding toevoegen, zoals een tijdstempel, hoofdstuktitel of paragraafnummer.
In plaats van de achternaam van de auteur, voeg je de eerste paar woorden van de publicatietitel toe bij de verwijzing in de tekst. Zet de titel tussen dubbele aanhalingstekens als je een artikel, webpagina of hoofdstuk uit een boek citeert. Schrijf de titel van tijdschriften, boeken en rapporten schuingedrukt.
Geen publicatiedatum
Als de publicatiedatum onbekend is, gebruik je “z.d.” (zonder datum). Bijvoorbeeld: (Jagers, z.d.).
Volgens de Amerikaanse APA-richtlijnen hoef je alleen een raadpleegdatum toe te voegen als je verwijst naar websites of online artikelen die waarschijnlijk zullen veranderen na verloop van tijd. In de praktijk is het heel lastig om vast te stellen of je met een veranderlijke website te maken hebt, dus daarom raden we aan om altijd een raadpleegdatum op te nemen voor online bronnen zonder DOI of stabiele URL.
Dit kun je doen door het volgende toe te voegen op het eind van de bronvermelding:
Geraadpleegd op 16 januari 2023, van https://www.scribbr.nl/handleiding-apa-regels/
De afkorting “et al.” (die “en anderen” betekent) wordt gebruikt om verwijzingen in de tekst met drie of meer auteurs in te korten. Dat werkt als volgt:
Je gebruikt alleen de achternaam van de eerste auteur, gevolgd door “et al.”, een komma en het publicatiejaar. Een voorbeeld is: (Verstraten et al., 2020).
Als je een specifieke passage uit een bron citeert of parafraseert, moet je de plaats van die passage aangeven in je verwijzing in de tekst. Als er geen paginanummers zijn (bijvoorbeeld als je naar een website verwijst), maar de tekst wel lang is, kun je sectiekoppen, paragraafnummers of een combinatie van de twee gebruiken:
(Abels, 2021, Resultatensectie, par. 1).
Sectiekoppen kunnen worden ingekort als dat nodig is. Kindle plaatsnummers kunnen niet worden gebruikt bij het citeren van een e-book, omdat deze onbetrouwbaar zijn.
Als je verwijst naar de bron als geheel is het niet nodig om een paginanummer of andere plaatsaanduiding te vermelden.
Gebruik de naam van de organisatie op de plaats van de auteur in bronvermeldingen in de literatuurlijst en verwijzingen in de tekst, indien de naam van de auteur niet wordt genoemd, maar de bron duidelijk kan worden toegeschreven aan een specifieke organisatie (zoals een persbericht van een goed doel, een rapport van een bureau of een webpagina van een bedrijfswebsite).
Als de auteur niet kan worden bepaald (zoals bij een Wikipedia-pagina die door meerdere mensen is bewerkt of bij een anoniem gepubliceerd online artikel), gebruik je de titel op de plaats van de auteur. Bij de verwijzing in de tekst zet je de titel tussen dubbele aanhalingstekens als je voor de bronvermelding in de literatuurlijst geen opmaak gebruikt, en je gebruikt cursivering in de tekst als de titel ook schuingedrukt wordt in de literatuurlijst. Indien nodig kort je de titel in.
Bij reproductie van een onderzoek worden alleen de data-analyses opnieuw gedaan met de bestaande data, terwijl bij replicatie het gehele onderzoek op dezelfde manier wordt herhaald door ook nieuwe data te verzamelen.
Een onderzoek is repliceerbaar (of herhaalbaar) als iemand een onderzoek opnieuw uitvoert volgens dezelfde methode en op basis van de nieuwe data dezelfde resultaten behaalt.
De 7e editie, gepubliceerd in 2019, is de meest recente editie van de APA-handleiding. De 6e editie, gepubliceerd in 2009, wordt echter nog steeds door veel hogescholen, universiteiten en uitgevers gebruikt.
De Engelstalige APA-handleiding (7e editie) is te koop bij bol.com als een hardcover, paperback of spiraalgebonden versie. Je kunt ook een e-boekversie kopen bij RedShelf.
Scribbr heeft daarnaast een uitgebreide handleiding gemaakt genaamd ‘De Nederlandse APA-regels volgens de 7e editie’. Hierin hebben we de nieuwe richtlijnen aangepast naar het Nederlands. De handleiding is gratis te downloaden!
De APA verwacht dat de meeste onderwijsinstellingen de 7e editie in het voorjaar van 2020 gaan gebruiken. Neem contact op met je begeleider of kijk op de website van het wetenschappelijk tijdschrift waarin je wilt publiceren om te zien welke APA-richtlijnen jij moet aanhouden.
Je kunt beter geen ‘waarom’-vraag opstellen voor de hoofdvraag van je scriptie (maar ook liever niet voor deelvragen), omdat deze vragen vaak niet specifiek genoeg zijn. Je kunt dan beter nog meer vooronderzoek doen en de vraag anders formuleren.
Je deelvragen worden zo in chronologische volgorde (van 1 tot bijvoorbeeld 5) beantwoord. Als je eerst antwoord geeft op deelvraag 3 en daarna pas op 1, dan is de volgorde nog niet logisch.
Nee, je kunt meerdere type onderzoeksvragen formuleren om antwoord te krijgen op je hoofdvraag. Het is van belang dat je deelvragen helpen je hoofdvraag te beantwoorden en dat je in staat bent om het benodigde onderzoek hiervoor te verrichten.
Op basis hiervan bepaal je welk soort onderzoeksvragen je moet stellen om je hoofdvraag te beantwoorden.
Ja, je hoofdvraag kan een beschrijvende onderzoeksvraag zijn, maar op voorwaarde dat de onderzoeksvraag complex genoeg is waardoor hiervoor daadwerkelijk een onderzoek nodig is. Dit betekent dat het antwoord op die vraag niet voorhanden mag liggen. Dan heeft het immers geen nut om hier een onderzoek voor uit te voeren.
Toets zelf hoe goed je onderzoeksvragen zijn met onderstaande lijst vragen. Alleen als het antwoord ‘ja’ is op iedere vraag, zijn ze waarschijnlijk goed:
Zijn ze niet te makkelijk en is daadwerkelijk onderzoek nodig om ze te beantwoorden?
Heb je steeds ‘ja’ geantwoord? Vraag dan nog aan een of twee medestudenten om feedback en suggesties. Bespreek tot slot je onderzoeksvragen met je begeleider.
In dit geval kun je de volgende stappen nemen om een goede samenvatting te schrijven:
Schrijf per hoofdstuk (of onderdeel) 2 tot 3 zinnen die het hoofdstuk samenvatten.
Plaats deze zinnen achter elkaar en lijm de tekst aan elkaar met verbindingswoorden.
Lees de samenvatting nog eens door (en laat het doorlezen door een studiegenoot), vul informatie aan en verwijder overbodige informatie. Herschrijf hierna de tekst waar nodig.
Voer de laatste wijzigingen door en laat eventueel je samenvatting nakijken door een Scribbr-editor.
Hulp nodig bij het samenvatten van je tekst? Gebruik Scribbrs samenvatter om gratis een handige samenvatting te maken.
Je kunt je samenvatting of abstract inkorten door overbodige informatie te schrappen, te focussen op je eigen onderzoek (vermijd lange discussies over andere bronnen) en omslachtige en overdreven lange zinnen te vermijden.
Hulp nodig bij het samenvatten van je tekst? Gebruik Scribbrs samenvatter om gratis een handige samenvatting te maken.
Een abstract is simpelweg de Engelse benaming voor een samenvatting. Het enige verschil is dat een abstract vaak nog korter moet zijn dan een samenvatting (tussen de 150 en 300 woorden). Sommige opleidingen vragen ook van je om bij de abstract sleutelwoorden te plaatsen.
Hulp nodig bij het samenvatten van je tekst? Gebruik Scribbrs samenvatter om gratis een handige samenvatting te maken.
Doorgaans gebruik je geen steekproef als je kwalitatief onderzoek verricht. Ook gebruik je nooit een steekproef als je onderzoekspopulatie zo klein is dat je simpelweg alle personen die hiertoe behoren kunt ondervragen. Dit is mede afhankelijk van je onderzoeksmethode.
Om de volgende redenen kun je een steekproef gebruiken:
als de omvang van de populatie te groot is om alle elementen te meten
als snelheid gewenst is, waardoor niet de hele populatie onderzocht kan worden
als het te kostbaar is om een groot aantal metingen uit te voeren
Deze drie redenen gelden eigenlijk altijd voor een scriptie, tenzij de onderzoekspopulatie heel klein is. Je steekproef dient ertoe geldende uitspraken te doen over de gehele onderzoeksgroep (aselecte steekproef) of de selectie die je hebt gemaakt (selecte steekproef).
Je gebruikt een steekproef uitsluitend wanneer je kwantitatief onderzoek verricht. Je kunt met een steekproef onderzoek doen naar allerlei onderwerpen, zowel personen, groepen, fenomenen als bestaande gegevens.
Als je onderzoeksresultaten niet valide zijn en je de validiteit dus niet kunt bewijzen, dan geef je dit aan in de beperkingen in je discussie. Er is dan sprake van systematische fouten (research bias) in je studie.
Als je hierdoor concludeert dat je op basis van je bevindingen geen harde conclusies kunt trekken, dan lever je toch een bijdrage aan de bestaande wetenschappelijke en praktische kennis. Op basis van jouw onderzoek kan in vervolgonderzoek deze systematische fout vermeden worden om wel tot valide resultaten te komen.
Je kunt met kwalitatief onderzoek niet de externe validiteit aantonen. Of je de criteriumvaliditeit en ecologische validiteit moet aantonen is afhankelijk van je studierichtlijnen. Beschrijf of de validiteit is gewaarborgd in je methodologie of je discussie.
Bij validiteit gaat het om het meten wat je beoogt te meten. Bij betrouwbaarheid daarentegen gaat het om de vraag of je onderzoeksresultaten hetzelfde zouden zijn als je het onderzoek op dezelfde wijze nogmaals uitvoert.
Je mag je deelvragen niet letterlijk herhalen in de conclusie, omdat je conclusie dan lang en onoverzichtelijk wordt. In dit hoofdstuk richt je je voornamelijk op de hoofdvraag. Eventueel kun je kort verwijzen naar de antwoorden op de deelvragen.
Of je jouw conclusie kan generaliseren, is afhankelijk van het soort onderzoek dat je hebt uitgevoerd.
Als je bij kwalitatief onderzoek bijvoorbeeld na 7 interviews steeds dezelfde antwoorden krijgt (verzadiging of saturatie), kun je stellen dat de antwoorden hetzelfde zouden zijn als je nog eens 10 personen van dezelfde onderzoeksgroep zou interviewen. In dat geval mag je jouw bevindingen over die specifieke onderzoekspopulatie generaliseren.
Bij kwantitatief onderzoek is het van belang dat je voldoende personen bevraagt. Gebruik een steekproefcalculator om te bepalen hoe groot jouw steekproef moet zijn. Zo moet je bijvoorbeeld minstens 278 enquêtes afnemen als je een uitspraak over een populatie van 1000 personen wilt generaliseren.
Als je onderzoek niet valide en betrouwbaar blijkt te zijn of je resultaten eigenlijk tot niets hebben geleid, kun je hier nog steeds een conclusie over trekken. Zo kun je concluderen dat je met jouw onderzoeksmethoden hierover geen valide conclusie kunt trekken of kun je aangeven dat deze resultaten geen direct antwoord geven op je hoofdvraag.
Op basis van deze informatie weten studenten voor vervolgonderzoek dat ze het op een andere manier moeten aanpakken! Zo heb je nog steeds bijgedragen aan de bestaande kennis.
Stel jezelf de volgende vragen om te evalueren of je conclusies trekt of aan het samenvatten bent:
Geef je duidelijk antwoord op je hoofd- en deelvragen (deelconclusies) inclusief onderbouwing?
Top! Dit is een conclusie.
Geef je aan welke resultaten je hebt gevonden en leg je nog eens uit hoe je hiertoe gekomen bent? Pas op! Het lijkt erop alsof je aan het samenvatten bent.
Als uit jouw onderzoek geen concrete oplossing naar voren is gekomen dan kun je geen implementatieplan hierover schrijven. In dit geval is het van belang om verder onderzoek te doen wanneer jij per se een implementatieplan moet opleveren.
Dit kan bijvoorbeeld gebeuren omdat je onvoldoende inzicht hebt verkregen in het probleem of erachter bent gekomen dat het probleem ergens anders door veroorzaakt wordt dat niet behoort tot jouw vakgebied.
Je implementatieplan wordt zowel gelezen door je studiebegeleider als je opdrachtgever. Als je opdrachtgever vervolgens tevreden is over het plan en jouw oplossing wilt doorvoeren, zal hij of zij jouw implementatieplan doorspelen naar de verantwoordelijken en andere betrokkenen die je ook in jouw implementatieplan hebt besproken.
Je implementatieplan moet daarom leesbaar en duidelijk zijn voor een breed publiek.
De lengte van een implementatieplan varieert van ongeveer 7 tot 20 pagina’s lang. Ga na bij jouw studiebegeleider hoe lang deze ongeveer moet zijn en welke onderdelen je hierin moet opnemen.
Je implementatieplan is het liefst kort, bondig en duidelijk om zo effectief mogelijk te zijn. Hoe bondig een implementatieplan kan zijn, hangt af van het aantal activiteiten dat uitgevoerd moet worden en de complexiteit van de implementatie wat betreft de organisatie, communicatie en planning.
Je schrijft een implementatieplan in aanvulling op je onderzoek en eventueel ook je adviesrapport als je opdrachtgever en/of studiebegeleider dit van je verlangt.
Voordat je begint aan het onderzoekstraject, spreek je al met je opdrachtgever en studiebegeleider af welke producten je moet gaan verzorgen (stageverslag, scriptie, adviesrapport, productontwerp, implementatieplan).
Heb je niet met je opdrachtgever en/of studiebegeleider van tevoren afgesproken dat je een implementatieplan moet opleveren? Dan is de kans groot dat je dit niet hoeft te doen. Vraag dit wel nog even na, voordat je al jouw producten moet opleveren.
Een doel is meetbaar met behulp van een bepaald systeem, bepaalde methode of procedure om cijfermatig te bepalen in hoeverre je het doel op een bepaald moment bereikt hebt. Je kunt zonodig een nulmeting doen om de startsituatie te bepalen, zodat duidelijk is met welk percentage of met welk aantal de situatie is verbeterd in vergelijking met deze startsituatie.
Wanneer je een doel met geen mogelijkheid meetbaar kunt maken, kan het zijn dat je jouw doel niet SMART kunt formuleren. Ga dan na of mogelijk een onderdeel van je doel wel meetbaar kan zijn. Zo kun je ‘betere communicatie’ niet meten, maar het aantal likes over de klantenservice op de Facebookpagina wel.
Acceptabel (of Aanvaardbaar) is de meest gangbare uitleg. Als je een leerdoel formuleert, kies dan voor Acceptabel. Ook als het van belang is dat er draagvlak is voor het doel, kies je voor Acceptabel.
Als je doel voornamelijk moet leiden tot acties, kies dan voor Actiegericht. Is het belangrijk dat je doel daadwerkelijk leidt tot een verandering, bijvoorbeeld binnen bedrijf? Kies dan voor Ambitieus. En mocht het belangrijk zijn dat het duidelijk is wie het doel moet bewerkstelligen, kies dan voor Aanwijsbaar.
Niet alle doelen kunnen SMART geformuleerd worden. Formuleer kortetermijndoelen met een duidelijke einddatum en meetbare resultaten SMART om je te helpen je doelstelling te behalen.
Langetermijndoelen zonder einddatum bij concepten die moeilijk tot onmogelijk meetbaar gemaakt kunnen worden, kunnen niet SMART geformuleerd worden.
Door (leer)doelen SMART te formuleren, maak je het voor jezelf en eventueel de organisatie waarvoor je werkt of het onderzoek doet, eenvoudiger om deze doelen te behalen.
Een SMART-geformuleerde doelstelling leidt tot een duidelijk en haalbaaractieplan waar voldoende draagvlak voor is, wat niet alleen handig is, maar ook jezelf en medewerkers kan motiveren.
Bovendien weet je op de afgesproken datum ook daadwerkelijk of het doel behaald is, doordat dit meetbaar is. Naar aanleiding hiervan kun je weer nieuwe SMART-(leer)doelen opstellen zodat jezelf of je organisatie door kan ontwikkelen en kan blijven verbeteren.
Als resultaten antwoord geven op een deelvraag, -hypothese of de onderzoeksvraag en/of significant inzicht bieden in een deelonderwerp, dan zijn deze resultaten relevant.
Uiteindelijk dienen de resultaten die je in dit hoofdstuk beschrijft te leiden tot het antwoord op je hoofdvraag dat je in je conclusie geeft.
In je theoretisch kader geef je antwoord op de beschrijvende deelvragen die je hebt geformuleerd en ga je dieper in op de begripsdefinities die je gebruikt, zodat je lezer nog beter begrijpt wat jouw resultaten en conclusie uiteindelijk betekenen en waar deze precies betrekking op hebben.
Naar hoeveel verschillende auteurs je verwijst in je theoretisch kader is afhankelijk van de beschikbare literatuur over jouw onderwerp. Houd er hierbij ook rekening mee dat de meeste studies van je verlangen dat je recente bronnen gebruikt, oftewel bronnen die niet ouder zijn dan 10 jaar. Het is vooral van belang dat je studies gebruikt die relevant zijn voor jouw onderwerp en bijdragen aan de wetenschappelijke onderbouwing van jouw onderzoek.
Ja, als deze definities en modellen relevant zijn voor je onderwerp en het van belang is dat je uitlegt waarom je deze niet gebruikt, kun je deze definities en modellen ook in je theoretisch kader beschrijven.
Je toont hiermee aan dat je op de hoogte bent van verschillende definities en modellen en dat je bewust kiest voor andere definities en modellen die beter passen bij jouw onderzoek.
Ja en nee. In het theoretisch kader van je plan van aanpak ga je in op de belangrijkste begrippen, theorieën en modellen die met je onderwerp te maken hebben. Je legt hierbij uit wat deze inhouden en gaat daarna vooral in op waarom deze voor jouw onderzoek relevant zijn (welke deelvraag je hiermee kunt beantwoorden bijvoorbeeld).
Je geeft in het theoretisch kader van je PvA nog geen antwoord op beschrijvende deelvragen, terwijl je dit in je scriptie wel doet.
Ja, deze richtlijnen gelden ook voor een discussie in een academisch paper, oftewel andere wetenschappelijke teksten dan scripties. Ga wel altijd na wat in jouw studierichtlijnen precies van je verlangd wordt met betrekking tot je discussie.
Een discussie is vaak niet veel langer dan anderhalve pagina. Dit is natuurlijk ook afhankelijk van de lengte van je onderzoek. In verhouding tot je onderzoek is je discussie meestal twee keer zo lang als je conclusie.
Helaas zijn niet alle opleidingen en onderwijsinstellingen het erover eens wat in een discussie beschreven moet worden. Sommige onderwijsinstellingen verlangen zelfs van je dat je in je discussie een conclusie geeft en in je conclusie een advies beschrijft, bijvoorbeeld in een adviesrapport.
Lees daarom altijd grondig jouw studierichtlijnen door om erachter te komen wat je precies in je discussie moet bespreken. Onze richtlijnen zijn gebaseerd op de algemene regels voor een discussie in een wetenschappelijk onderzoek.
Als je een wetenschappelijk onderzoek hebt gedaan voor de universiteit, dan is de discussie een verplicht onderdeel. Hierin kun je dieper ingaan op de resultaten. Het is hierin vooral van belang dat je de validiteit van je onderzoek beargumenteert, de beperkingen van je onderzoek beschrijft en suggesties presenteert voor vervolgonderzoek.
Het is echter niet altijd verplicht om je discussie als een apart hoofdstuk toe te voegen. Soms is het ook een paragraaf van je conclusie.
Bij sommige hbo-opleidingen hoef je geen discussie toe te voegen aan je scriptie. Ga na of jij dit wel moet doen, of niet.
Als je de structuur van een onderzoeksstage-verslag ziet, lijkt het veel op een scriptie. Dat klopt! Een stageverslag voor een onderzoeksstage is gedeeltelijk een soort scriptie in het klein, maar is wel degelijk verschillend.
De verschillen zijn de volgende:
Het onderzoek voor de onderzoeksstage en het verslag zelf zijn minder uitvoerig dan een scriptie.
Je docent is niet iedere dag bij jou terwijl je stage loopt en heeft ook niet voortdurend contact met je stagebegeleider. Enkel op basis van het rapport van jouw stagebegeleider en vooral op basis van jouw stageverslag kan je docent je stage beoordelen.
Je docent let hierbij op de volgende aspecten:
Of je stagewerkzaamheden aansluiten op je studie.
Of je de juiste leerdoelen hebt opgesteld en deze hebt behaald.
Hoe je je binnen het stagebedrijf en tijdens de stage hebt ontwikkeld.
Of je voldoende inzicht hebt verkregen in je stagebedrijf in je bedrijfsomschrijving en brancheomschrijving en of je hierbij op de juiste manier de juiste modellen hebt toegepast.
Of je op objectieve wijze je eigen handelen en gedrag kunt evalueren.
Je schrijft een stageverslag om aan je docent en stagebegeleider te laten zien wat je geleerd hebt, wat je gedaan hebt en hoe je je hebt ontwikkeld. Je toont hiermee aan dat je begrijpt hoe het stagebedrijf werkt en hoe je meer relevante praktijkkennis hebt gedaan in de lijn van jouw studie.
Als je een onderzoeksstage doet, laat je bovendien zien dat je een valide onderzoek kunt doen en helpen je onderzoeksresultaten meer inzicht te krijgen in het onderzoeksprobleem waarmee je stagebedrijf kampt.
Je schrijft een stageverslag nadat je de stage hebt afgerond of als je in de afrondende fase bent. Tijdens je stage is het wel een goed idee om alvast sommige onderdelen te schrijven. Zo kun je de vrij snel schrijven over het stagebedrijf, de omgeving en de stageopdracht, maar kun je pas aangeven welke werkzaamheden je daadwerkelijk hebt verricht en deze evalueren aan het einde van je stage.
Het verschil tussen een stageverslag en een reflectieverslag is groot. In je stageverslag is een reflectie (of een evaluatie) slechts een onderdeel van het verslag en beschrijf je de gehele stageperiode, het stagebedrijf en zijn omgeving, je stageopdracht en werkzaamheden en verbind je hier een conclusie aan.
In je reflectieverslag daarentegen ga je enkel in op betekenisvolle situaties en bespreek je die zeer uitvoerig. Je focust hierbij vooral op je eigen ontwikkeling en gevoel.
Nee, er zijn geen functies verwijderd. Het is bijvoorbeeld nog steeds mogelijk om de taal van de bronvermeldingen aan te passen of om de verwijzing in de tekst te kopiëren.
Ons doel is om het citeren van bronnen zo gemakkelijk en nauwkeurig mogelijk te maken. We zijn ervan overtuigd dat de nieuwe APA Generator hierin nu veel beter is dan de oude versie.
Honderdduizenden studenten gebruiken de nieuwe versie al en we denken dat het tijd is dat iedereen ermee aan de slag gaat!
Het komt vaak voor dat je gegevens mist bij internetbronnen. Bij de APA Generator kun je deze invulvelden dan gewoon overslaan. De bron wordt altijd op de juiste wijze gegenereerd.
Wij raden aan om een intranetbron in je scriptie te behandelen als een normale internetbron.
Een korte verwijzing in de tekst en volledig opnemen in je literatuurlijst. Daarnaast vermeld je door middel van een voetnoot dat de bron niet publiekelijk toegankelijk is.
De APA-stijl geeft aan dat je bij een vertaling niet langer meer van een citaat spreekt maar van een parafrase.
Je behandelt de bron als een normale parafrase en plaatst dus geen aanhalingstekens. In de literatuurlijst schrijf je eerst de originele titel op en hierna plaats je tussen blokhaken ‘[]’ de vertaalde titel.
Als je veel gebruikmaakt van bronnen, moet je hiernaar vaak verwijzen in je tekst. Het uitgangspunt is dat je beter te vaak naar een bron kunt verwijzen dan te weinig.
Het moet voor de lezer van je scriptie in een oogopslag duidelijk zijn of de informatie van een bron afkomstig is.
Wanneer je naar een bron wilt verwijzen die in een andere bron wordt gebruikt dan raden we je aan om de originele bron op te zoeken. Je kunt dan direct naar de originele bron verwijzen volgens de normale APA-regels.
Als je de originele bron niet kunt vinden dan moet je verwijzen naar deze bron via de andere bron. Dit noem je een indirecte verwijzing of een secundaire bron.
In de verwijzing in de tekst voeg je beide auteurs toe. In de literatuurlijst plaats je alleen de door jou geraadpleegde bron.
Voorbeeld: Driessen (geciteerd in Swaen, 2014) maakt gebruik van drie methodes.
Een voetnoot kan om meerdere redenen worden gebruikt. De belangrijkste doelen zijn de volgende:
In de voetnoot plaats je voor sommige referentiestijlen een bronvermelding, zodat de lezer je bron kan controleren. Je voorkomt hiermee dat je plagiaat pleegt. Let op: niet iedere referentiestijl werkt met dit systeem.
Je kunt de voetnoot gebruiken om de lezer meer duidelijkheid te verschaffen over bepaalde keuzes in je hoofdtekst, zonder deze te verstoren.
Je kunt extra informatie toevoegen voor de nieuwsgierige lezer, zoals links naar achtergrondinformatie.
Je kunt afkortingen en begrippen uitleggen als de referentiestijl dit toestaat. Je kunt ook kiezen voor een begrippenlijst.
Een ghostwriter (spookschrijver) is iemand die een tekst schrijft voor iemand anders, vaak tegen betaling. Zelfs als iemand hiervoor betaald wordt, valt dit onder plagiaat en fraude. Het is dan ook niet toegestaan om je scriptie of andere opdrachten te laten ghostwriten.
Een docent kan bij twijfel de examencommissie inschakelen, bijvoorbeeld als je werk sterk afwijkt van andere opdrachten.
In de meeste gevallen hoef je geen bronvermelding toe te voegen als je iets bespreekt dat tot algemene kennis behoort. Hierbij is het wel van essentieel belang dat de informatie echt als algemene kennis kan worden gezien.
Algemene kennis is informatie die de gemiddelde lezer als waar beschouwt zonder de behoefte aan een bronvermelding. Het moet hierbij om bekende, controleerbare en eenduidige kennis gaan.
Let op: Als je twijfelt, kun je beter wel een bronvermelding toevoegen om te voorkomen dat je plagiaat pleegt. Je kunt gebruikmaken van onze APA Generator om automatisch foutloze bronvermeldingen te genereren.
Plagiaat plegen gaat gepaard met serieuze gevolgen en kan illegaal zijn in sommige gevallen.
Plagiaat wordt bijzonder serieus genomen in een professionele academische setting. Zowel plagiaat als zelfplagiaat kunnen leiden tot juridische stappen, omdat vaak sprake is van een schending van auteursrecht of fraude. De meeste wetenschappelijke tijdschriften staan onderzoekers niet toe om hun werk in meerdere tijdschriften of boeken te publiceren.
De gevolgen van plagiaat verschillen per setting en per onderwijsinstelling, maar ze kunnen variëren van een onvoldoende voor een opdracht of vak tot een permanente uitschrijving.
Onbedoeld plagiaat is een van de meest voorkomende soorten plagiaat. Vaak wordt een bronvermelding vergeten of lijkt een parafrase te sterk op het origineel.
Ook als plagiaat per ongeluk gaat, kunnen de gevolgen ernstig zijn. Zorg ervoor dat je nauwkeurig omgaat met bronvermeldingen en gebruik eventueel een (gratis) plagiaat checker voordat je je werk inlevert.
Clone plagiaat (ook wel globalplagiarism genoemd) betekent dat je iemand anders werk kopieert en inlevert onder je eigen naam. Dit is een van de meest ernstige gevallen van plagiaat, omdat je opzettelijk liegt over het auteurschap van een tekst.
Plagiaat is het bedoeld of onbedoeld presenteren van andermans werk of ideeën als je eigen werk of ideeën. Plagiaat is daarmee een schending van het intellectuele eigendom van een ander en kan ernstige gevolgen hebben.
Het is belangrijk dat je je bronnen goed bijhoudt en dat je de juiste bronvermeldingen toevoegt om plagiaat te voorkomen. Maak gebruik van onze APA Generator om automatisch foutloze bronvermeldingen te genereren.
Als de auteur van een publicatie onbekend is, rangschik je de bron op basis van de titel. Negeer hierbij de woorden “de”, “het” en “een” aan het begin van de titel.
De Scribbr Bronnengenerator is ontwikkeld met behulp van het open-source Citation Style Language (CSL)-project en Frank Bennett’s citeproc-js. Het is dezelfde technologie die wordt gebruikt door tientallen andere populaire bronnengenerators, waaronder Mendeley en Zotero.
Je kunt alle citatiestijlen en talen vinden die in de Scribbr Citation Generator worden gebruikt in onze openbaar toegankelijke repository op Github. De meeste referentiestijlen worden door de Bronnengenerator ondersteund. Zo hebben we onder andere een APA Generator en een MLA Generator.
Scribbr gebruikt geavanceerde plagiaatdetectietechnologie die vergelijkbaar is met de software die door de meeste universiteiten en uitgevers wordt gebruikt, waardoor je verzekerd bent van dezelfde of zeer vergelijkbare resultaten.
De add-on AI Detector wordt aangestuurd door Scribbrs eigen software en is in staat om teksten gegenereerd door ChatGPT, Gemini en andere AI-tools met hoge nauwkeurigheid te detecteren.



 .
.

 .
. en
en  .
.


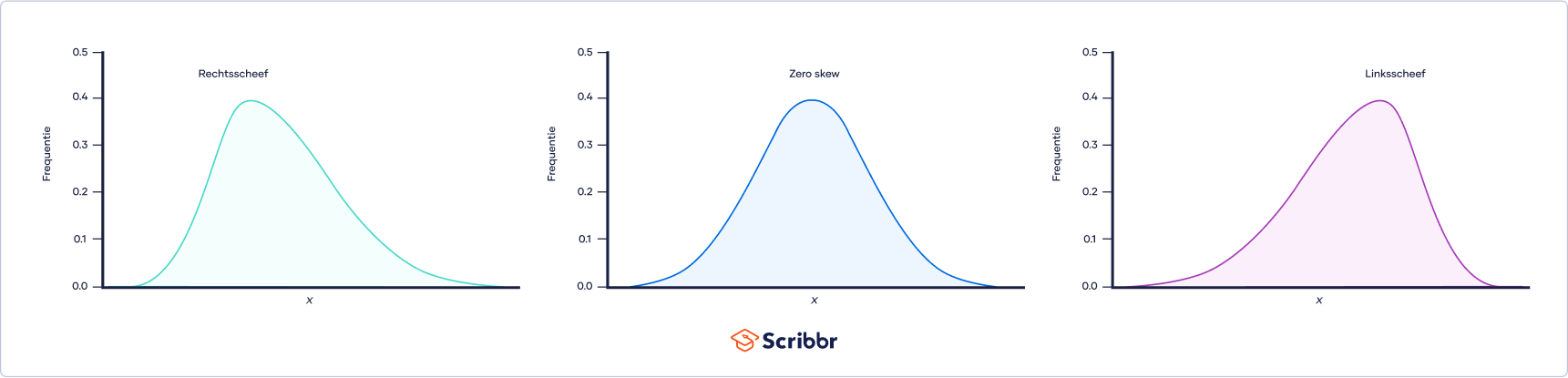
 .
.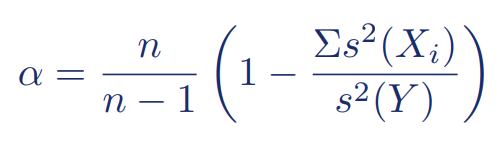
 .
. en
en  .
.