Gepubliceerd op
30 september 2022
door
Pritha Bhandari.
Bijgewerkt op
25 april 2023.
Attrition bias (ook wel (selectieve) uitvalsbias genoemd) is een vorm van selectiebias die optreedt als de participanten die uitvallen tijdens een onderzoek systematisch verschillen van degenen die in het onderzoek blijven.
Attrition is de uitval van participanten in een onderzoek. Het wordt ook wel subject mortality genoemd, maar dat betekent niet dat de participanten per se overlijden!
Gepubliceerd op
26 augustus 2022
door
Pritha Bhandari.
Bijgewerkt op
17 oktober 2022.
Indruksvaliditeit (face validity) geeft aan in welke mate een meetinstrument de indruk wekt iets relevants te meten. Indruksvaliditeit (“validiteit op het eerste gezicht”) beantwoordt de vraag of een meting aan de oppervlakte relevant en geschikt lijkt om te meten wat het moet meten.
Soorten validiteitIndruksvaliditeit is één van de vier soorten validiteit die van belang zijn voor meetinstrumenten. De overige drie zijn:
Constructvaliditeit (construct validity): Meet het onderzoeksinstrument daadwerkelijk het begrip dat het moet meten?
Inhoudsvaliditeit (content validity): Is het onderzoeksinstrument volledig representatief voor het te meten begrip?
Criteriumvaliditeit (criterion validity): Komen de resultaten van jouw onderzoeksinstrument overeen met die van andere, gevalideerde instrumenten?
Gepubliceerd op
22 augustus 2022
door
Pritha Bhandari.
Bijgewerkt op
17 januari 2024.
Outliers (uitschieters of uitbijters) zijn extreme waarden die verschillen van de meeste andere observatiepunten in een dataset. Ze kunnen een grote impact hebben op je statistische analyses en de resultaten van je hypothesetoetsing scheeftrekken (skew).
Het is belangrijk om potentiële uitschieters in je dataset zorgvuldig te identificeren en ze op de juiste manier te behandelen voor accurate resultaten.
Er zijn vier manieren om outliers te identificeren:
Gepubliceerd op
10 juli 2022
door
Pritha Bhandari.
Bijgewerkt op
8 maart 2023.
Constructvaliditeit (ook wel begripsvaliditeit genoemd) geeft aan in welke mate een onderzoeksinstrument het concept meet dat het moet meten. Dit is cruciaal om de algemene validiteit van een onderzoeksmethode te kunnen vaststellen.
Het beoordelen van de constructvaliditeit (construct validity) is vooral belangrijk als je iets onderzoekt wat niet direct gemeten of geobserveerd kan worden, zoals intelligentie, zelfvertrouwen of stemming. Om deze constructen te kunnen meten, heb je meerdere waarneembare of meetbare indicatoren nodig.
Soorten validiteitConstructvaliditeit is één van de vier soorten validiteit die van belang zijn voor meetinstrumenten. De overige drie zijn:
Inhoudsvaliditeit (content validity): Is het onderzoeksinstrument volledig representatief voor het te meten begrip?
Indruksvaliditeit (face validity): Lijkt de inhoud van het meetinstrument geschikt (relevant) voor je onderzoeksdoel?
Criteriumvaliditeit (criterion validity): Komen de resultaten van jouw onderzoeksinstrument overeen met die van andere, gevalideerde instrumenten?
Constructvaliditeit en inhoudsvaliditeit vormen samen de betekenisvaliditeit.
Gepubliceerd op
12 november 2021
door
Pritha Bhandari.
Bijgewerkt op
1 maart 2023.
Een parameter is een waarde die een hele populatie beschrijft (bijvoorbeeld het populatiegemiddelde), terwijl een statistiek een getal is dat een steekproef beschrijft (bijvoorbeeld het steekproefgemiddelde).
Het doel van kwantitatief onderzoek is om kenmerken van populaties te onderzoeken door parameters te bepalen. In de praktijk is het vaak te tijdrovend of moeilijk om voor elk lid van de populatie data te verzamelen. In plaats daarvan worden data verzameld voor een steekproef (subset van de populatie).
Je kunt steekproefstatistieken gebruiken om onderbouwde voorspellingen te doen over populatieparameters (met behulp van toetsende of inferentiële statistiek).
Gepubliceerd op
10 november 2021
door
Pritha Bhandari.
Bijgewerkt op
1 september 2022.
Statistische power is de kans dat een statistische toets een effect detecteert dat daadwerkelijk aanwezig is. Het kan hierbij bijvoorbeeld om een correlatie, causale relatie of verschil tussen groepen gaan. Statistisch power wordt ook wel gevoeligheid, onderscheidend vermogen of statistical power genoemd.
Als een toets veel power heeft, is de kans groot dat deze een daadwerkelijk bestaand effect kan detecteren. Als de toets weinig power heeft, betekent dat er slechts een kleine kans is dat de toets een effect gaat vinden en dat de resultaten waarschijnlijk vertekend zijn door willekeurige en systematische fouten.
De power wordt voornamelijk beïnvloed door de steekproefomvang, de effectgrootte en het significantieniveau. Je kunt een poweranalyse gebruiken om de benodigde steekproefomvang voor een onderzoek te bepalen.
Gepubliceerd op
9 november 2021
door
Pritha Bhandari.
Bijgewerkt op
8 augustus 2022.
Een Type I-fout is een fout-positieve conclusie (false positive), terwijl een Type II-fout een fout-negatieve conclusie (false negative) is.
Je kunt nooit met 100% zekerheid een conclusie trekken op basis van statistiek, dus het risico op een van deze twee type fouten is onvermijdelijk als je hypothesen toetst.
Het risico dat je een Type I-fout maakt, is gelijk aan het significantieniveau (alfa of α), terwijl het risico op het maken van een Type II-fout gelijk is aan bèta (β). Deze risico’s kunnen worden geminimaliseerd door goed na te denken over je onderzoeksdesign.
Voorbeeld: Type I- vs Type II-foutJe besluit je te laten testen op corona, omdat je milde symptomen hebt. Er zijn twee fouten die mogelijk kunnen optreden:
Type I-fout (Type I error): het testresultaat laat zien dat je corona hebt, maar dat heb je eigenlijk niet.
Type II-fout (Type II error): het testresultaat laat zien dat je geen corona hebt, maar dat heb je eigenlijk wel.
Gepubliceerd op
5 november 2021
door
Pritha Bhandari.
Bijgewerkt op
22 augustus 2022.
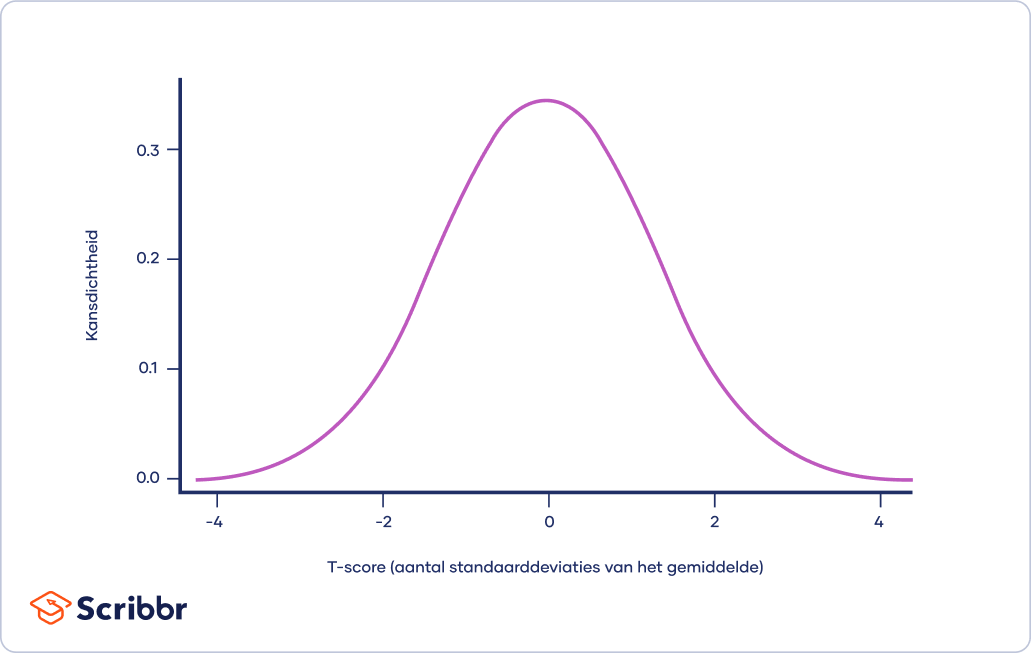
De t-verdeling (ook wel t-distribution of Student’s t-distribution genoemd) wordt gebruikt als de data bij benadering normaal verdeeld zijn (en dus een klokvorm volgen), maar waarbij de populatievariantie onbekend is. De variantie in een t-verdeling wordt geschat op basis van het aantal vrijheidsgraden van de dataset (totaal aantal waarnemingen min 1).
De t-verdeling is een variant op de normale verdeling, maar deze wordt gebruikt voor kleinere steekproeven, waarbij de variantie onbekend is.
Bij statistiek wordt de t-verdeling meestal gebruikt om:
De kritische waarden voor een betrouwbaarheidsinterval te vinden als de data ongeveer normaal verdeeld zijn.
De corresponderende p-waarde te vinden van een statistische toets die de t-verdeling gebruikt (t-toets, regressieanalyse).
Gepubliceerd op
5 november 2021
door
Pritha Bhandari.
Bijgewerkt op
22 augustus 2022.
De effectgrootte (effect size) laat zien hoe betekenisvol de relatie tussen variabelen of het verschil tussen groepen is. Het zegt iets over de praktische relevantie (ook wel praktische significantie genoemd) van een onderzoeksresultaat.
Als een effect groot is, heeft het onderzoeksresultaat praktische implicaties, terwijl een klein effect waarschijnlijk ook maar beperkte praktische implicaties heeft.
Let opIn het Nederlands gebruik je de komma als decimaalteken, maar bij het rapporteren van statistische resultaten is het gebruikelijk om de punt als decimaalteken te gebruiken. Ook wordt vaak de 0 voor het decimaalteken weggelaten (.05 in plaats van 0.05).
Gepubliceerd op
4 november 2021
door
Pritha Bhandari.
Bijgewerkt op
28 oktober 2022.
Als een resultaat statistisch significant is, betekent dit dat het onwaarschijnlijk is dat het alleen door toeval of willekeurige factoren kan worden verklaard. Met andere woorden: er is slechts een zeer kleine kans dat een statistisch significant resultaat voorkomt als er geen echt effect zou zijn in het onderzoek.
De p-waarde (ook wel p-value, overschrijdingskans of kanswaarde genoemd) geeft informatie over de statistische significantie van een resultaat. In de meeste onderzoeken wordt een p-waarde van 0.05 of minder als statistisch significant beschouwd, maar deze drempel kan ook hoger of lager zijn.
Let opIn het Nederlands gebruik je de komma als decimaalteken, maar bij het rapporteren van statistische resultaten is het gebruikelijk om de punt als decimaalteken te gebruiken. Ook wordt vaak de 0 voor het decimaalteken weggelaten (.05 in plaats van 0.05).