Hoe verzamel en analyseer je ordinale data | Met voorbeelden
Ordinale data kunnen worden verdeeld over categorieën en deze kunnen op een logische, natuurlijke manier worden geordend (zoals beginner, gevorderde, expert). Het is echter onduidelijk of de afstand tussen de categorieën gelijk is. Zo weet je bijvoorbeeld niet of er net zo’n groot verschil zit tussen een beginner en een gevorderde als tussen een gevorderde en een expert.
Een ander voorbeeld is de frequentie waarmee mensen sporten. Je zou hiervoor de volgende categorieën kunnen opstellen:
| 1. Nooit | 2. Zelden | 3. Soms | 4. Vaak | 5. Iedere dag |
Deze categorieën kunnen op een natuurlijke manier worden gerangschikt, maar we weten niet of het verschil tussen “nooit” en “zelden” net zo groot is als het verschil tussen “soms” en “vaak”. Daarom is hier sprake van een ordinale schaal.
Meetniveaus
Het meetniveau geeft aan hoe precies de data zijn verzameld. Er zijn vier meetniveaus: nominaal, ordinaal, interval en ratio. Een hoger meetniveau is altijd complexer en preciezer.
Nominale en ordinale variabelen zijn categorisch, terwijl interval– en ratiovariabelen kwantitatief zijn.
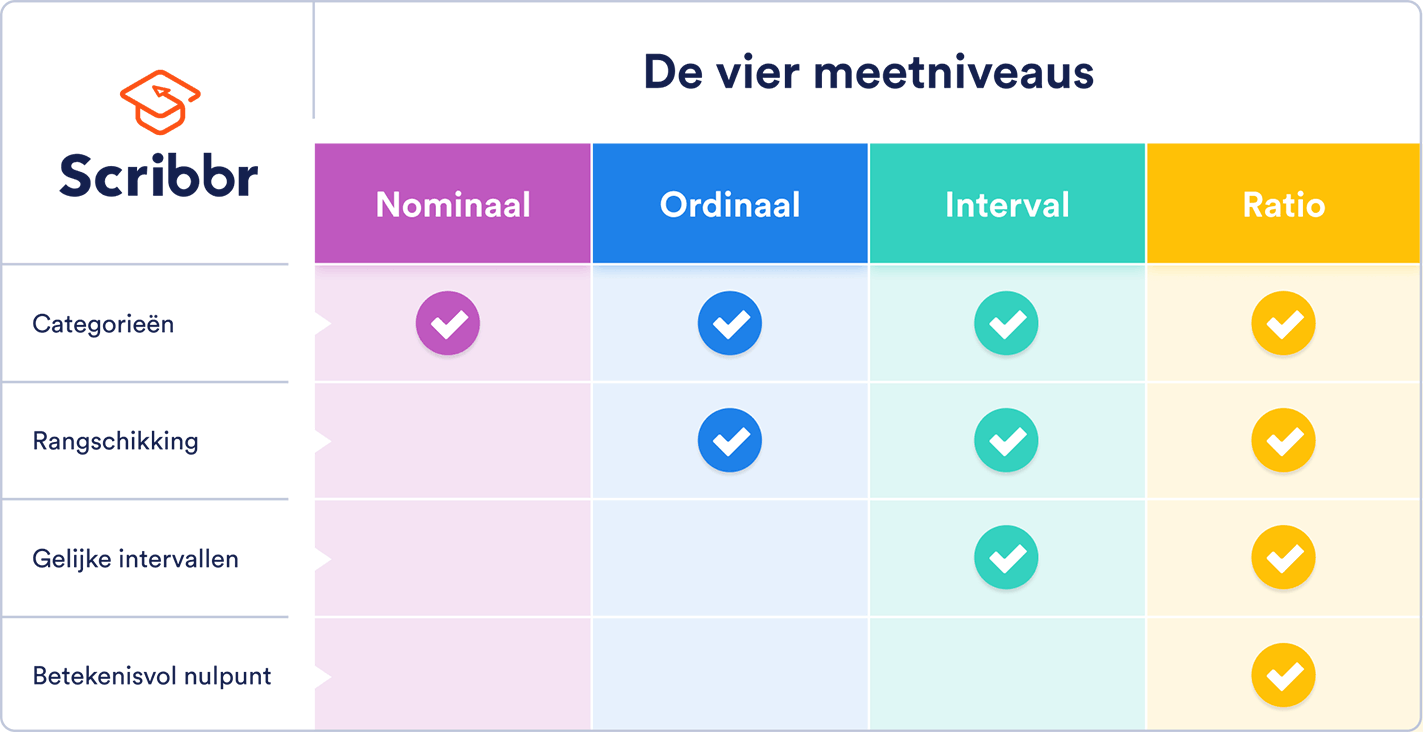
Het nominale meetniveau verschilt van het ordinale meetniveau, omdat nominale data niet kunnen worden gerangschikt. Het ordinale meetniveau verschilt ook van het intervalmeetniveau, omdat de verschillen tussen de opeenvolgende punten bij het intervalniveau wel gelijk zijn.
Voorbeelden van ordinale data
In onderzoeken met ordinale variabelen worden vaak meningen of beoordelingen verzameld. Ook kun je demografische eigenschappen (zoals opleidingsniveau of inkomen) onderzoeken door participanten een ordinale schaal aan te bieden.
| Variabele | Ordinale waarden |
|---|---|
| Taalvaardigheid |
|
| Mate waarin iemand het met iets eens is |
|
| Opleidingsniveau |
|
Hoe verzamel je ordinale data?
Ordinale variabelen worden meestal onderzocht met enquêtes met gesloten (meerkeuze)vragen, waardoor participanten uit enkele opties kunnen kiezen. De enquêtes zijn gebruiksvriendelijk en zorgen ervoor dat je de participanten eenvoudig kunt vergelijken.
| Vraag | Opties |
|---|---|
| Wat is je leeftijd? |
|
| Wat is je opleidingsniveau? |
|
| Hoe vaak heb je de afgelopen 3 maanden online boodschappen gedaan? |
|
Het meetniveau kiezen
Sommige soorten variabelen kunnen meerdere meetniveaus hebben. In dat geval moet je zelf een keuze maken. Een voorbeeld van een variabele met meerdere mogelijkheden is leeftijd:
- Je kunt ordinale data verzamelen door participanten te vragen een leeftijdscategorie (zoals 0-18) te kiezen (zoals bij de voorbeeldvraag).
- Je kunt ook ratiodata verzamelen door participanten om hun exacte leeftijd te vragen.
Het heeft altijd de voorkeur om een preciezer niveau te kiezen, omdat je op die manier meer berekeningen en statistische analyses kunt uitvoeren.
Likertschalen
Ordinale data worden vaak verzameld met behulp van likertschalen. In het geval van een enquêtevraag met likertschaal wordt gebruikgemaakt van een 5- of 7-puntsschaal. Ieder punt correspondeert met een categorie (bijvoorbeeld 1 = helemaal mee oneens en 5 = helemaal mee eens). Participanten kiezen een van de aangeboden opties.
| Hoe vaak koop je duurzame producten? | ||||
|---|---|---|---|---|
| Nooit | Zelden | Soms | Vaak | Altijd |
| Hoe belangrijk vind je het om bij te dragen aan een beter milieu? | ||||
| Niet belangrijk | Een beetje belangrijk | Belangrijk | Erg belangrijk | Heel erg belangrijk |
De antwoordopties kunnen op een natuurlijke manier worden gerangschikt en daarom worden ze vaak omgezet in numerieke waarden, zoals:
- Nooit = 1
- Zelden = 2
- Soms = 3
- Vaak = 4
- Altijd = 5
Het is belangrijk om je te realiseren dat je ook na deze codering niet alle soorten berekeningen kunt uitvoeren. Je kunt de waarden bijvoorbeeld niet bij elkaar optellen en zeggen dat score 1 (nooit) + 2 (zelden) samen score 3 (soms) maken.
Hoe analyseer je ordinale data?
Ordinale data kunnen worden geanalyseerd met descriptieve (beschrijvende) en inferentiële (toetsende) statistiek.
Descriptieve of beschrijvende statistiek
Je kunt de volgende descriptieve statistieken gebruiken in het geval van ordinale data:
- De frequentieverdeling in de vorm van absolute getallen of percentages.
- De modus of mediaan om de centrale tendens (central tendency) te vinden.
- Het bereik (range) om de spreiding aan te geven.
| Regelmatig sporten is belangrijk voor mijn mentale gezondheid. | ||||
|---|---|---|---|---|
| Helemaal mee oneens | Oneens | Neutraal | Eens | Helemaal mee eens |
Om een beeld te krijgen van je data, kun je een frequentietabel maken. Hierin kun je aflezen hoe vaak een bepaalde antwoordoptie werd gekozen.
| Mate waarin iemand het eens is | Frequentie |
|---|---|
| Helemaal mee oneens | 2 |
| Oneens | 2 |
| Neutraal | 8 |
| Eens | 13 |
| Helemaal mee eens | 5 |
Om je data te visualiseren, kun je een staafdiagram maken. Hierbij komen je categorieën op de x-as (horizontaal) te staan en de frequenties op de y-as (verticaal).
Bij ordinale data maakt de volgorde waarin je categorieën aan bod komen op de x-as wel uit (omdat er sprake is van een natuurlijke rangschikking), terwijl je bij nominale data zelf een volgorde kunt kiezen.

Centrummaten
De centrale tendens van je dataset laat zien waar de meeste waarden uit je dataset zich bevinden. De modus, het gemiddelde en de mediaan zijn de drie centrummaten die het vaakst worden gebruikt.
In het geval van ordinale data kan de modus bijna altijd worden bepaald, maar de mediaan kan slechts worden vastgesteld in sommige gevallen.
Het is niet mogelijk om het gemiddelde te berekenen bij ordinale data, omdat je hiervoor diverse berekeningen moet uitvoeren (zoals optellen en delen). Aangezien de verschillen tussen de verschillende categorieën mogelijk niet gelijk zijn, kun je deze berekeningen niet uitvoeren met ordinale data.
De modus is de waarde die het vaakst voorkomt in je dataset. In de huidige dataset werd het vaakst gekozen voor de optie “eens”, dus dat is de modus.
De mediaan kun je vinden door de waarden op volgorde van klein naar groot te zetten en vervolgens op zoek te gaan naar de middelste waarde. Deze methode moet iets worden aangepast als je een even aantal waarden hebt, omdat er dan geen middelste waarde is.
- Bij een dataset met een oneven aantal waarden, zet je alle waarden van klein naar groot. De middelste waarde is de mediaan.
- Stel je waarden zijn: 2, 2, 3, 4, 5 – dan is de middelste waarde de 3, dus dat is de mediaan.
- Bij een dataset met een even aantal waarden, zet je alle waarden van klein naar groot. Aangezien hier geen sprake is van een middelste waarde, bereken je het gemiddelde van de twee waarden in het midden.
- Stel je waarden zijn: 2, 2, 3, 4, 5, 6 – dan zijn je twee middelste waarden 3 en 4. Het gemiddelde hiervan is 3.5, dus dat is de mediaan.
Er zijn 30 waarden (een even nummer), dus je gaat op zoek naar de twee middelste waarden. Beide waarden zijn hetzelfde (“eens”), dus de mediaan is “eens”.
Stel dat de twee waarden in het midden “Eens” en “Helemaal mee eens” waren geweest. In dat geval had je het gemiddelde moeten berekenen, maar dat kan niet bij ordinale data. Als deze situatie zich voordoet, kan de mediaan dus niet worden bepaald.
Spreidingsmaten
Om de spreiding van je data te bepalen, kun je het minimum, maximum en bereik vaststellen. Hiervoor moet je de labels (helemaal mee oneens, oneens, neutraal, eens, helemaal mee eens) omzetten naar numerieke waarden (1, 2, 3, 4 en 5).
- 1 = Helemaal mee oneens
- 2 = Oneens
- 3 = Neutraal
- 4 = Eens
- 5 = Helemaal mee eens
Om de minimum- en maximumwaarde te bepalen, zoek je het laagste en het hoogste getal in je dataset. Het minimum is 1 en het maximum is 5.
Om het bereik te bepalen, bereken je het verschil tussen het maximum en het minimum:
Bereik = 5 – 1 = 4
Het bereik geeft je een idee van de mate waarin de scores van elkaar verschillen. Op basis van deze informatie kun je concluderen dat minimaal 1 iemand voor helemaal mee oneens koos en minimaal 1 iemand voor helemaal mee eens koos.
Statistische analyses
Toetsende statistiek wordt gebruikt om wetenschappelijke hypothesen over je data te toetsen. De meest geschikte toetsen voor ordinale data zijn niet-parametrische toetsen.
Parametrische toetsen worden namelijk enkel gebruikt als je data aan bepaalde voorwaarden voldoen, zoals een normale verdeling. Bij parametrische toetsen gaat het om een vergelijking van gemiddelden, terwijl het bij non-parametrische toetsen vaak om de mediaan of rangschikking gaat.
Er zijn veel soorten toetsen die je kunt gebruiken voor ordinale data. Je keuze hangt onder andere af van je onderzoeksdoel, het aantal steekproeven en het type steekproef.
| Niet-parametrische toets | Doel | Steekproeven of variabelen | Voorbeeld |
|---|---|---|---|
| Moods mediaan-toets (Mood’s median test) | Vergelijkt de medianen | Twee of meer steekproeven | In hoeverre verschillen de gemiddelde inkomens van mensen uit twee aangrenzende steden? |
| Mann-Whitney U-toets of Wilcoxon rank-sum toets (Mann-Whitney U-test) | Vergelijkt de som van de rankings van scores | Twee onafhankelijke steekproeven | Hoe verschilt de waargenomen sociale status in de ene stad van de waargenomen sociale status in de andere stad? |
| Wilcoxon matched-pairs signed-rank test | Vergelijkt de omvang en richting van het verschil tussen de spreiding van scores | Twee afhankelijke steekproeven | In hoeverre is de spreiding van het inkomen gelijk voor mannen en vrouwen uit dezelfde stad? |
| Kruskal–Wallis-toets (Kruskal-Wallis H-test) | Vergelijkt de rangschikking van scores tussen groepen | Drie of meer steekproeven | In hoeverre verschillen jongeren, volwassenen en ouderen van mening over vaccins? |
| Spearmans rangcorrelatie (Spearman’s rho of rank correlation coefficient) | Onderzoekt of twee variabelen correleren | Twee ordinale variabelen | Correleert het inkomen met de waargenomen sociale status? |
Lees waarom zo veel studenten Scribbr inschakelen
Veelgestelde vragen
Citeer dit Scribbr-artikel
Als je naar deze bron wilt verwijzen, kun je de bronvermelding kopiëren of op “Citeer dit Scribbr-artikel” klikken om de bronvermelding automatisch toe te voegen aan onze gratis Bronnengenerator.
Merkus, J. (2021, 21 juli). Hoe verzamel en analyseer je ordinale data | Met voorbeelden. Scribbr. Geraadpleegd op 29 juni 2026, van https://www.scribbr.nl/statistiek/ordinale-data/
