Nominale data verzamelen en analyseren | Uitleg & voorbeelden
Je kunt de data voor variabelen met een nominaal meetniveau verdelen over verschillende categorieën, waarbij iedere waarde maar tot één categorie kan behoren. Bovendien kunnen de categorieën niet worden gerangschikt.
Een voorbeeld van een nominale variabele is “vervoersmiddelen”. Hierbij zou je de data kunnen verdelen over de categorieën auto, bus, trein, tram, fiets en metro. Iedere waarde kan maar in één categorie vallen (want iets kan bijvoorbeeld niet zowel een auto als een metro zijn). Je kunt de genoemde categorieën niet rangschikken op een betekenisvolle manier. Het maakt immers niet uit of je de rangschikking begint of eindigt met de auto.
Meetniveaus
Het meetniveau geeft aan hoe precies de data zijn verzameld. Er zijn vier meetniveaus: nominaal, ordinaal, interval en ratio. Een hoger meetniveau is altijd complexer en preciezer.
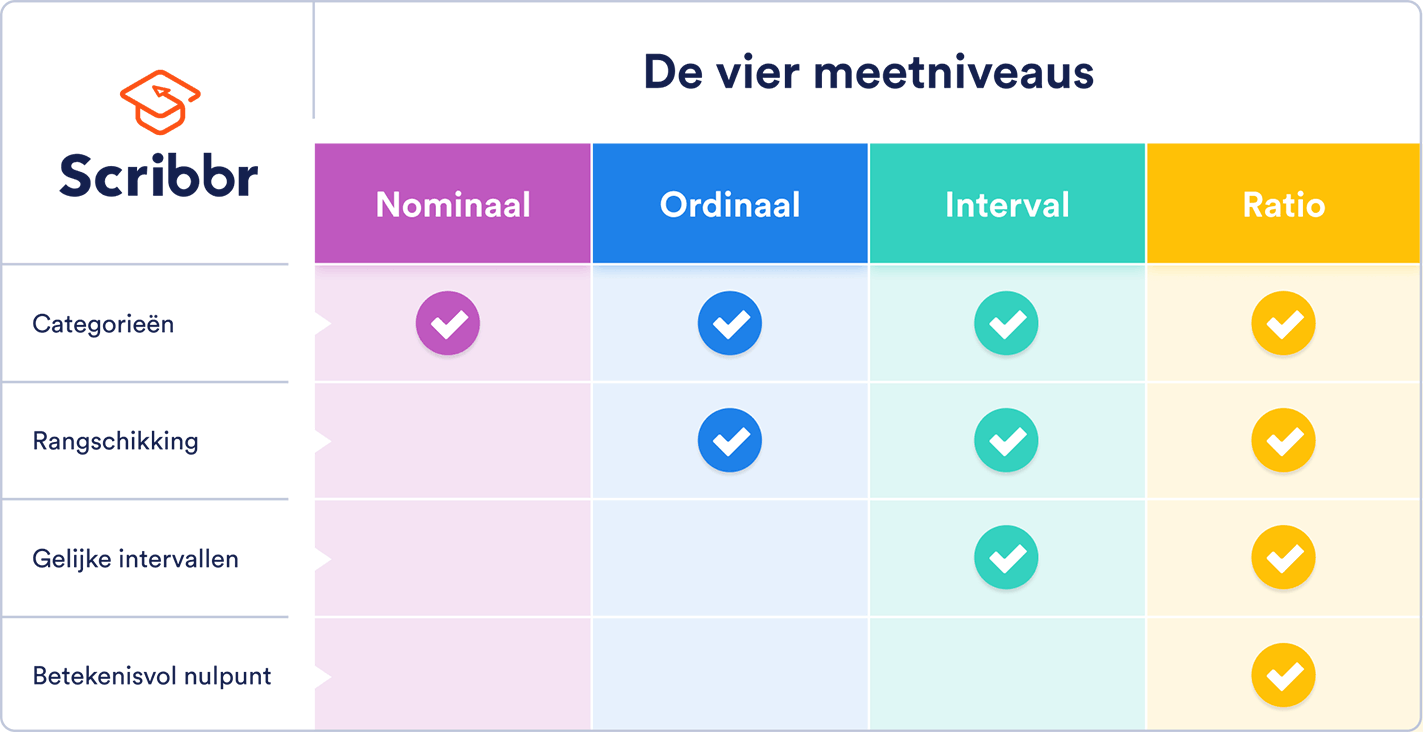
Het nominale meetniveau is het minst precieze en het minst complexe niveau. De data kunnen wel worden gelabeld, maar niet worden gerangschikt. Ook zijn de afstanden tussen de categorieën niet gelijk (het is niet vast te stellen of de afstand tussen een auto en metro even groot is als de afstand tussen een metro en trein) en er is geen betekenisvol nulpunt.


Voorbeelden van nominale data
In het geval van een nominaal meetniveau past iedere respons of observatie maar in één categorie. Nominale data kunnen worden uitgedrukt in woorden of getallen, maar zelfs als je numerieke labels gebruikt om je data in te voeren, kun je geen berekeningen uitvoeren met de data.
| Variabele | Categorieën |
|---|---|
| Postcode |
|
| Boomsoorten |
|
| Muziekstijlen |
|
| Genres |
|
Variabelen die je maar op twee manieren kunt coderen (bijvoorbeeld ja/nee, waar/onwaar) worden binair of dichotoom genoemd. Aangezien ook hier de volgorde van de labels niet uitmaakt, vallen binaire variabelen onder nominale variabelen.
Hoe verzamel je nominale data?
Je kunt bijvoorbeeld nominale data verzamelen door open of gesloten enquêtevragen te stellen. Als de variabele waarin je geïnteresseerd bent maar uit enkele categorieën bestaat, kun je het beste gesloten vragen gebruiken (zoals meerkeuzevragen).
| Wat is je gender? | Man Vrouw Anders Ik beantwoord deze vraag liever niet |
|---|---|
| Ben je in het bezit van een smartphone? | Ja Nee |
| Wat je favoriete filmgenre? | Romantiek Actie Detective Animatie Musical Komedie Thriller |
Als de variabele waarin je geïnteresseerd bent heel veel mogelijke categorieën heeft of als je niet alle categorieën weet, kun je het beste open vragen gebruiken.
- Wat is je studentnummer?
- Wat is je postcode?
- Wat is je moedertaal?
Hoe analyseer je nominale data?
Je kunt je nominale data organiseren en visualiseren met behulp van tabellen en diagrammen. Vervolgens kun je de lezer descriptieve statistieken over je data presenteren. Deze statistieken zeggen iets over de frequentieverdeling en de centrale tendens. Let hierbij wel op het type statistiek dat je gebruikt, want niet alle centrummaten en spreidingsmaten zijn toepasbaar op nominale data.
| Nederlands Nederlands Engels Nederlands Nederlands Nederlands Engels Engels Duits |
Duits Nederlands Nederlands Nederlands Nederlands Engels Engels Duits Nederlands |
Duits Nederlands Nederlands Engels Engels Nederlands Duits Nederlands Nederlands |
Verdeling of spreiding
Om inzicht te krijgen in de data, kun je een automatische frequentietabel opvragen, zodat je het aantal responses per categorie (Nederlands, Engels, Duits) ziet.
| Moedertaal | Frequentie |
|---|---|
| Nederlands | 15 |
| Engels | 7 |
| Duits | 5 |
| Moedertaal | Percentage |
|---|---|
| Nederlands | 55,6% |
| Engels | 25,9% |
| Duits | 18,5% |
Vervolgens kun je deze tabellen eventueel visualiseren door diagrammen te gebruiken, zoals een cirkeldiagram (relatief) of een staafdiagram. Doe dit echter alleen als de visualisering iets toevoegt aan de tekst.
Centrummaten
De centrummaten geven een indicatie van het zwaartepunt van je data. De modus, het gemiddelde en de mediaan zijn de drie meest gebruikte centrummaten. In het geval van nominale data kun je alleen de modus gebruiken.
Om de mediaan vast te stellen, moet je de data namelijk kunnen rangschikken van laag naar hoog. Voor het gemiddelde moet je berekeningen kunnen uitvoeren, zoals optellen en delen. Je kunt nominale data over categorieën verdelen, maar het is niet mogelijk om de data te rangschikken of op te tellen.
Daarom kun je alleen de centrummaat “modus” gebruiken om de centrale tendens van nominale data te beschrijven. De modus is de vaakst voorkomende waarde.
In dit geval gaven de meeste participanten aan Nederlands als moedertaal te hebben, dus Nederlands is de modus.
Statistische toetsen voor nominale data
Inferentiële of toetsende statistiek kan worden gebruikt om wetenschappelijke hypothesen over je data te toetsen. In het geval van nominale data gebruik je non-parametrische statistische toetsen, omdat parametrische toetsen gepaard gaan met statistische aannames (zoals normaal verdeelde data). Deze aannames zijn niet toepasbaar op nominale data, omdat de categorieën niet betekenisvol kunnen worden gerangschikt.
De chi-kwadraattoets (chi-squared test) is een non-parametrische toets die wordt gebruikt voor categorische variabelen. Er zijn drie varianten:
- De aanpassingstoets (om te onderzoeken of de gevonden verdeling correspondeert met de verwachte verdeling).
- De onafhankelijkheidstoets (om te onderzoeken of twee variabelen gerelateerd zijn).
- De homogeniteitstoets (om te onderzoeken of meerdere steekproeven uit dezelfde verdeling afkomstig zijn).
De aanpassingstoets (goodness of fit) wordt gebruikt voor datasets met één variabele, en de onafhankelijkheidstoets (chi-square test of independence) wordt gebruikt voor datasets met twee variabelen.
Je gebruikt de aanpassingstoets als je data hebt verzameld uit één populatie door middel van een aselecte steekproef. Om te toetsen hoe representatief je steekproef is, vergelijk je de frequentieverdeling van je steekproef met de verwachte verdeling van de bredere populatie om te bepalen of de werkelijkheid overeenkomt met de verwachting.
Met de chi-kwadraattoets kun je onderzoeken of hetgeen je hebt gevonden statistisch gezien afwijkt van hetgeen al bekend was.
Met de onafhankelijkheidstoets kun je onderzoeken of een relatie tussen twee categorische vairabelen significant is.
Veelgestelde vragen
Citeer dit Scribbr-artikel
Als je naar deze bron wilt verwijzen, kun je de bronvermelding kopiëren of op “Citeer dit Scribbr-artikel” klikken om de bronvermelding automatisch toe te voegen aan onze gratis Bronnengenerator.
Merkus, J. (2021, 16 juli). Nominale data verzamelen en analyseren | Uitleg & voorbeelden. Scribbr. Geraadpleegd op 23 juni 2026, van https://www.scribbr.nl/statistiek/nominale-data/
