T-test begrijpen, uitvoeren (SPSS) en het resultaat interpreteren
De t-test, ook wel t-toets genoemd, wordt gebruikt om de gemiddelden van maximaal twee groepen met elkaar te vergelijken. Je kunt de t-test bijvoorbeeld gebruiken om te analyseren of moedertaalsprekers gemiddeld sneller spreken dan niet-moedertaalsprekers.
Als je de gemiddelden van meer dan twee groepen met elkaar wilt vergelijken, kun je een ANOVA of meervoudige regressieanalyse met dummy’s gebruiken.
Soorten t-testen
Er zijn verschillende soorten t-testen, zoals de one sample t-test, de independent samples t-test en de paired samples t-test. Welke je gebruikt is afhankelijk van wat voor soort gemiddelden je met elkaar wilt vergelijken.
One sample t-test
Gebruik de one sample t-test om te analyseren of het gemiddelde van een steekproef significant verschilt van een bepaalde waarde.
Independent samples t-test (ongepaarde t-test)
De independent samples t-test (of ongepaarde t-test) gebruik je om te onderzoeken of twee steekproefgemiddelden significant van elkaar verschillen.
Paired samples t-test (gepaarde t-test)
Gebruik de paired samples t-test om twee gemiddelden van gepaarde steekproeven met elkaar te vergelijken. Gepaarde steekproeven zijn afhankelijk van elkaar.
Lees waarom zo veel studenten Scribbr inschakelen
Voorwaarden t-test
Voordat je een t-test uitvoert, is het belangrijk om ervoor te zorgen dat je data aan een aantal voorwaarden voldoen. Pas als aan alle voorwaarden is voldaan, zijn de resultaten van de t-test betrouwbaar.
- De afhankelijke variabele wordt gemeten op interval- of rationiveau (scale).
- De personen binnen de twee groepen zijn onafhankelijk van elkaar. Je kunt hiervoor werken met aselecte steekproeven.
- Als je steekproef minder dan 30 observaties telt, moet de afhankelijke variabele normaal verdeeld zijn. Dit kun je controleren in SPSS met de Shapiro-Wilk- of Kolmogorov-Smirnov-toets. Als de variabele niet normaal verdeeld is, kun je beter de Wilcoxon- of de Mann-Whitney-toets gebruiken.
T-test uitvoeren met SPSS
In dit voorbeeld voeren we een independent samples t-test uit, omdat dit de meest gebruikte variant is. De stappen en de SPSS-output voor de one sample t-test en de paired samples t-test zijn vergelijkbaar.
Om de independent samples t-test uit te voeren met SPSS, klik je in de menubalk op:
- Analyze
- Compare Means
- Independent-Samples t-test (of selecteer one-sample t-test of paired-samples t-test)
Er verschijnt een scherm waarin je onder Test Variable(s): de variabele “lengte” selecteert, en bij Grouping Variable de variabele “geslacht”.
Klik vervolgens op “Define Groups” en vul bij “Group 1” en bij “Group 2” de waarden in die je hebt gebruikt voor je labels, bijvoorbeeld man = 0 en vrouw = 1. Dit kun je terugvinden bij de desbetreffende variabele in de “Variable View“.
Klik op “Continue” en vervolgens op “OK” om de t-test uit te voeren.
T-test interpreteren
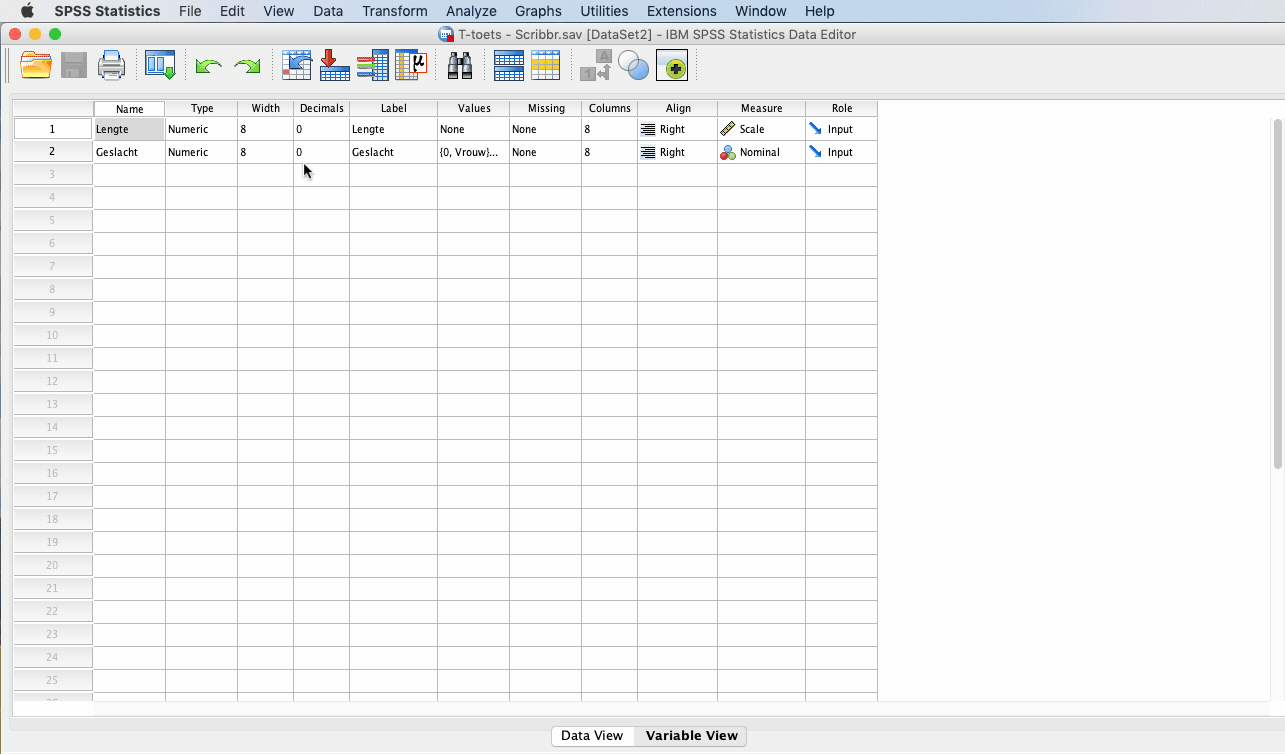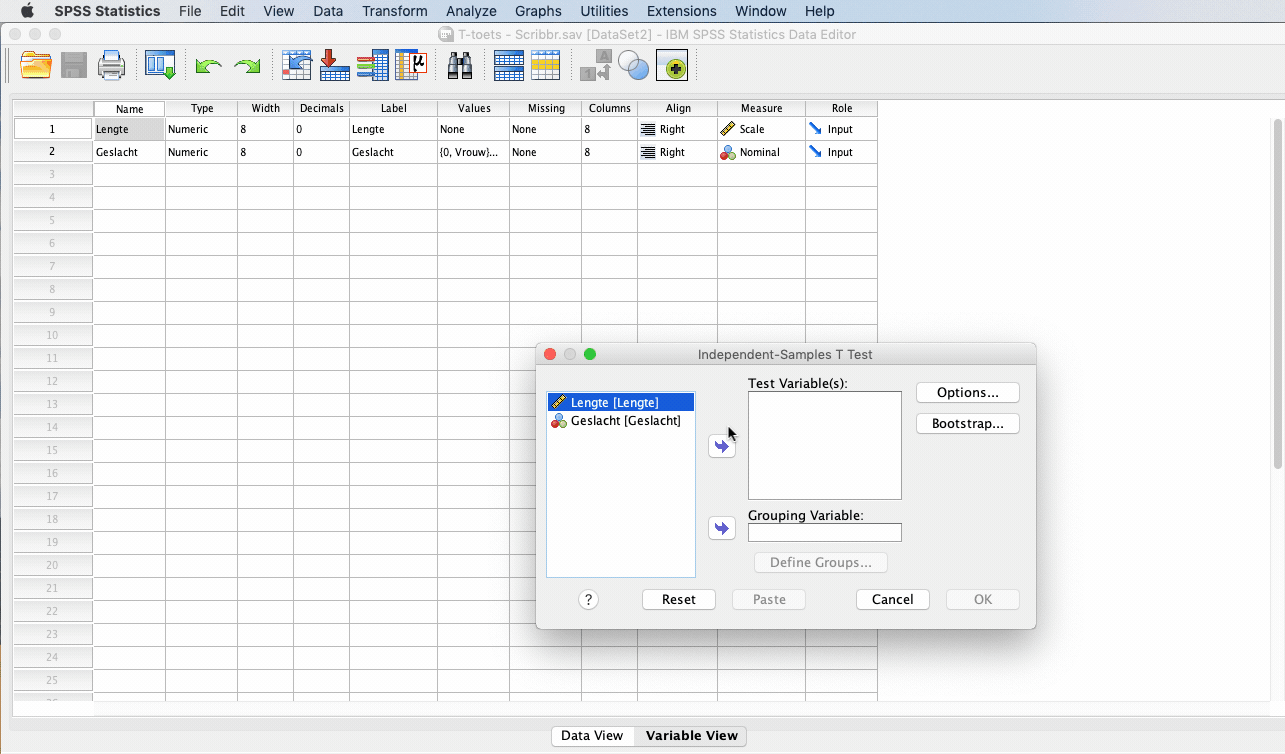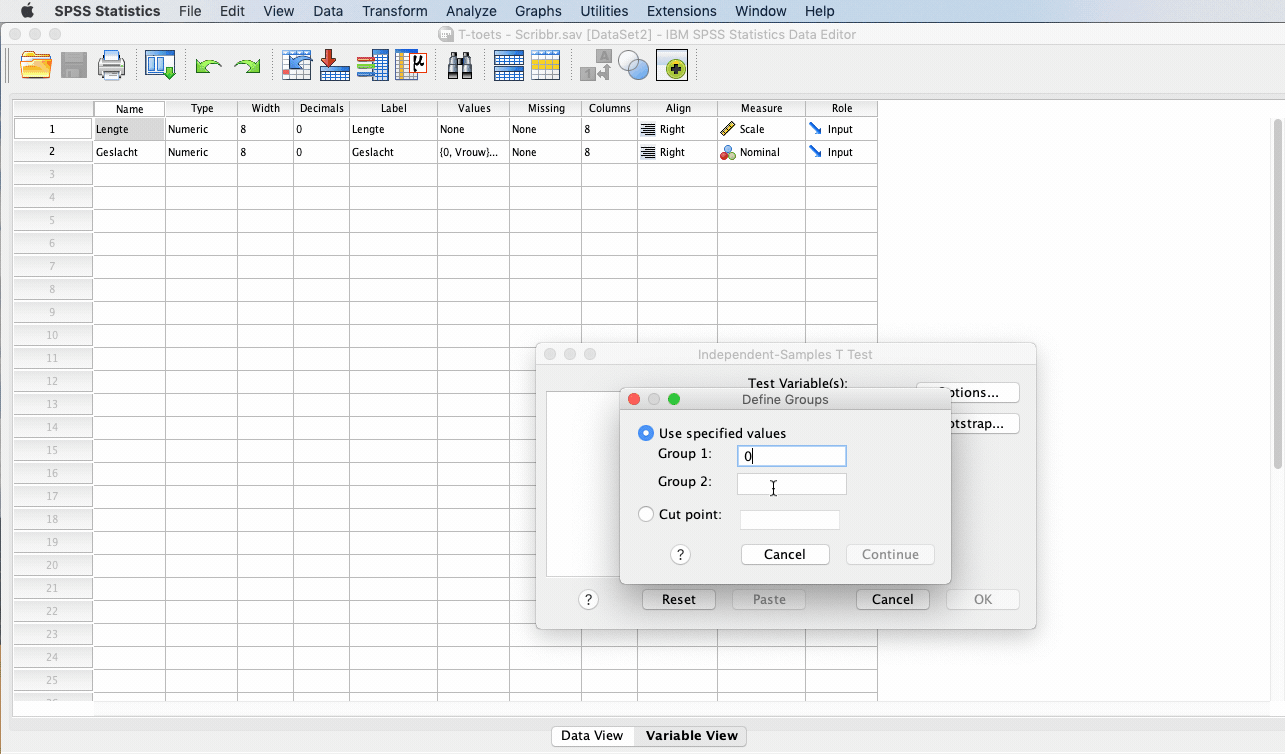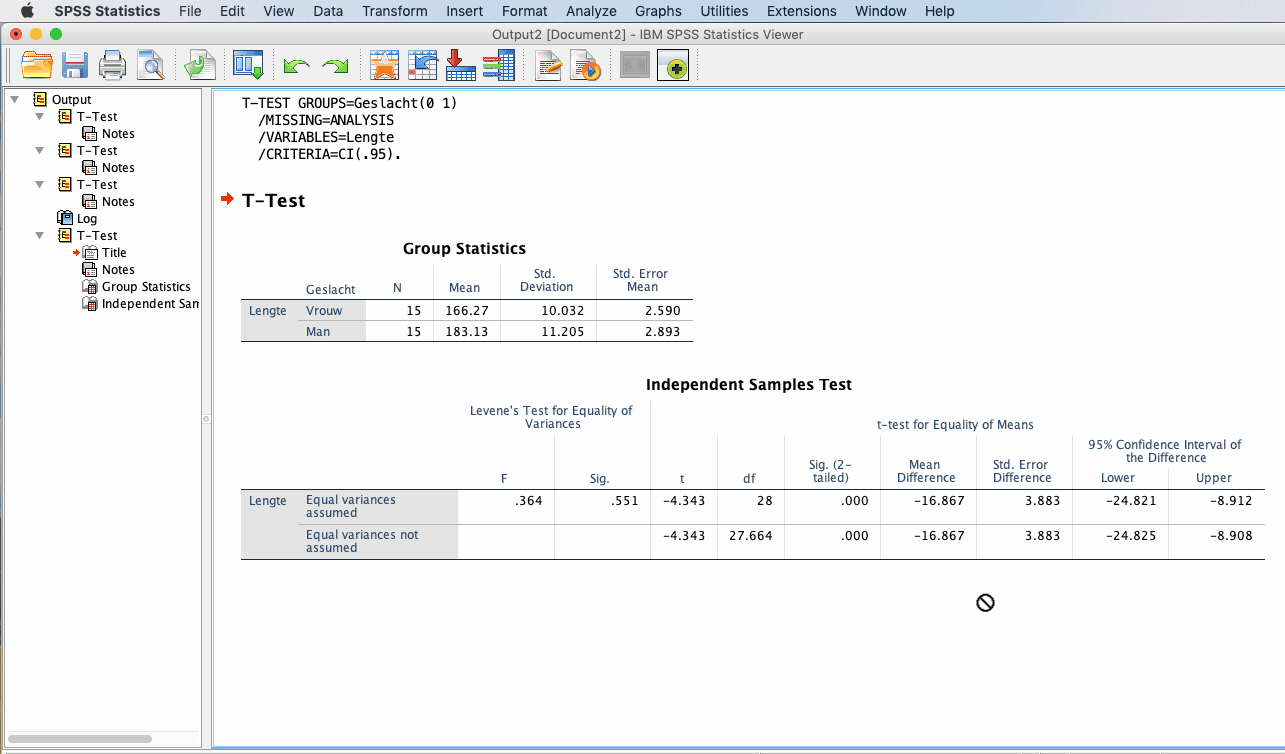
De SPSS-output voor de independent samples t-test (t-test voor onafhankelijke steekproeven) bevat twee tabellen.
Group Statistics
De eerste tabel, “Group Statistics”, bevat beschrijvende statistieken over beide groepen, zoals het gemiddelde, de standaarddeviatie en de standaardfout van het gemiddelde.
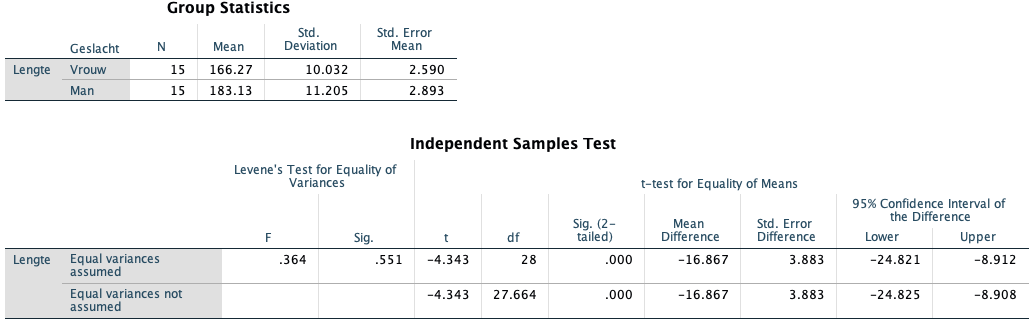
Levene’s test
De tweede tabel, “Independent Samples Test”, weergeeft het resultaat van de t-test. Het eerste (meest linkse) deel is Levene’s Test. De Levene’s Test analyseert of de variantie van beide groepen gelijk is. Dit bepaalt of je naar de bovenste of onderste rij moet kijken.
Als de significantie van de Levene’s Test onder de gebruikelijke .05 ligt, wordt de nulhypothese van gelijke variantie verworpen. In het voorbeeld is de waarde .551, dus we mogen aannemen dat de varianties in beide groepen gelijk zijn. We kijken dus naar de bovenste rij van de output.
In het meest ideale geval is Levene’s test niet significant.
Independent Samples Test
Vervolgens wordt de t-waarde (-4,343) genoemd met de bijbehorende vrijheidsgraden (d = 28). Ten slotte volgt de p-waarde in kolom “Sig. (2-tailed)”. Bij een p-waarde kleiner dan .05, moet de nulhypothese worden verworpen en kun je concluderen dat er significante verschillen zijn tussen de gemiddelden van de twee groepen.
T-test resultaten rapporteren
De resultaten van je t-test rapporteer je in het resultatenhoofdstuk van je scriptie. In het geval van onafhankelijke steekproeven (independent samples t-test) vermeld je minstens:
- Het gemiddelde en de standaarddeviatie van beide groepen;
- De t-waarde met het aantal vrijheidsgraden;
- De significantie (p-waarde) van de t-test.
- Het verschil in gemiddelde lengte voor vrouwen (M = 166.3; SD = 10.03) en mannen (M = 183.1; SD = 11.21) was significant (t (28) = -4,34; p < .001).
- De gemiddelde lengte van vrouwen (M = 166.3; SD = 10.03) was lager dan die van de mannen (M = 183.1; SD = 11.21). Dit verschil was zeer significant: t (28) = -4,34, p < .001.
Als je de opmaakrichtlijnen van de APA-stijl volgt, moet je er op letten dat je de resultaten van statistische toetsen zoals de t-test correct weergeeft. Zo is in bovenstaande voorbeelden te zien dat alle afkortingen zoals SD en M cursief gedrukt zijn en dat de decimale komma’s vervangen zijn door punten. Deze en andere APA-richtlijnen lees je in ons artikel over de schrijfwijze van statistische resultaten.
Veelgestelde vragen
Citeer dit Scribbr-artikel
Als je naar deze bron wilt verwijzen, kun je de bronvermelding kopiëren of op “Citeer dit Scribbr-artikel” klikken om de bronvermelding automatisch toe te voegen aan onze gratis Bronnengenerator.
van Heijst, L. (2022, 08 augustus). T-test begrijpen, uitvoeren (SPSS) en het resultaat interpreteren. Scribbr. Geraadpleegd op 23 juni 2026, van https://www.scribbr.nl/statistiek/t-toets/
