Wat is Deep Learning? | Betekenis & Voorbeelden
Deep learning is een soort technologie waarmee computers kunnen simuleren hoe menselijke hersenen werken.
Specifiek is deep learning een methode die computers leert om zelfstandig te leren en beslissingen te nemen, zonder ze expliciet te programmeren. In plaats van een computer precies te vertellen waarnaar hij moet zoeken, laten we de computer veel voorbeelden zien en laten we hem zelf leren.
Door een computer veel foto’s van Duitse herders te laten zien, kun je hem trainen om deze beelden te analyseren en zelf Duitse herders te leren herkennen. Met genoeg training op verschillende rassen kan de computer bepalen om welk hondenras het gaat wanneer je hem een nieuwe foto laat zien (die niet in de trainingsdata voorkwam).
Deep learning is de technologie achter veel populaire AI-toepassingen zoals chatbots (e.g., ChatGPT), virtuele assistenten en zelfrijdende auto’s.
Inhoudsopgave
- Hoe werkt deep learning?
- Deep learning vs machine learning
- Wat zijn verschillende soorten “learning”?
- Wat is de rol van AI bij deep learning?
- Wat zijn enkele praktische toepassingen van deep learning?
- Voordelen en beperkingen van deep learning
- Andere interessante artikelen
- Veelgestelde vragen over deep learning
Hoe werkt deep learning?
Deep learning maakt gebruik van kunstmatige neurale netwerken die de structuur van het menselijk brein nabootsen. Net als de onderling verbonden neuronen in onze hersenen die informatie verzenden en ontvangen vormen neurale netwerken (virtuele) lagen die samenwerken in een computer.
Deze netwerken bestaan uit meerdere lagen van knooppunten, ook wel neuronen genoemd. Elk neuron ontvangt input van de vorige laag, verwerkt die en geeft de input door aan de volgende laag. Op deze manier leert het model geleidelijk steeds complexere patronen in de gegevens te herkennen.
Het bijvoeglijk naamwoord “deep” in “deep learning” verwijst naar het gebruik van meerdere lagen in het netwerk waardoor de gegevens worden verwerkt.
Er zijn verschillende soorten neurale netwerken, maar in zijn eenvoudigste vorm bevat een diep lerend neuraal netwerk:
- Een inputlaag: Dit is waar we de data, zoals een afbeelding of tekst, invoeren voor verwerking.
- Meerdere verborgen lagen: Hier vindt het meeste leren plaats: neurale netwerken leren om belangrijke patronen en kenmerken in de gegevens te identificeren. Naarmate de data door het netwerk stromen, neemt de complexiteit van de geleerde beeldkenmerken toe. De eerste verborgen laag kan eenvoudige patronen leren detecteren, zoals de randen van een afbeelding, terwijl de laatste laag complexere kenmerken leert detecteren, zoals textuur of vorm, gerelateerd aan het type object dat we proberen te herkennen. Uiteindelijk kan het netwerk bepalen welke kenmerken (e.g., snuit) het belangrijkst zijn om het ene ras van het andere te onderscheiden.
- Een outputlaag: Hier wordt de uiteindelijke voorspelling of classificatie uitgevoerd. Als het netwerk wordt getraind om hondenrassen te herkennen, kan de uitvoerlaag de waarschijnlijkheid geven dat de invoer een Duitse herder of een ander ras is.
Het is ook mogelijk om een deep learning model te trainen om achteruit te bewegen, van uitvoer naar invoer. Dit proces stelt het model in staat om fouten te berekenen en aanpassingen te maken zodat de volgende voorspellingen of andere output nauwkeuriger zijn.

Deep learning vs machine learning
Deep learning is een gespecialiseerde vorm van machine learning die werd ontwikkeld om machine learning efficiënter te maken. In wezen is deep learning een evolutie van machine learning.
Machine learning (ML) is een onderdeel van kunstmatige intelligentie (KI of AI), de tak van de computerwetenschap waarin machines wordt geleerd om taken uit te voeren die normaal gesproken worden geassocieerd met menselijke intelligentie, zoals besluitvorming en op taal gebaseerde interactie.
ML is de ontwikkeling van computerprogramma’s die toegang hebben tot data en deze data kunnen gebruiken om zelf te leren. Echter, deep learning en machine learning verschillen op het gebied van:
- Het type data waarmee ze werken;
- De methoden waarmee ze leren.
Traditionele ML vereist gestructureerde, gelabelde data (e.g., kwantitatieve data in de vorm van getallen en waarden). Menselijke experts identificeren handmatig relevante kenmerken uit de data en ontwerpen algoritmen (i.e., een set stapsgewijze instructies) voor de computer om deze kenmerken te verwerken. ML is meer afhankelijk van menselijke tussenkomst om te leren.
Aan de andere kant kunnen deep learning-modellen ongestructureerde data zoals audiobestanden of berichten op sociale media verwerken en bepalen welke kenmerken verschillende categorieën data van elkaar onderscheiden, zonder menselijke tussenkomst. Met andere woorden, een deep learning-netwerk heeft alleen data en een taakbeschrijving nodig en het netwerk leert vanzelf hoe de taak automatisch moet worden uitgevoerd.
| Deep learning | Machine learning (ML) |
|---|---|
| Een subset van machine learning | Een subset van kunstmatige intelligentie |
| Vereist grote datasets voor training | Kan getraind worden op kleine datasets |
| Leert zelf | Menselijke input is nodig om fouten te corrigeren en het leren te verbeteren |
| Werkt met ongestructureerde data (e.g., tekst, audiobestanden, berichten op sociale media) | Kan alleen gestructureerde data verwerken om voorspellingen te doen (e.g., data, namen, creditcardnummers) |
| Blijft verbeteren naarmate de dataset groter wordt | Bereikt een bepaald prestatieniveau (plafond) |
| Vereist veel rekenkracht | Vereist minder rekenkracht |
Wat zijn verschillende soorten “learning”?
Deep learning gebruikt net als machine learning verschillende leertechnieken:
- Supervised learning wordt gebruikt wanneer de trainingsdata bestaan uit gelabelde voorbeelden, i.e., waarin het juiste antwoord is opgenomen. Bijvoorbeeld een dataset met afbeeldingen van verschillende honden en het bijbehorende hondenras.
- Unsupervised learning is de taak van het leren van ongelabelde data. Het algoritme detecteert patronen in de data en classificeert de informatie zelf. De dataset kan bijvoorbeeld bestaan uit afbeeldingen van verschillende dieren maar geen beschrijving (label). Het algoritme zal zelf leren hoe dieren die tot dezelfde soort behoren, gegroepeerd kunnen worden door overeenkomsten en verschillen te identificeren.
- Reinforcement learning (RL) is de taak van leren door vallen en opstaan. Hier leert het algoritme door beloningen en straffen aan de hand van interactie met zijn omgeving. Door bijvoorbeeld een videospel te spelen en deze manier van leren te benutten, kan een algoritme uitzoeken welke acties de beloningen maximaliseren (i.e., tot de hoogste score leiden). Deep reinforcement learning is een gespecialiseerde vorm van RL die diepe neurale netwerken gebruikt om complexere problemen op te lossen.
Wat is de rol van AI bij deep learning?
Terwijl kunstmatige intelligentie (KI of AI) de brede wetenschap is van het gebruik van technologie om machines en computers te bouwen die menselijke vaardigheden nabootsen (e.g., zien, begrijpen, aanbevelingen doen), bootst deep learning meer specifiek de manier na waarop mensen bepaalde soorten kennis verwerven.
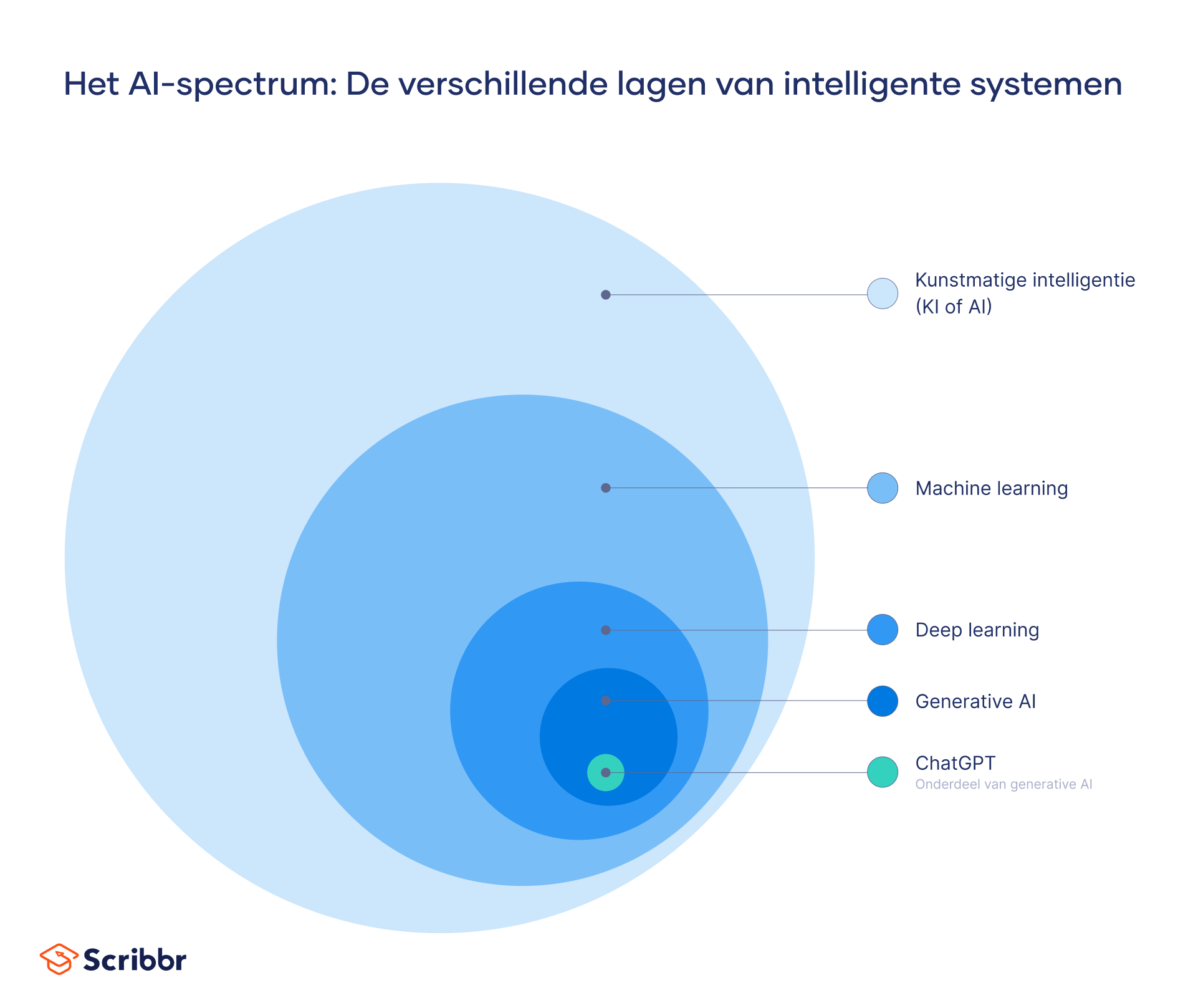
AI biedt het overkoepelende kader en de concepten die de leidraad vormen voor algoritmen en modellen voor deep learning. Op het gebied van deep learning helpt AI bij het definiëren van doelen en doelstellingen, evenals de methoden die worden gebruikt om ze te bereiken.
AI vergemakkelijkt de creatie en ontwikkeling van neurale netwerken. Deze neurale netwerken kunnen ingewikkelde patronen en representaties leren uit enorme hoeveelheden data. AI biedt de principes en technieken die nodig zijn om deze netwerken met succes te trainen, zodat ze hun prestaties kunnen verbeteren naarmate ze meer voorbeelden leren.
Bovendien begeleidt AI de evaluatie en optimalisatie van deep learning-modellen. AI helpt te bepalen welke modelarchitectuur, parameters en trainingsprocedures het meest geschikt zijn voor een bepaald probleem of een bepaalde activiteit.
ChatGPT maakt bijvoorbeeld gebruik van een type diep neuraal netwerk dat een large language model (LLM) wordt genoemd. Dit netwerk is getraind op enorme hoeveelheden informatie van het internet, waaronder websites, boeken, nieuwsartikelen en meer. ChatGPT maakt gebruik van deze training om tekst te genereren, vragen te beantwoorden en documenten samen te vatten.
Wat zijn enkele praktische toepassingen van deep learning?
Deep learning heeft een breed scala aan toepassingen in verschillende domeinen, waarbij de grenzen van wat computers kunnen voortdurend worden verlegd. Hier zijn enkele alledaagse toepassingen van deep learning.
Gepersonaliseerde aanbevelingen
Videostreamingdiensten (e.g., Amazon, Netflix) leren je voorkeuren om je suggesties te doen. Elke keer dat je aangeeft dat je een film of serie leuk vindt door hem helemaal af te kijken of toe te voegen aan je bibliotheek, werkt de dienst zijn algoritmes bij om je nauwkeurigere aanbevelingen te geven.
Als student kun je aanbevelingssystemen tegenkomen in online leerplatforms die relevante cursussen of studiemateriaal voorstellen op basis van je interesses en leergeschiedenis.
Natuurlijke taalverwerking (NLP)
Computers kunnen menselijke taal in gesproken en geschreven vorm steeds nauwkeuriger begrijpen en verwerken. Dit vermogen heeft een breed scala aan toepassingen, van chatbots en spraakgestuurde assistenten tot automatische tekstsamenvattingen en parafraseringstools (zoals Scribbrs gratis parafraseringstool en Scribbrs gratis samenvatter).
In onderzoek kan sentimentanalyse op basis van natural language processing (NLP) van berichten in sociale media onthullen of mensen positief, negatief of neutraal staan tegenover een merk, een product of een kwestie.
Computervisie
Computer vision verwijst naar het vermogen van de computer om objecten te herkennen en nuttige informatie uit afbeeldingen of video’s te halen. Met deep learning kunnen computers begrijpen waar ze naar “kijken” op een manier die vergelijkbaar is met mensen.
Dankzij deze toepassing kunnen autonome voertuigen verkeersborden en voetgangers herkennen, maar computervisie wordt ook gebruikt bij online content moderatie om onveilige of ongepaste content automatisch te blokkeren.
Voordelen en beperkingen van deep learning
Net als elke technologie heeft deep learning een aantal voordelen en beperkingen. Het is belangrijk om je hiervan bewust te zijn, zodat je beter begrijpt wat deep learning wel en niet kan.
Voordelen van deep learning
Deep learning heeft een aantal voordelen, zoals:
- Deep learning-algoritmen kunnen zowel gestructureerde als ongestructureerde data verwerken, zonder afhankelijk te zijn van een menselijke expert. Deep learning blinkt uit in het vinden van complexe patronen en relaties in data, waardoor het geschikt is voor taken als beeldherkenning, natuurlijke taalverwerking en spraakherkenning.
- Deep learning staat onafhankelijkheid toe bij het extraheren van relevante kenmerken. Kenmerkextractie is het proces van het vinden en markeren van belangrijke patronen of kenmerken in data die relevant zijn voor het oplossen van een bepaalde taak.
- De nauwkeurigheid blijft na verloop van tijd verbeteren met meer training en meer data.
- De technologie kan zichzelf corrigeren: na training is er weinig (of geen) menselijke tussenkomst nodig.
Beperkingen van deep learning
Toch heeft deep learning ook een aantal beperkingen:
- Inzichten uit deep learning zijn slechts zo goed als de data waarmee we het model trainen. Door te vertrouwen op niet-representatieve trainingsdata of data met gebrekkige informatie die historische ongelijkheden weerspiegelen, kunnen sommige deep learning-modellen menselijke vooroordelen over etniciteit, genderidentiteit, leeftijd, enzovoort repliceren of versterken. Dit wordt algoritmische bias genoemd.
- Deep learning-modellen hebben veel rekenkracht en opslagruimte nodig om complexe wiskundige berekeningen uit te voeren. Deze hardwarevereisten kunnen kostbaar zijn. In vergelijking met conventionele machine learning vergt deze aanpak bovendien meer tijd om te trainen.
- Deze modellen hebben een zogenaamd “black box” probleem. In deep learning-modellen is het besluitvormingsproces ondoorzichtig en dit proces kan niet worden uitgelegd op een manier die gemakkelijk door mensen kan worden begrepen. Als een autonoom voertuig bijvoorbeeld een voetganger verwondt, kunnen we het “denkproces” van het model niet achterhalen en precies zien welke factoren tot deze fout hebben geleid.
Andere interessante artikelen
Op zoek naar meer informatie over ChatGPT, AI tools, retoriek en onderzoeksbias? Bekijk onze artikelen met uitleg en voorbeelden!
Veelgestelde vragen over deep learning
Citeer dit Scribbr-artikel
Als je naar deze bron wilt verwijzen, kun je de bronvermelding kopiëren of op “Citeer dit Scribbr-artikel” klikken om de bronvermelding automatisch toe te voegen aan onze gratis Bronnengenerator.
Scharwächter, V. (2023, 22 juni). Wat is Deep Learning? | Betekenis & Voorbeelden. Scribbr. Geraadpleegd op 30 mei 2026, van https://www.scribbr.nl/ai-tools-gebruiken/wat-is-deep-learning/
