Bij een ANOVA is de nulhypothese dat er geen verschil is tussen de groepsgemiddelden. Als een groep significant verschilt van het algemene groepsgemiddelde, dan zal de ANOVA een statistisch significant resultaat rapporteren.
Significante verschillen tussen groepsgemiddelden worden berekend met behulp van een F-statistiek, die de verhouding weergeeft tussen de gemiddelde som van de kwadraten (de variantie die door de onafhankelijke variabele wordt verklaard) en de gemiddelde kwadratische fout (de variantie die overblijft).
Als de F-statistiek hoger is dan de kritieke waarde (de waarde van F die overeenkomt met je alfa-waarde, meestal 0.05), dan wordt het verschil tussen groepen statistisch significant geacht.
Een factoriële ANOVA is elke ANOVA die meer dan één categorische onafhankelijke variabele gebruikt. Een two-way ANOVA is een soort factoriële ANOVA.
Enkele voorbeelden van scenario’s waarin je factoriële ANOVA’s gebruikt, zijn:
Het toetsen van de gecombineerde effecten van vaccinatie (gevaccineerd of niet gevaccineerd) en gezondheidsstatus (gezond of al bestaande aandoening) op de mate van griepinfectie in een populatie.
Het toetsen van de effecten van burgerlijke staat (gehuwd, ongehuwd, gescheiden, weduwnaar), beroepsstatus (zelfstandig, werkend, werkloos, gepensioneerd) en familiegeschiedenis (geen familiegeschiedenis, enige familiegeschiedenis) op de incidentie van depressie in een populatie.
Het toetsen van effecten van het soort voeding (soort A, B of C) en stalbezetting (niet vol, enigszins vol, zeer vol) op het eindgewicht van kippen in een commercieel landbouwbedrijf.
Het enige verschil tussen een one-way ANOVA en een two-way ANOVA is het aantal onafhankelijke variabelen. Een one-way ANOVA heeft één onafhankelijke variabele, terwijl een two-way ANOVA er twee heeft.
One-way ANOVA: Toetst de relatie tussen het merk schoen (Nike, Adidas, Saucony, Hoka) en de finishtijd van een marathon.
Two-way ANOVA: Toetst de relatie tussen het merk schoen (Nike, Adidas, Saucony, Hoka), leeftijdsgroep van de loper (junior, senior, master) en de finishtijd van een marathon.
Alle ANOVA’s zijn bedoeld om te toetsen op verschillen tussen drie of meer groepen. Als je alleen op een verschil tussen twee groepen wilt testen, gebruik dan een t-toets.
In de formule van de Poissonverdeling is lambda (λ) het gemiddelde aantal gebeurtenissen binnen een bepaald tijds- of ruimte-interval. Bijvoorbeeld: λ = 0.748 overstromingen per jaar.
De e in de formule van de Poissonverdeling staat voor het getal 2.718. Dit getal wordt de constante van Euler genoemd. Je kunt e simpelweg vervangen door 2.718 als je een kans van de Poissonverdeling berekent. De constante van Euler is een heel nuttig getal en is vooral belangrijk in de wiskunde.
Je kunt outliers het beste alleen verwijderen als je daar een goede reden voor hebt.
Sommige uitschieters vertegenwoordigen natuurlijke variatie in de populatie en deze mogen niet worden verwijderd uit je dataset. Dit zijn echte uitschieters.
Andere uitschieters zijn problematisch en moeten worden verwijderd uit je dataset. Deze uitschieters zijn meetfouten, invoer- of verwerkingsfouten, of data uit een niet-representatieve steekproef.
Deze extreme waarden kunnen ook de statistische power van je toets beïnvloeden, waardoor het moeilijk wordt een echt effect op te sporen, als er wel een effect is (Type II-fout).
Kies het significantieniveau op basis van het gewenste betrouwbaarheidsniveau. Het meest gebruikelijke betrouwbaarheidsniveau is 95%, wat overeenkomt met α = .05 in de tweezijdige t-tabel.
Zoek de kritieke waarde van t in de tweezijdige t-tabel.
Vermenigvuldig de kritieke waarde van t met .
Tel deze waarde bij het gemiddelde op om de bovengrens van het betrouwbaarheidsinterval te berekenen, en trek deze waarde van het gemiddelde af om de ondergrens van het betrouwbaarheidsinterval te berekenen.
Je kunt de T.INV() functie gebruiken om de kritieke waarde van t te vinden voor eenzijdige toetsen in Excel. Voor tweezijdige toetsen gebruik je de T.INV.2T() functie.
Voorbeeld: De kritieke waarde van t berekenen in ExcelOm de kritieke waarde van t te berekenen voor een tweezijdige toets met df = 29 en α = .05, klik je op een lege cel en typ je:
Je kunt de qt() functie gebruiken om de kritieke waarde van t te vinden in R. De functie geeft de kritieke waarde van t voor de eenzijdige toets. Als je de kritieke waarde van t voor een tweezijdige toets wilt, deel je het significantieniveau door twee.
Voorbeeld: De kritieke waarde van t berekenen in ROm de kritieke waarde van t voor een tweezijdige toets met df = 29 en α = .05 te berekenen, gebruik je de volgende functie:
Je kunt de PEARSON() functie gebruiken om de Pearson correlatiecoëfficiënt (r) in Excel te berekenen. Als je variabelen in de kolommen A en B staan, klik je op een lege cel en typ je “PEARSON(A:A, B:B)”.
Er is geen functie om de significantie van de correlatie direct te berekenen.
Je kunt de cor() functie gebruiken om de Pearson correlatiecoëfficiënt (r) in R te berekenen. Om de significantie van de correlatie te testen, kun je de cor.test() functie gebruiken.
Je kunt de Pearson correlatiecoëfficiënt (r) gebruiken als je een correlatie tussen twee variabelen wilt meten en (1) het verband tussen de variabelen lineair is, (2) beide variabelen kwantitatief zijn, (3) beide variabelen continu van aard zijn, (4) normaal verdeeld zijn en (5) geen uitschieters hebben.
Als er drie of meer vrijheidsgraden zijn, heeft de verdeling de vorm van een rechtsscheve bult (hump).
Naarmate het aantal vrijheidsgraden verder toeneemt, wordt de bult minder rechtsscheef en verschuift de piek van de bult naar rechts. De verdeling gaat steeds meer lijken op een normale verdeling.
Een onderzoekshypothese is jouw verwachte antwoord op de onderzoeksvraag. De onderzoekshypothese bevat meestal een verklaring (x beïnvloedt y omdat…).
Een statistische hypothese is een wiskundige uitspraak over een populatieparameter. Statistische hypothesen komen altijd in paren: de nul- en alternatieve hypothese.
In een goede onderzoeksopzet komen de nul- en alternatieve hypothese logisch overeen met de onderzoekshypothese. Soms hoef je alleen de alternatieve hypothese te formuleren.
De alternatieve hypothese wordt vaak afgekort tot Ha of H1. Als de alternatieve hypothese wordt beschreven met wiskundige symbolen, bevat deze altijd een ongelijkheidssymbool (meestal ≠, maar soms ook < of >).
De nulhypothese wordt vaak afgekort tot H0. Als de nulhypothese wordt beschreven met wiskundige symbolen, bevat deze altijd een gelijkheidssymbool (meestal =, maar soms ook ≥ of ≤).
Er kan een onderscheid worden gemaakt tussen kwantitatieve en categorische variabelen:
Bij kwantitatieve variabelen representeren de data hoeveelheden (zoals een lengte, gewicht, leeftijd).
Bij categorische variabelen representeren de data groepen, zoals een ranking (bijvoorbeeld de eindposities bij het songfestival), classificaties (bijvoorbeeld kledingmerken), en binaire verdelingen (zoals kop of munt).
Zowel de chi-kwadraattoets en een t-toets kunnen worden gebruikt om het verschil tussen twee groepen te onderzoeken.
Echter, een t-toets wordt gebruikt als je een kwantitatieve afhankelijke variabele hebt en een categorische onafhankelijke variabele (met twee groepen). Een chi-kwadraattoets voor samenhang wordt gebruikt bij twee categorische variabelen.
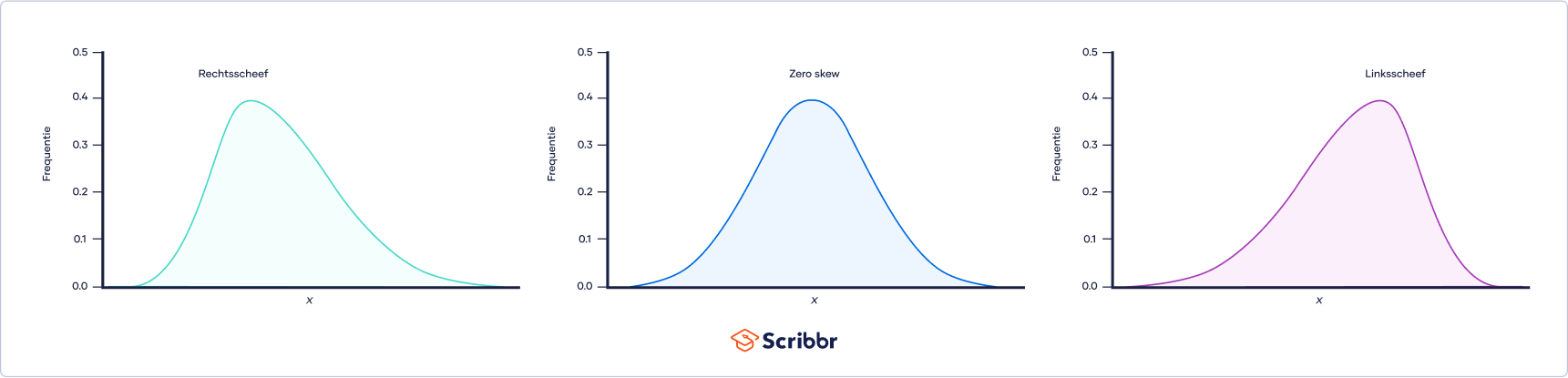
Rechtsscheef (right skew). Een rechtsscheve verdeling (ook wel positief-scheve verdeling genoemd) is langer aan de rechterkant van de piek dan aan de linkerkant.
Linksscheef (left skew). Een linksscheve verdeling (ook wel negatief-scheve verdeling genoemd) is langer aan de linkerkant van de piek dan aan de rechterkant.
Zero skew. Een verdeling met zero skew (nul scheefheid) is symmetrisch, wat inhoudt dat de linker- en rechterkant spiegelbeelden van elkaar zijn.
Als je al deze dingen weet, kun je het betrouwbaarheidsinterval voor je schatting berekenen door ze in de formule voor het betrouwbaarheidsinterval te zetten die overeenkomt met je data. Wat de formule precies is hangt af van het type schatting (e.g., een gemiddelde of een proportie) en van de verdeling van je data.
Als je betrouwbaarheidsintervalvoor het verschil tussen groepen een nul bevat, betekent dit dat er een grote kans bestaat dat je geen verschil vindt tussen de groepen als je het experiment nog een keer uitvoert.
Als je betrouwbaarheidsinterval voor een correlatie of regressie nul bevat, betekent dit dat er een grote kans bestaat dat je geen correlatie vindt in je data als je het experiment nog een keert uitvoert.
In beide gevallen zul je ook een hoge p-waarde vinden bij je statistische test. Dit houdt in dat je resultaten zouden kunnen voorkomen onder de nulhypothese. Dit zou betekenen dat de resultaten geen relatie tussen de variabelen ondersteunen.
Een kritieke waarde is een waarde van de teststatistiek die de boven- en ondergrens van het betrouwbaarheidsinterval definieert, of de drempelwaarde van statistische significantie in een statistische test. Het beschrijft hoe ver je van het gemiddelde van de verdeling af moet liggen om een bepaalde hoeveelheid van de totale variatie in de data te dekken (i.e., 90%, 95%, 99%).
Als je zowel een 95%-betrouwbaarheidsinterval als een drempelwaarde van statistische significantie van p = 0.05 aanhoudt, dan zullen je kritieke waarden in beide gevallen identiek zijn.
Het betrouwbaarheidsintervalbestaat uit de boven- en ondergrens van de schatting die je verwacht te vinden bij een gegeven betrouwbaarheidsniveau.
Het betrouwbaarheidsniveau (confidence level) is het percentage van de keren dat je verwacht in de buurt van dezelfde schatting te komen als je je experiment nog een keer uitvoert of opnieuw op dezelfde manier een steekproef uit de populatie haalt.
VoorbeeldJe wilt weten wat het gemiddelde aandeel is van het aantal meisjes dat elk jaar geboren wordt. Hiertoe gebruik je een willekeurige steekproef van baby’s. Met een 95%-betrouwbaarheidsinterval vind je een bovengrens van 0.56 en een ondergrens van 0.48. Het betrouwbaarheidsniveau is 95%.
De z-waarde en t-waarde (ook wel z-score en t-score) geven aan hoeveel standaarddeviaties je van het gemiddelde van de verdeling verwijderd bent, mits je data een z-verdeling of een t-verdeling volgen.
Als uit je test een z-score van 2.5 naar voren komt, betekent dit dat je schatting 2.5 standaarddeviaties van het gemiddelde afwijkt.
Het voorspelde gemiddelde en de voorspelde verdeling van je schatting worden bepaald door de nulhypothese van de statistische test die je uitvoert. Hoe meer standaarddeviaties van het gemiddelde je schatting afwijkt, hoe kleiner de kans dat je schatting daadwerkelijk onder je nulhypothese heeft kunnen plaatsvinden.
Elke normale verdeling kan worden omgezet in de standaardnormale verdeling door de individuele waarden om te zetten in z-waarden (z-scores). In een z-verdeling geven z-scores aan hoeveel standaarddeviaties elke waarde van het gemiddelde afligt.
Je kunt de samenvattingsfunctie() (ook wel summary () function) gebruiken om R² (coefficient of determination) van een lineair model weer te geven in R. Onderaan de output zie je “R-kwadraat” (“R-squared”) staan.
De determinatiecoëfficiënt (R²) is een getal tussen de 0 en 1 dat de mate aanduidt waarin een statistisch model in staat is een bepaalde uitkomst te voorspellen. Je kunt de R² interpreteren als de proportie (het deel) van de variantie in de afhankelijke variabele die wordt voorspeld door het statistisch model.
Het is altijd duidelijk of een getal een parameter of statistiek is. Om te bepalen met welke van de twee je te maken hebt, kun jezelf de volgende vragen stellen:
Beschrijft het getal een gehele, complete populatie waarbij elk lid kan worden bereikt voor de dataverzameling?
Is het mogelijk om binnen een redelijke termijn data voor ieder lid van de populatie te verzamelen?
Als het antwoord op beide vragen ja is, is het getal waarschijnlijk een parameter. Als het antwoord op een van de vragen nee is, is de kans groter dat het om een statistiek gaat.
Een parameter is een waarde die een hele populatie beschrijft (bijvoorbeeld het populatiegemiddelde), terwijl een statistiek een getal is dat een steekproef beschrijft (bijvoorbeeld het steekproefgemiddelde).
Er bestaat een omgekeerd evenredig verband tussen het risico op een Type II-fout en de statistische power van een onderzoek. De power is de mate waarin een toets een daadwerkelijk bestaand effect correct kan detecteren.
Om het risico op een Type II-fout (indirect) te verkleinen, kun je de steekproef vergroten of het significantieniveau verhogen, omdat je zo de statistische power vergroot.
Het significantieniveau is meestal 0.05 of 5%. Dit betekent dat er een kans van 5% is dat de gevonden resultaten zouden voorkomen als de nulhypothese daadwerkelijk waar zou zijn.
Om het risico op een Type I-fout te verkleinen, verlaag je het significantieniveau alfa. Hiermee vergroot je wel het risico op een Type II-fout.
De t-verdeling is een meer conservatieve vorm van de standaardnormale verdeling (ook wel z-verdeling of standard normal distribution genoemd). Dit betekent dat de t-verdeling een lagere kansdichtheid geeft voor het centrum en een hogere kansdichtheid voor de staarten dan de standaard normaleverdeling.
Een t-score is het aantal standaarddeviaties van het gemiddelde in een t-verdeling. Je kunt een t-score opzoeken in een t-tabel of een online calculator voor de t-score gebruiken.
Bij statistiek worden t-scores voornamelijk gebruikt om de volgende waarden te bepalen:
De boven- en ondergrenzen van een betrouwbaarheidsinterval als de data ongeveer normaal verdeeld zijn.
De p-waarde van de teststatistiek voor t-toetsen en regressieanalyses.
De t-verdeling (ook wel t-distribution of Student’s t-distribution genoemd) wordt gebruikt als de data bij benadering normaal verdeeld zijn (en dus een klokvorm volgen), maar waarbij de populatievariantie onbekend is. De variantie in een t-verdeling wordt geschat op basis van het aantal vrijheidsgraden van de dataset (totaal aantal waarnemingen min 1).
De t-verdeling is een variant op de normale verdeling, maar deze wordt gebruikt voor kleinere steekproeven, waarbij de variantie onbekend is.
Statistische power (statistical power) verwijst naar de waarschijnlijkheid dat een hypothesetoets een echt effect vaststelt als dat effect er is. Dit noem je ook wel hetonderscheidend vermogen. Een toets met veel statistische power is beter in staat een Type II-fout (false negative) te voorkomen.
Als je onderzoek onvoldoende power heeft, kan het voorkomen dat je geenstatistisch significantresultaat vindt, zelfs als dit wel aanwezig is en praktische relevantie heeft. Hierdoor zou je ten onrechte de nulhypothese behouden.
Er zijn tientallen maten voor de effectgrootte. De maten die het vaakst gebruikt worden zijn Cohen’s d en Pearson’s r. Cohen’s d meet de grootte van een verschil tussen twee groepen, terwijl Pearson’s r de sterkte van een relatie tussen twee variabelen meet.
Je kunt ze berekenen met behulp van statistische software (zoals SPSS) of op basis van de formules.
Statistische significantie laat zien dat een effect, verschil of relatie bestaat in een onderzoek, terwijl praktische significantie (relevantie) laat zien dat het effect groot genoeg is om betekenisvol te zijn in de echte wereld.
De statistische significantie wordt gerapporteerd met behulp van p-waardes, terwijl de praktische relevantie wordt uitgedrukt met de effectgrootte.
De effectgrootte laat zien hoe betekenisvol de relatie tussen variabelen of het verschil tussen groepen is. Het zegt iets over de praktische relevantie (ook wel praktische significantie genoemd) van een onderzoeksresultaat.
Een klein effect heeft weinig praktische implicaties, terwijl een groot effect juist veel praktische implicaties kan hebben.
Het significantieniveau (alfa, α) geeft de maximale kans weer dat je de nulhypothese ten onrechte verwerpt (een Type I-fout). Je kiest het significantieniveau zelf voordat je een statistische toets uitvoert. Meestal kies je voor een α van 0.05 (5%) of 0.01 (1%).
Praktische significantie (ook wel praktische relevantie genoemd) laat zien of de onderzoeksuitkomst belangrijk genoeg is om betekenisvol te zijn in de echte wereld. Voor deze vorm van significantie rapporteer je de effectgrootte van het onderzoek.
Klinische significantie (ook wel klinische relevantie genoemd) is relevant voor interventie- en behandelingsstudies. Een behandeling wordt als klinisch significant beschouwd als deze het leven van patiënten tastbaar of substantieel verbetert.
Nee, de p-waarde zegt niets over de alternatieve hypothese. De p-waarde geeft aan hoe waarschijnlijk het is dat de data die je hebt gevonden zouden voorkomen als de nulhypothese waar zou zijn.
Als de p-waarde onder je grenswaarde (vaak p < 0.05) valt, kun je de nulhypothese verwerpen, maar dit betekent niet per se dat je alternatieve hypothese waar is.
Je berekent p-waarden meestal automatisch met het programma dat je gebruikt voor je statistische analyse (zoals SPSS of R). Je kunt de p-waarde ook schatten met behulp van tabellen voor de teststatistiek die je gebruikt.
P-waarden vertellen je hoe vaak een teststatistiek waarschijnlijk zou voorkomen onder de nulhypothese, op basis van de positie van de teststatistiek in de nulverdeling.
Als de teststatistiek ver verwijderd is van het gemiddelde van de nulverdeling, dan is de p-waarde klein. Dit laat zien dat het niet waarschijnlijk is dat de teststatistiek zou voorkomen als de nulhypothese waar is.
De standaarddeviatie of standaardafwijking wordt afgeleid van de variantie en vertelt je hoe ver iedere waarde gemiddeld genomen van het gemiddelde verwijderd is. Het is de vierkantswortel van de variantie.
Beide maten zeggen iets over de spreiding in een verdeling, maar de eenheden verschillen:
De standaarddeviatie wordt uitgedrukt in dezelfde eenheid als de oorspronkelijke waarden (bijvoorbeeld meters).
De variantie wordt uitgedrukt in veel grotere eenheden (bijvoorbeeld vierkante meters).
Statistische toetsen, zoals een variantieanalyse (ook wel Analysis of Variance of ANOVA genoemd), gebruiken steekproefvariantie om groepsverschillen te beoordelen. Ze gebruiken de varianties van de steekproeven om te beoordelen of de populaties waaruit ze afkomstig zijn van elkaar verschillen.
Cramer’s V is een gestandaardiseerde maat voor de samenhang tussen variabelen, terwijl chi-kwadraat geen gestandaardiseerde maat is. Met de chi-kwadraattoets kun je enkel beoordelen of het verschil tussen twee of meerdere verdelingen van elkaar verschillen.
Door de waarde voor chi-kwadraat om te zetten in Cramer’s V, kun je waarden met elkaar vergelijken.
Cramer’s V is een maat voor de effectgrootte die informatie geeft over de statistische samenhang tussen twee of meer variabelen van nominaal niveau. De waarde ligt tussen 0 en 1 en geeft aan hoe sterk twee categorische variabelen samenhangen.
De maat is gebaseerd op waarden uit de middelste helft van de dataset, waardoor het onwaarschijnlijk is dat de interkwartielafstand wordt beïnvloed door extreme waarden.
Centrummaten zeggen iets over het punt waar de meeste waarden geclusterd zijn (het midden of het centrum van je dataset). Spreidingsmaten geven informatie over de afstand tussen datapunten (hoe verspreid zijn de data).
Datasets kunnen dezelfde centrale tendens hebben en een verschillende mate van spreiding (of andersom). Door beide soorten maten te combineren, krijg je een compleet beeld van je data.
Nee, het bereik kan alleen 0 of een positieve waarde zijn, omdat je deze spreidingsmaat berekent door de laagste waarde van de hoogste waarde af te trekken.
Het bereik (ook wel spreidingsbreedte of range genoemd) is het interval tussen de laagste en de hoogste waarde in de dataset. Het is een veelgebruikte maat voor de spreiding (variability).
Homoscedasticiteit houdt in dat de variantie van een variabele gelijk is voor meerdere groepen of dat de variantie van de foutterm gelijk is.
Bij het uitvoeren van een t-toets of ANOVA, analyseer je de variantie tussen de meerdere groepen. Dit kan getoetst kan worden met Levene’s test.
Bij regressie moet de variantie van de foutterm gelijk zijn voor alle waarden van de verklarende variabele. Er mag dus niet meer of minder spreiding in de foutterm zijn voor grotere of lagere waarden van de verklarende variabele.
Als er een sterk lineair verband is tussen verklarende variabelen, spreek je van multicollineariteit.
Multicollineariteit kan ertoe leiden dat de regressiecoëfficiënten in je regressiemodel slechter worden geschat. De verklarende variabelen voorspellen elkaar dan en daardoor wordt er geen extra variantie verklaard in het regressiemodel.
Voorbeeld:
Je voegt zowel lengte in centimeters als lengte in inches toe als verklarende variabelen aan je regressievergelijking. Deze twee variabelen voorspellen elkaar, aangezien lengte in centimeters 2,54 maal de lengte in inches is, en zijn dus perfect lineair gecorreleerd. Er kunnen dan geen twee regressiecoëfficiënten worden berekend.
Bij het uitvoeren van een lineaire regressie is het belangrijk dat het verband tussen de verklarende variabele en de afhankelijke variabele lineair is. Dit betekent dat voor zowel lage als hoge waarden van de verklarende variabele de invloed gelijk is.
Voorbeeld:
De verklarende variabele lengte beïnvloedt de afhankelijke variabele gewicht. Een lineair verband betekent dat het gewicht net zoveel toeneemt als iemand van 150 cm naar 160 cm lengte groeit als van 180 cm naar 190 cm.
In het Nederlands gebruik je komma’s als decimaalteken, terwijl je in het Engels een punt gebruikt.
Nederlands: De appels kosten maar €5,12.
Engels: The apples only cost €5.12.
Voor duizendtallen gebruik je in het Nederlands punten, terwijl je in het Engels een komma gebruikt.
Nederlands: De koptelefoon kost €1.600.
Engels: The headphones cost €1,600.
Als je statistische resultaten rapporteert, is het wel gebruikelijk om ook in het Nederlands een punt als decimaalteken te gebruiken. Dit is zeker het geval als je de APA-stijl gebruikt.
Gebruik spaties, dus a + b = c in plaats van a+b=c
Sluit vergelijkingen af met een punt
Cursiveer de variabelen (in dit geval a, b en c)
Gebruik haakjes om de volgorde van bewerkingen aan te geven, bijvoorbeeld: (a / b) + c in plaats van a / b + c
Vergelijkingen mogen in de tekst worden geplaatst, maar gecentreerd op een aparte regel heeft de voorkeur. Nummer deze vergelijkingen, zodat je ernaar kunt verwijzen. Dit nummer is altijd rechts uitgelijnd.
Vervolgens selecteer je de vragen waarvan je de interne consistentie wilt meten.
Zorg er daarna voor dat “Alpha” geselecteerd is. Klik vervolgens op “Statistics” en vink “Scale if item deleted” aan. Alles staat nu goed: klik nu op “Continue” en “ok” om de analyse uit te voeren.
Hoewel SPSS Cronbach’s alpha voor je kan berekenen, kan het soms ook handig zijn om zelf de formule te kennen. Stel dat n (vragen) samen de score klanttevredenheid Y geven, dan is Cronbach’s alpha:
Hierbij staat s2(Xi) voor de steekproefvariantie van vraag i, en s2(Y) voor de steekproefvariantie van de totale score.
Je rapporteert Cronbach’s alpha meestal in de methodologie om aan te tonen dat je gebruikte vragenlijst betrouwbaar is. Je vermeldt het aantal items in je vragenlijst en de bijbehorende Cronbach’s alpha. Dit kun je op de volgende manier doen:
De klanttevredenheidsschaal is betrouwbaar, Cronbach’s alpha voor de drie items is .850.
De schaal voor klanttevredenheid is betrouwbaar (3 items; ⍺ = .850).
Als je variabeleniet normaal verdeeld is, kun je kijken of je de data kunt transformeren. Het kan namelijk zijn dat een variabele zelf niet normaal verdeeld is, maar het logaritme of het kwadraat wel.
Als ook dit niet het geval is, kun je niet-parametrische toetsen gebruiken, zoals de Wilcoxon- of Mann-Whitney-toets, in plaats van de t-toets.
Binnen één standaarddeviatie ligt 68,2% van de observaties (34,1% + 34,1%), binnen twee standaarddeviaties 95,2% en binnen drie standaarddeviaties 99,6%.
Veel statistische toetsen, zoals een t-toets of ANOVA, kunnen alleen geldige resultaten opleveren als sprake is van een normale verdeling. Als je data scheef verdeeld zijn, kan het voorkomen dat je resultaten niet valide zijn.
De aanname van een normale verdeling is vooral belangrijk bij steekproeven kleiner dan 30 observaties. Als je steekproef meer dan 30 observaties bevat, dan kun je volgens de centrale limietstelling (central limit theorem) aannemen dat aan de aanname van normaliteit wordt voldaan.
De standaarddeviatie (standard deviationof s) is de gemiddelde hoeveelheid variabiliteit in je dataset. Deze maat vertelt je hoe ver iedere score gemiddeld van het gemiddelde verwijderd is. Des te groter de standaarddeviatie, des te meer variabel je dataset is.
Regressieanalyses worden gebruikt om het effect te bepalen van een (of meerdere) verklarende variabele(n), zoals lengte of leeftijd, op een afhankelijke variabele zoals gewicht.
Je kunt regressieanalyse gebruiken om:
Samenhang tussen twee variabelen te bepalen (leeftijd en waarde van een auto)
Verandering van de afhankelijke variabele te voorspellen (waarde van een auto naarmate deze ouder wordt)
Toekomstige waarde te voorspellen (waarde van een zes jaar oude auto)
Voorbeeld: Je meet de gemiddelde lengte van respondenten in 2008, 2013, en 2018. Je vergelijkt dan de gemiddelde lengte van dezelfde persoon over een bepaalde periode om te kijken of deze verandert.
Je gebruikt een multivariate ANOVA (ook wel MANOVA) als je meerdere afhankelijke variabelen gebruikt. Je kunt deze ANOVA zowel gebruiken met één als meerdere groepsvariabelen (onafhankelijke variabelen).
Voorbeeld: Je wilt niet alleen niet alleen de gemiddelde lengte, maar ook het gemiddelde gewicht van verschillende groepen sporters vergelijken.
Je kunt beter een MANOVA uitvoeren dan meerdere losse ANOVA’s, om het risico op een Type I-fout te voorkomen.
Je gebruikt een two-way-ANOVA (ook wel factorial ANOVA) als je twee of meer groepsvariabelen (onafhankelijke variabelen) in je conceptueel model hebt.
Voorbeeld: Je vergelijkt de gemiddelde lengte van verschillende typen sporters én hun gender. Er wordt dan niet alleen getest of het gemiddelde verschilt voor volleyballers en turners en voetballers, maar ook voor mannen, vrouwen en mensen met een ander gender, én of er eventuele interactie-effecten zijn.
Je gebruikt een one-way-ANOVA wanneer één groepsvariabele (onafhankelijke variabele) de groepen bepaalt en er maar één afhankelijke variabele is.
Voorbeeld: Je vergelijkt de gemiddelde lengte van verschillende typen sporters, zoals voetballers, turners en volleyballers. Het type sport dat iemand beoefent, is in dit geval de enige groepsvariabele en lengte is de enige afhankelijke variabele.
ANOVA staat voor Analysis of Variance, oftewel variantieanalyse, en wordt gebruikt om gemiddelden van meer dan twee groepen met elkaar te vergelijken. Het is een uitbreiding van de t-toets, die het gemiddelde van maximaal twee groepen met elkaar vergelijkt.
Je gebruikt een gepaarde t-test (paired samples t-test) om twee gemiddelden van gepaarde steekproeven met elkaar te vergelijken. Gepaarde steekproeven zijn afhankelijk van elkaar.
Voorbeeld: Paired samples t-testJe meet de lengte van dezelfde personen in 2015 en 2018. Deze waarden zijn afhankelijk van elkaar (omdat je dezelfde persoon meet), en daarom gebruik je een paired samples t-test.
De onafhankelijke t-test (ook wel independent samples t-test of ongepaarde t-test genoemd) gebruik je om te onderzoeken of twee steekproefgemiddelden significant van elkaar verschillen.
Voorbeeld: Independent samples t-testJe wilt weten of de gemiddelde sprintsnelheid van kinderen uit groep 7 afwijkt van die van kinderen uit groep 8.
Je gebruikt de one sample t-test om te analyseren of het gemiddelde van een steekproef significant verschilt van een bepaalde waarde.
Voorbeeld: One sample t-testJe wilt controleren of chocoladerepen daadwerkelijk gemiddeld 300 gram wegen, zoals op de verpakking wordt vermeld. Om dit te onderzoeken weeg je 40 repen en vergelijk je het echte gewicht met wat het zou moeten zijn (300 gram). Hiervoor gebruik je de one sample t-test.
De t-test, ook wel t-toets genoemd, wordt gebruikt om de gemiddelden van maximaal twee groepen met elkaar te vergelijken. Je kunt de t-test bijvoorbeeld gebruiken om te analyseren of moedertaalsprekers gemiddeld sneller spreken dan niet-moedertaalsprekers.
Als je meer dan twee groepen wilt vergelijken, moet je een andere toets gebruiken, zoals de ANOVA.
De p-waarde (p-value) is een getal tussen 0 en 1, waarmee je bepaalt of een steekproefuitkomst statistisch significant is. Wanneer de p-waarde kleiner is dan het gekozen significantieniveau kun je stellen dat dat de gevonden uitkomst extreem genoeg is om je nulhypothese te verwerpen.
SPSS staat oorspronkelijk voor Statistical Package for the Social Sciences. Het is een statistisch computerprogramma ontwikkeld voor de sociale wetenschappen, maar wordt tegenwoordig ook veel gebruikt binnen andere sectoren zoals de economische wetenschappen.
SPSS helpt je bij het verzamelen, invoeren, lezen, bewerken en/of analyseren van gegevens, maar ook bij het verspreiden van de resultaten en het nemen van beslissingen.
Je kunt de modus bepalen met behulp van de volgende stappen:
Als je data numeriek van aard zijn, rangschik je de waarden van laag naar hoog. Als je data categorisch zijn, verdeel je de waarden over de juiste categorieën.
Zoek de waarde of waarden die het vaakst voorkomen.
Om de mediaan te vinden, zet je de waarden in je dataset van laag naar hoog. Vervolgens bepaal je de middelste positie op basis van n (het aantal waarden in je dataset).
Als n een oneven getal is, vind je de mediaan op positie .
Als n een even getal is, is de mediaan het gemiddelde van de waarden op posities en .
De mediaan is de meest informatieve centrummaat voor scheve verdelingen of verdelingen met uitbijters. De mediaan wordt bijvoorbeeld vaak gebruikt als centrummaat voor de variabele “inkomen”, die over het algemeen niet normaal verdeeld is.
Aangezien je voor de mediaan slechts één of twee waarden in het midden gebruikt, wordt deze maat niet beïnvloed door extreme uitbijters of niet-symmetrische verdelingen. Het gemiddelde en de modus zijn hier wel gevoelig voor.
Ook moet je op de verdeling van je data letten. Voor normaal verdeelde data kun je alle drie de centrummaten gebruiken, maar bij scheve verdelingen is de mediaan de beste keuze.
Statistische significantie is een term die door onderzoekers wordt gebruikt om aan te geven dat het onwaarschijnlijk is dat hun resultaten op toeval gebaseerd zijn. Significantie wordt meestal aangeduid met een p-waarde (overschrijdingskans).
Statistische significantie is enigszins willekeurig, omdat je zelf de drempelwaarde (alfa) kiest. De meest voorkomende drempel is p < 0.05, wat betekent dat de kans 5% is dat de resultaten worden gevonden terwijl de nulhypothese waar is. Een andere drempel die vaak wordt gekozen is p < 0.01.
Als de p-waarde lager is dan de gekozen alfa-waarde, mag je stellen dat het resultaat van de toets statistisch significant is.
Met beschrijvende statistiek (ook wel descriptieve statistiek genoemd) vat je de kenmerken van een dataset samen. Met toetsende statistiek (ook wel inferentiële of verklarende statistiek genoemd) toets je een hypothese of bepaal je of je data generaliseerbaar zijn naar een bredere populatie.
Statistische analyseis de meest belangrijke methode om kwantitatieve onderzoeksgegevens te analyseren. Hierbij wordt gebruikgemaakt van kansen en modellen om voorspellingen over een populatie te toetsen op basis van steekproefdata.
Hoewel interval– en ratiodata beide kunnen worden gecategoriseerd, gerangschikt en gelijke afstanden hebben tussen aangrenzende waarden (gelijke intervallen), hebben alleen ratiodata een absoluut of betekenisvol nulpunt.
De temperatuur in Celsius of Fahrenheit is een voorbeeld van een intervalschaal, omdat nul niet de laagst mogelijke temperatuur is. Je kunt namelijk ook nog te maken hebben met min-temperaturen. Een Kelvin-temperatuurschaal is een voorbeeld van een ratioschaal, omdat nul het absolute nulpunt is. Er zijn geen min-temperaturen.
Het nominale meetniveau verschilt van het ordinale meetniveau, omdat nominale data alleen gecategoriseerd kunnen worden, maar ordinale data ook gerangschikt kunnen worden.
Een voorbeeld van een nominale variabele is “Kledingwinkels”. Je kunt de data bijvoorbeeld verdelen over Zara, H&M, Only en Primark, maar je kunt die kledingwinkels niet op een natuurlijke, logische manier rangschikken.
Een voorbeeld van een ordinale variabele is “Leeftijd”. Je kunt de data bijvoorbeeld verdelen over 0-18, 19-34, 35-49 en 50+, en deze categorieën kun je in een logische volgorde zetten.
Nominale data kunnen worden verdeeld over categorieën (waarbij ieder datapunt maar in één categorie hoort) en de categorieën kunnen niet worden gerangschikt op een logische of natuurlijke manier.
Een voorbeeld van een nominale variabele is “vervoersmiddel”. Deze zou bijvoorbeeld uit de categorieën fiets, auto, bus, trein, metro en tram kunnen bestaan. Die vervoersmiddelen kunnen niet op een logische manier worden geordend, want het maakt bijvoorbeeld niet uit of je start met de fiets of de auto.
In het geval van een ordinale variabele, zoals “opleidingsniveau” zou je de opleidingsniveaus vmbo, havo, vwo wel op een logische manier kunnen rangschikken.
Het nominale meetniveau is het minst complexe en minst precieze meetniveau.
De data kunnen worden verdeeld over verschillende categorieën van de variabele.
De categorieën kunnen op een logische, natuurlijke manier worden gerangschikt.
Het ordinale meetniveau verschilt van het intervalmeetniveau, omdat de afstand tussen twee categorieën niet gelijk is of onbekend is.
Stel je hebt de categorieën beginner, gevorderde en expert. Het is niet mogelijk om aan te geven of een beginner net zoveel verschilt van een gevorderde als een gevorderde van een expert.
Nog vragen?
Vraag het ons
Kom je ergens niet uit? Geen probleem, wij staan altijd voor je klaar.
De Scribbr Bronnengenerator is ontwikkeld met behulp van het open-source Citation Style Language (CSL)-project en Frank Bennett’s citeproc-js. Het is dezelfde technologie die wordt gebruikt door tientallen andere populaire bronnengenerators, waaronder Mendeley en Zotero.
Je kunt alle citatiestijlen en talen vinden die in de Scribbr Citation Generator worden gebruikt in onze openbaar toegankelijke repository op Github. De meeste referentiestijlen worden door de Bronnengenerator ondersteund. Zo hebben we onder andere een APA Generator en een MLA Generator.
Scribbr gebruikt geavanceerde plagiaatdetectietechnologie die vergelijkbaar is met de software die door de meeste universiteiten en uitgevers wordt gebruikt, waardoor je verzekerd bent van dezelfde of zeer vergelijkbare resultaten.
De add-on AI Detector wordt aangestuurd door Scribbrs eigen software en is in staat om teksten gegenereerd door ChatGPT, Gemini en andere AI-tools met hoge nauwkeurigheid te detecteren.
 .
.




 .
. en
en  .
. .
.


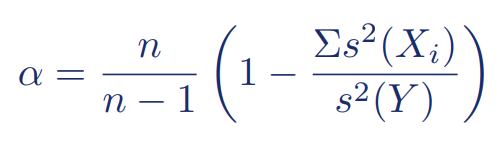
 .
. en
en  .
.
