Descriptieve of beschrijvende statistiek | Uitleg & Voorbeelden
Met descriptieve of beschrijvende statistiek orden je de data en vat je de kenmerken van je dataset samen. Een dataset is een verzameling reacties of observaties van een steekproef of een hele populatie.
Bij kwantitatief onderzoek begin je aan je statistische analyse na afronding van de dataverzameling. Bij de eerste stap beschrijf je de kenmerken van de antwoorden, zoals het gemiddelde van een variabele (bijvoorbeeld leeftijd), of de relatie tussen twee variabelen (bijvoorbeeld tussen leeftijd en creativiteit).
Bij de volgende stap kijk je naar toetsende of inferentiële statistieken, die je helpen beslissen of de data je hypothese bevestigen en of het resultaat generaliseerbaar is naar een grotere populatie.
Soorten beschrijvende statistieken
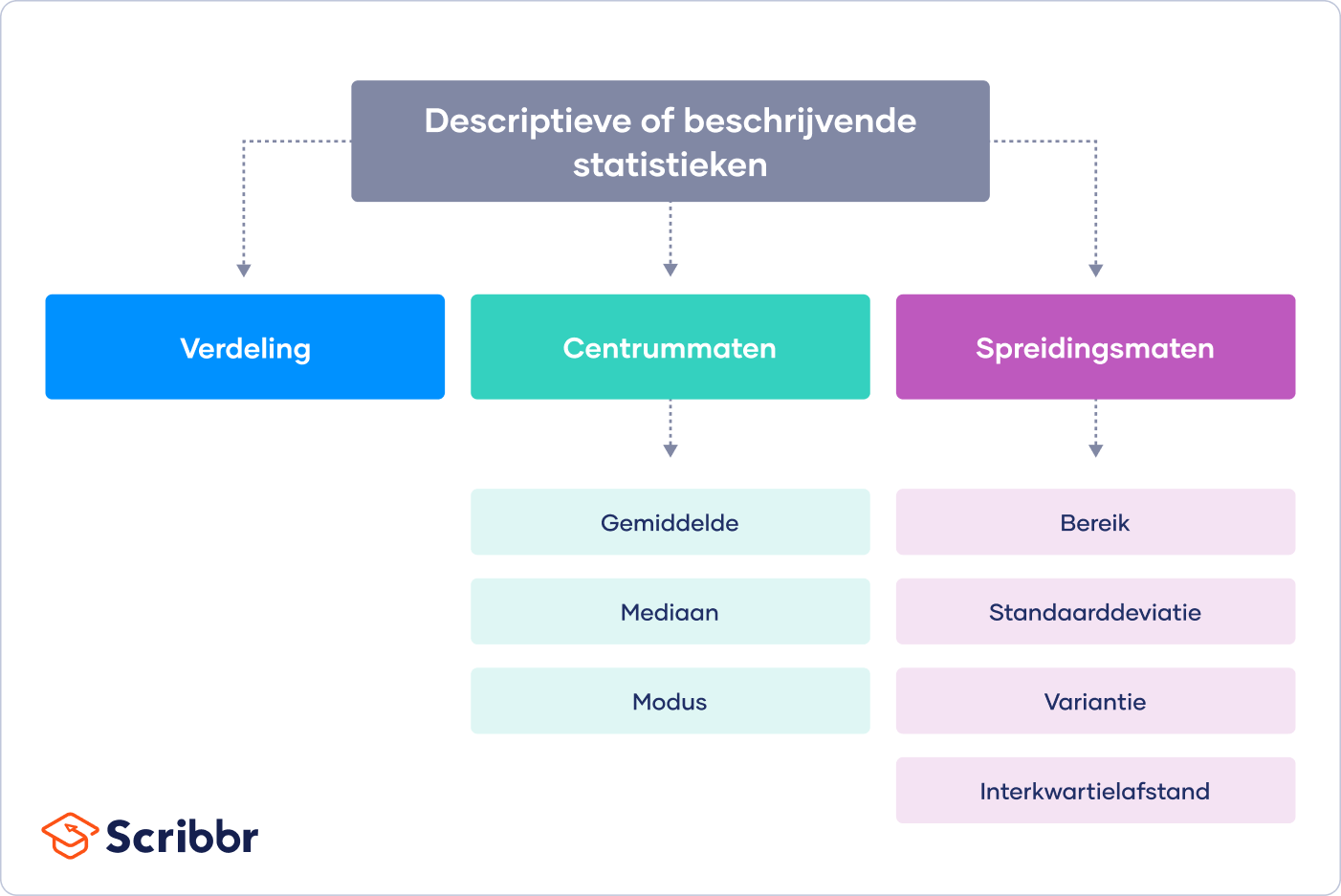
Er zijn drie belangrijke soorten beschrijvende statistieken:
- De verdeling heeft betrekking op de frequentie voor iedere waarde.
- De centrale tendens gaat over de gemiddelden voor de waarden.
- De spreiding (of variabiliteit) heeft te maken met de mate waarin waarden in de dataset verspreid zijn.
Je kunt deze statistieken toepassen op één variabele tegelijk bij een univariate analyse, of op twee of meer variabelen in het geval van een bivariate of multivariate analyse.
- Naar een bibliotheek gaan
- Naar een bioscoop gaan
- Naar een dierentuin gaan
Je dataset bevat de verzameling reacties op de enquête. Nu kun je beschrijvende statistieken gebruiken om een overzicht te geven van de frequentie waarmee elke activiteit is gedaan (verdeling), de gemiddelden voor elke activiteit (centrale tendens) en de spreiding van de reacties voor iedere activiteit (variabiliteit).


Frequentieverdeling (frequency distribution)
Een dataset bestaat uit een verzameling van waarden of scores. Je kunt de frequentie waarmee iedere waarde voorkomt samenvatten in een tabel, bijvoorbeeld door absolute cijfers of percentages te gebruiken.
| Gender | Aantal |
|---|---|
| Man | 182 |
| Vrouw | 235 |
| Anders | 27 |
Uit deze tabel kun je opmaken dat meer vrouwen meededen aan het onderzoek dan mannen of mensen met een andere genderidentiteit.
| Bibliotheekbezoeken in het afgelopen jaar | Percentage |
|---|---|
| 0–4 | 6% |
| 5–8 | 20% |
| 9–12 | 42% |
| 13–16 | 24% |
| 17+ | 8% |
Uit deze tabel kun je opmaken dat de meeste mensen de bibliotheek tussen de 9 en 12 keer hebben bezocht het afgelopen jaar.
Centrummaten
Je schat het centrum of midden van een dataset met behulp van centrummaten (measures of central tendency). Je kunt het centrum vinden met behulp van het gemiddelde, de mediaan en de modus.
In deze voorbeelden laten we zien hoe je de drie centrummaten handmatig kunt berekenen aan de hand van de eerste zes antwoorden op onze enquête. In de meeste gevallen kan de tool waarmee je je dataset analyseert (zoals Excel of SPSS) deze maten automatisch voor je berekenen.
Het gemiddelde (mean of M) is de meest gebruikte methode om het centrum te vinden.
Om het gemiddelde te bepalen, tel je alle antwoorden bij elkaar op en deel je de som door het totale aantal antwoorden (N).
| Dataset | 15, 3, 12, 0, 24, 3 |
|---|---|
| Som van alle waarden | 15 + 3 + 12 + 0 + 24 + 3 = 57 |
| Totale aantal antwoorden | N = 6 |
| Gemiddelde | Deel de som van alle waarden door N om M te vinden: 57/6 = 9,5 |
De mediaan (median) is de waarde die zich precies in het midden van de dataset bevindt als de waarden van klein naar groot staan.
Om de mediaan te bepalen, zet je eerst alle waarden in de juiste volgorde (van klein naar groot). De mediaan is de middelste waarde. Als twee nummers middelste waarde vormen, tel je deze twee bij elkaar op, en deel je ze door 2.
| Dataset op volgorde | 0, 3, 3, 12, 15, 24 |
|---|---|
| Middelste nummers | 3, 12 |
| Mediaan | Bepaal het gemiddelde van de twee nummers in het midden om de mediaan te vinden: (3 + 12)/2 = 7,5 |
De modus (mode) is de waarde die het vaakst voorkomt. Een dataset kan geen modus, één modus of meer dan één modus hebben (bij gelijke frequenties).
Om de modus te vinden, zoek je de antwoordoptie die het vaakst voorkomt.
| Dataset | 0, 3, 3, 12, 15, 24 |
|---|---|
| Modus | Zoek de vaakst voorkomende respons: 3 |
Spreidingsmaten
Spreidingsmaten (measures of variability) laten zien in welke mate de antwoorden verspreid zijn rondom het gemiddelde. Het bereik, de standaarddeviatie en variantie zeggen alle drie iets over de spreiding.
Bereik
Het bereik of de spreidingsbreedte (range) geeft je een idee van hoe ver de meest extreme antwoordopties uit elkaar liggen. Om het bereik te vinden, trek je de laagste waarde van de hoogste waarde af.
Bereik: 24 – 0 = 24
Standaarddeviatie of standaardafwijking
De standaarddeviatie (ook wel standaardafwijking, standard deviation of s) is de gemiddelde hoeveelheid variabiliteit in je dataset. Deze maat vertelt je hoe ver iedere score gemiddeld van het gemiddelde verwijderd is. Des te groter de standaarddeviatie, des te meer variabel je dataset is.
Er zijn zes stappen om de standaarddeviatie te berekenen (al kun je deze maat in Excel of SPSS automatisch laten berekenen).
- Maak een lijst van alle scores en vind het gemiddelde.
- Trek het gemiddelde af van iedere score om de afstand (afwijking) tot het gemiddelde te berekenen.
- Bereken voor iedere afwijking het kwadraat.
- Tel alle gekwadrateerde afwijkingen bij elkaar op.
- Deel de som van de gekwadrateerde afwijkingen door N – 1.
- Trek de wortel van het gevonden nummer bij stap 5.
| Ruwe data | Afwijking van het gemiddelde | Gekwadrateerde afwijking |
|---|---|---|
| 15 | 15 – 9,5 = 5,5 | 30,25 |
| 3 | 3 – 9,5 = -6,5 | 42,25 |
| 12 | 12 – 9,5 = 2,5 | 6,25 |
| 0 | 0 – 9,5 = -9,5 | 90,25 |
| 24 | 24 – 9,5 = 14,5 | 210,25 |
| 3 | 3 – 9,5 = -6,5 | 42,25 |
| M = 9,5 | Som = 0 | Som van de kwadraten = 421,5 |
Stap 5: 421,5/5 = 84,3
Stap 6: √84,3 = 9,18
De standaarddeviatie = 9,18, waardoor je kunt stellen dat iedere score gemiddeld genomen 9,18 punten van het gemiddelde verwijderd is.
Variantie
De variantie (variance) is het gemiddelde van de kwadratische afwijkingen van het gemiddelde. Deze maat zegt iets over de mate van spreiding in een dataset. Des te meer spreiding er is, des te groter is de variatie in relatie tot het gemiddelde.
Om de variantie te berekenen, neem je het kwadraat van de standaarddeviatie. Het symbool voor variantie is s2.
s = 9,18
s2 = 84,3
Lees waarom zo veel studenten Scribbr inschakelen
Univariate beschrijvende statistieken
Univariate beschrijvende statistieken richten zich op slechts één variabele tegelijk. Het is belangrijk om gegevens voor iedere variabele afzonderlijk te onderzoeken met behulp van meerdere maten voor verdeling, centrale tendens en spreiding. Je kunt programma’s als SPSS en Excel gebruiken om deze eenvoudig te berekenen.
| Bibliotheekbezoeken | |
|---|---|
| N | 6 |
| Gemiddelde | 9,5 |
| Mediaan | 7,5 |
| Modus | 3 |
| Standaarddeviatie | 9,18 |
| Variantie | 84,3 |
| Bereik | 24 |
Als je enkel het gemiddelde gebruikt als centrummaat, kan je beeld van het “midden” van de dataset vertekend zijn door extreme waarden (uitbijters of outliers). De mediaan en modus zijn hier minder gevoelig voor.
Ook het bereik is gevoelig voor extreme waarden, en daarom is het belangrijk om ook de standaarddeviatie en variantie te bepalen om een beeld te krijgen van de spreiding.
Bivariate beschrijvende statistieken
Als je data hebt verzameld voor meer dan één variabele, kun je bivariate of multivariate beschrijvende statistieken gebruiken om te onderzoeken of er relaties bestaan tussen je variabelen.
Bij een bivariate analyse kijk je naar de frequentie en spreiding van twee variabelen tegelijkertijd, om te bepalen of ze samen variëren. Je kunt ook de centrale tendens van beide variabelen bekijken voordat je verdere statistische analyses uitvoert.
Multivariate analyse is hetzelfde als bivariate analyse, maar dan met meer dan twee variabelen.
Kruistabellen
In een kruistabel (contingency table) laat iedere cel de kruising tussen twee variabelen zien. In de meeste gevallen zet je een onafhankelijke variabele (zoals leeftijdscategorie) in de kolommen (verticaal) en een afhankelijke variabele (zoals activiteit) in de rijen (horizontaal). In een kruistabel kun je de relatie tussen variabelen zien.
| Aantal bibliotheekbezoeken in het afgelopen jaar | |||||
|---|---|---|---|---|---|
| Groep | 0–4 | 5–8 | 9–12 | 13–16 | 17+ |
| Kind | 32 | 68 | 37 | 23 | 22 |
| Volwassene | 36 | 48 | 43 | 83 | 25 |
Het is makkelijker om een kruistabel te interpreteren als de onbewerkte gegevens (ruwe data) worden omgezet in percentages. Hierdoor kun je alle rijen met elkaar vergelijken. Als je percentages gebruikt voor je kruistabel, voeg je een N toe voor iedere onafhankelijke variabele.
| Bibliotheekbezoeken in het afgelopen jaar (percentages) | ||||||
|---|---|---|---|---|---|---|
| Groep | 0–4 | 5–8 | 9–12 | 13–16 | 17+ | N |
| Kind | 18% | 37% | 20% | 13% | 12% | 182 |
| Volwassene | 15% | 20% | 18% | 35% | 11% | 235 |
Uit deze tabel blijkt beter dat vergelijkbare percentages kinderen en volwassenen meer dan 17 keer per jaar naar een bibliotheek gingen. Ook blijkt dat kinderen over het algemeen tussen de 5 en 8 keer per jaar gingen, en volwassenen tussen de 13 en 16 keer.
Scatterplots
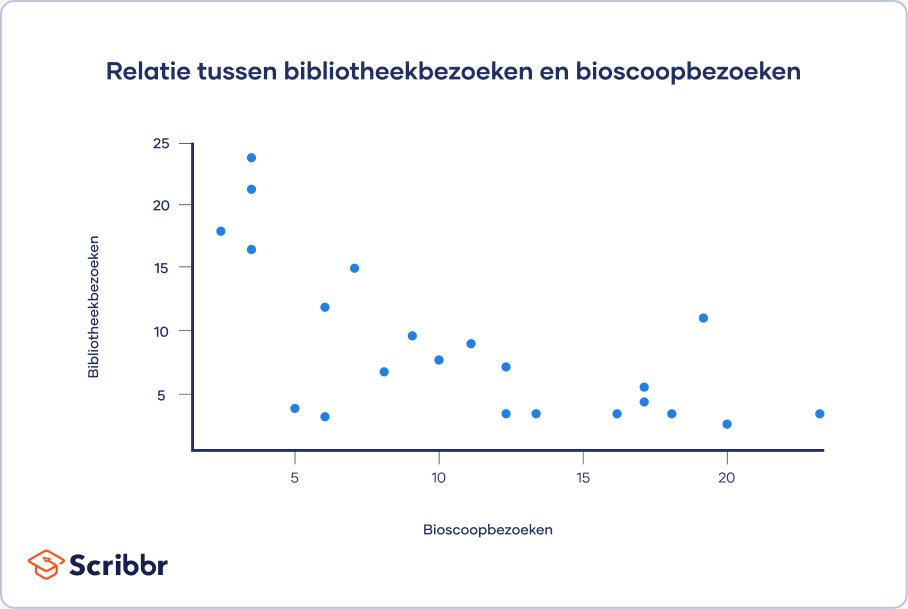
Een scatterplot (ook wel spreidingsgrafiek genoemd) is een grafiek die de relatie tussen twee of drie variabelen laat zien. De grafiek vormt een visuele weergave van de sterkte van een relatie.
In een scatterplot plot je een variabele op de x-as en een andere op de y-as. Ieder datapunt vormt een punt in de grafiek.
Uit je scatterplot blijkt dat naarmate het aantal films dat in bioscopen wordt gezien toeneemt, het aantal bezoeken aan de bibliotheek afneemt. Op basis van een visuele beoordeling van een mogelijk lineair verband, voer je verdere correlatie- en regressieanalyses uit.
Veelgestelde vragen
Citeer dit Scribbr-artikel
Als je naar deze bron wilt verwijzen, kun je de bronvermelding kopiëren of op “Citeer dit Scribbr-artikel” klikken om de bronvermelding automatisch toe te voegen aan onze gratis Bronnengenerator.
Merkus, J. (2021, 19 oktober). Descriptieve of beschrijvende statistiek | Uitleg & Voorbeelden. Scribbr. Geraadpleegd op 23 juni 2026, van https://www.scribbr.nl/statistiek/beschrijvende-statistiek/
