Wat is Machine Learning? | Betekenis & Voorbeelden
Machine learning (ML) is een tak van kunstmatige intelligentie (AI) en computerwetenschap die zich richt op het ontwikkelen van methoden waarmee computers kunnen leren en hun prestaties kunnen verbeteren. Het doel is om menselijke leerprocessen na te bootsen, zodat specifieke taken nauwkeurig kunnen worden uitgevoerd. De belangrijkste doelen van ML zijn:
- het classificeren van data op basis van ontwikkelde modellen (e.g., het detecteren van spam).
- voorspellingen doen over een bepaalde toekomstige uitkomst op basis van deze modellen (e.g., het voorspellen van huizenprijzen in een stad).
Machine learning heeft een breed scala aan toepassingen, waaronder vertalingen, voorspellingen van consumentenvoorkeuren en medische diagnoses.
Wat is machine learning?
Machine learning is een verzameling methoden die computerwetenschappers gebruiken om computers te trainen in leren. In plaats van precieze instructies te geven door ze te programmeren, geven de wetenschappers de computers een probleem om op te lossen en veel voorbeelden (i.e., combinaties van probleem-oplossing) om van te leren.
Een computer kan bijvoorbeeld de taak krijgen om foto’s van katten en foto’s van vrachtwagens te identificeren. Voor mensen is dit een eenvoudige taak, maar als we een uitputtende lijst zouden moeten maken van alle verschillende kenmerken van katten en vrachtwagens zodat een computer ze zou kunnen herkennen, zou dat heel moeilijk zijn. Als we alle mentale stappen die we nemen om deze taak te voltooien zouden moeten nalopen, zou dat ook moeilijk zijn (dit is een automatisch proces voor volwassenen, dus we zouden waarschijnlijk een stap of stukje informatie missen).
In plaats daarvan leert ML een computer op een manier die vergelijkbaar is met hoe peuters leren: door de computer een enorme hoeveelheid afbeeldingen met het label “kat” of “vrachtwagen” te laten zien, leert de computer de relevante kenmerken te herkennen die een kat of een vrachtwagen vormen. Vanaf dat moment kan de computer vrachtwagens en katten herkennen op foto’s die hij nog nooit “gezien” heeft (i.e., foto’s die niet gebruikt zijn om de computer te trainen).

Hoe werkt machine learning?
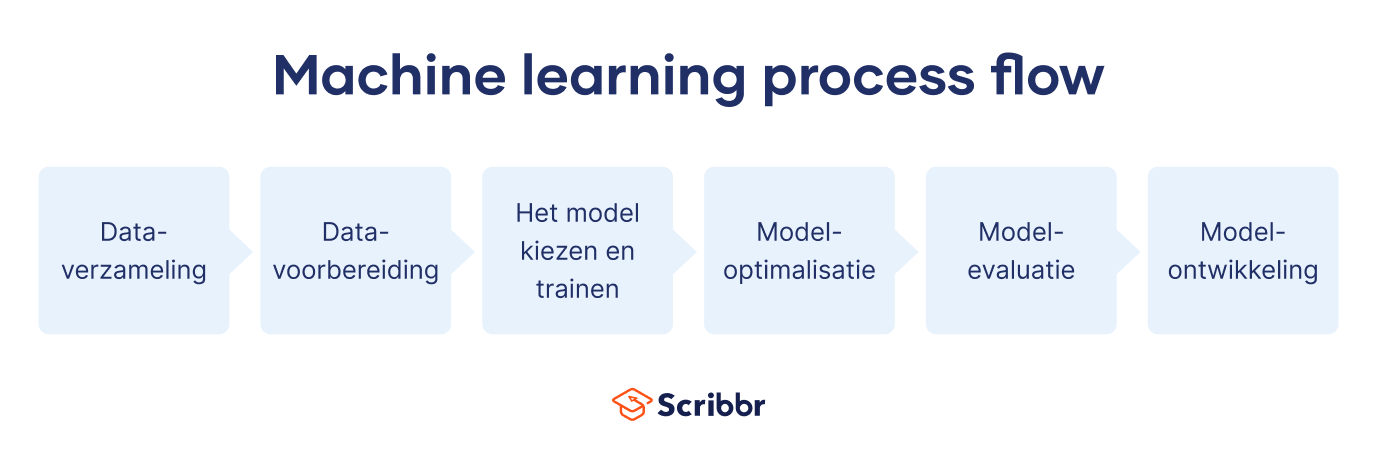
Het uitvoeren van machine learning omvat een reeks stappen:
- Dataverzameling: Machine learning begint met het verzamelen van data uit verschillende bronnen, zoals muziekopnames, patiëntgeschiedenissen of foto’s. Deze ruwe data worden vervolgens georganiseerd en voorbereid voor gebruik als trainingsdata, wat de informatie is die wordt gebruikt om de computer te leren.
- Datavoorbereiding: Het voorbereiden van de ruwe data omvat het opschonen van de data, het verwijderen van fouten en het formatteren op een manier die de computer kan begrijpen. Hierbij komt ook feature engineering of feature-extractie kijken, oftewel het selecteren van relevante informatie of patronen die de computer kunnen helpen bij het oplossen van een specifieke taak. Het is belangrijk dat ingenieurs grote datasets gebruiken zodat de trainingsinformatie voldoende gevarieerd is en dus representatief voor de populatie of het probleem.
- Het model kiezen en trainen: Afhankelijk van de taak kiezen de ingenieurs een geschikt model voor machine learning en beginnen ze met het trainingsproces. Het model is als het ware een hulpmiddel dat de computer helpt om de data te begrijpen. Tijdens de training leert het computermodel automatisch van de data door naar patronen te zoeken en vervolgens de interne instellingen aan te passen. De computer leert zichzelf in wezen om relaties te herkennen en voorspellingen te doen op basis van de patronen die het ontdekt.
- Modeloptimalisatie: Menselijke experts kunnen de nauwkeurigheid van het model verbeteren door de parameters of instellingen aan te passen. Door te experimenteren met verschillende configuraties proberen programmeurs het vermogen van het model te optimaliseren om precieze voorspellingen te doen of zinvolle patronen in de data te identificeren.
- Modelevaluatie: Als de training voorbij is, moeten ingenieurs controleren hoe goed het model presteert. Hiervoor gebruiken ze aparte data die niet in de trainingsdata zaten en dus nieuw zijn voor het model. Met deze evaluatiedata kunnen ze testen hoe goed het model kan generaliseren wat het heeft geleerd (i.e., het toepassen op nieuwe data die het nog nooit eerder is tegengekomen). Dit biedt ingenieurs ook inzichten voor verdere verbeteringen.
- Modelontwikkeling (model deployment): Nadat het model is getraind en geëvalueerd, wordt het gebruikt om voorspellingen te doen of patronen te identificeren in nieuwe, ongeziene data. Je gebruikt bijvoorbeeld nieuwe afbeeldingen van voertuigen en dieren als invoer en na analyse kan het getrainde model de afbeelding classificeren als “vrachtwagen” of “kat”. Het model blijft zich automatisch aanpassen om zijn prestaties te verbeteren.
Het is belangrijk om in gedachten te houden dat ML-implementatie een iteratieve cyclus doorloopt van het bouwen, trainen en inzetten van een machine learning-model: elke stap van de hele ML-cyclus wordt opnieuw doorlopen totdat het model genoeg iteraties heeft gehad om van de data te leren. Het doel is om een model te krijgen dat even goed kan presteren met nieuwe data.
Data zijn elk type informatie dat kan dienen als invoer voor een computer, terwijl een algoritme het wiskundige of computationele proces is dat de computer volgt om de data te verwerken, te leren en het model voor machine learning te creëren. Met andere woorden, data en algoritmen gecombineerd door training vormen het machine learning-model.
Soorten modellen voor machine learning
Modellen voor machine learning worden gecreëerd door algoritmen te trainen op grote datasets. Er zijn drie brede benaderingen of raamwerken (frameworks) voor hoe een model leert van de trainingsdata:
- Supervised learning wordt gebruikt wanneer de trainingsdata bestaan uit voorbeelden die duidelijk beschreven of gelabeld zijn. Hier heeft het algoritme een “supervisor” (i.e., een menselijke expert die optreedt als een leraar en de computer de juiste antwoorden geeft). De menselijke expert heeft de data al voorbereid en gelabeld, bijvoorbeeld in afbeeldingen van vrachtwagens en katten, die het algoritme gebruikt om te leren. Omdat de antwoorden in de data zijn opgenomen, kan het algoritme “zien” hoe nauwkeurig zijn antwoorden zijn en deze in de loop van de tijd verbeteren. Supervised learning wordt gebruikt voor classificatietaken (zoals het filteren van spam e-mails) en voorspellingstaken (zoals de toekomstige prijs van een aandeel).
- Unsupervised learning wordt gebruikt als de trainingsdata ongelabeld zijn. Het doel is om patronen, structuren of relaties in de data te verkennen en te ontdekken zonder specifieke richtlijnen. Clusteren is de meest voorkomende taak voor unsupervised learning. Het is een vorm van classificatie zonder vooraf gedefinieerde categorieën. Het gaat om het categoriseren van data in categorieën op basis van kenmerken die verborgen zijn in de data (bijvoorbeeld het segmenteren van een markt in soorten klanten). Hier probeert het algoritme gelijkaardige objecten te vinden en plaatst ze samen in een cluster of groep, zonder menselijke tussenkomst.
- Reinforcement learning (RL) is een andere benadering waarbij het computerprogramma leert door interactie met een omgeving. Hier is de taak of het probleem niet gerelateerd aan data, maar aan een omgeving zoals een videospel of een stadsstraat (in de context van zelfrijdende auto’s). Door vallen en opstaan kunnen computerprogramma’s met deze aanpak automatisch de beste acties binnen een bepaalde context bepalen om hun prestaties te optimaliseren. De computer krijgt feedback in de vorm van beloning of straf op basis van zijn acties en leert geleidelijk hoe hij een spel moet spelen of in een stad moet rijden.
Het juiste algoritme vinden
Algoritmes leveren de methoden voor supervised, unsupervised en reinforcement learning. Met andere woorden, ze bepalen hoe modellen precies leren van data, ze doen voorspellingen of maken classificaties, of ontdekken patronen binnen één van de methoden.
Het juiste algoritme vinden is tot op zekere hoogte een proces van trial-and-error, maar het hangt ook af van het type data dat beschikbaar is, de inzichten die je uit de data wilt halen en het einddoel van de taak van machine learning (e.g., classificatie of voorspelling). Een lineair regressiealgoritme wordt bijvoorbeeld voornamelijk gebruikt bij supervised learning voor het voorspellen van modellen, zoals het voorspellen van huizenprijzen of het schatten van de hoeveelheid regen.
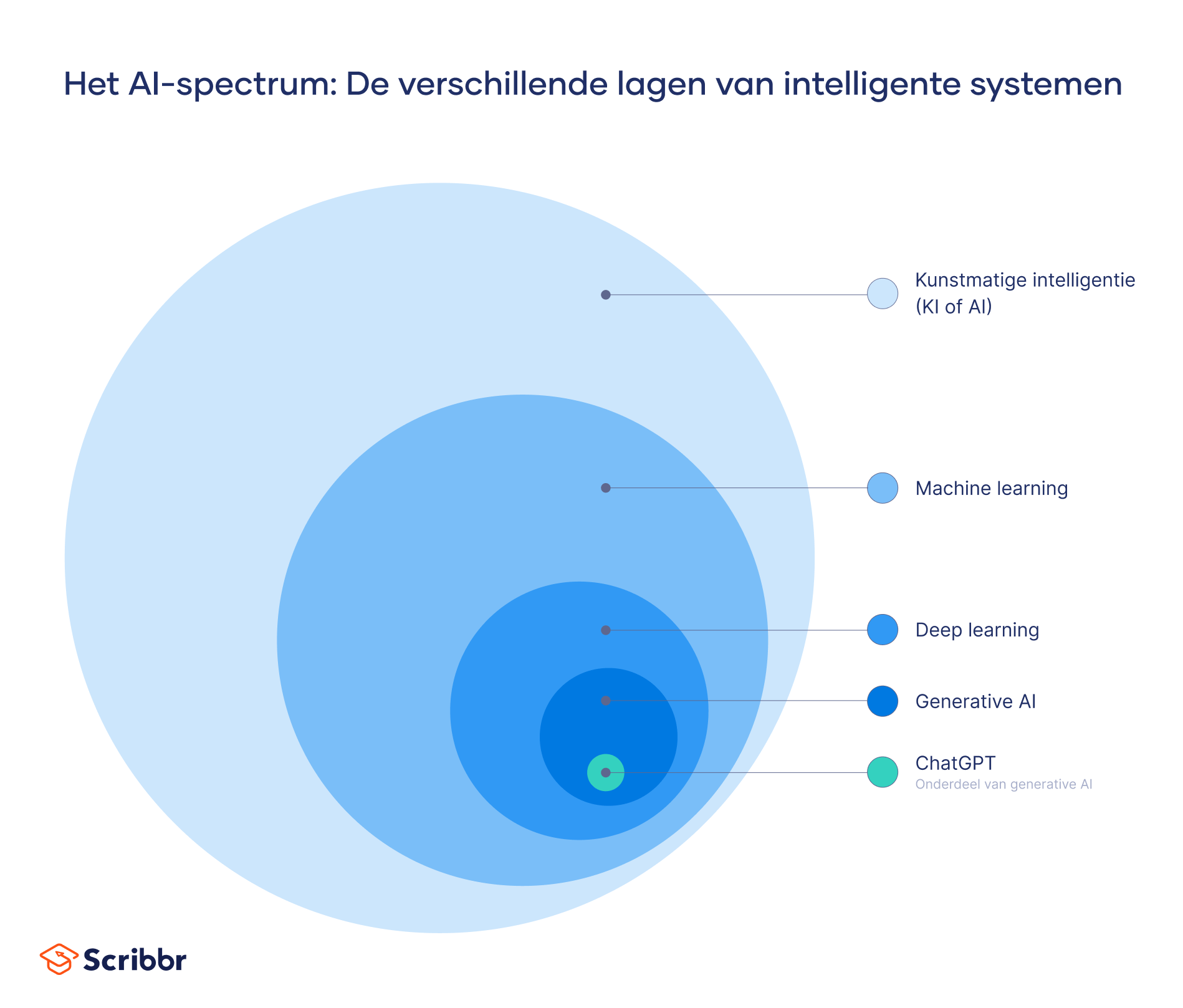
Machine learning vs deep learning
Machine learning en deep learning zijn beide subdomeinen van kunstmatige intelligentie. Deep learning is echter in feite een subgebied van machine learning. Het belangrijkste verschil tussen de twee is hoe het algoritme leert:
- Machine learning vereist menselijke tussenkomst. Een expert moet de data labelen en de kenmerken bepalen die ze onderscheiden. Het algoritme kan dan deze handmatig verkregen kenmerken of features gebruiken om een model te maken.
- Deep learning heeft geen gelabelde dataset nodig. Deze aanpak kan ongestructureerde data zoals foto’s of teksten verwerken en automatisch bepalen welke kenmerken relevant zijn om data in verschillende categorieën te sorteren.
Met andere woorden, we kunnen deep learning zien als een verbetering van machine learning omdat het met alle soorten data kan werken en de menselijke afhankelijkheid vermindert.
Voordelen en beperkingen van machine learning
Machine learning is een krachtig hulpmiddel om problemen op te lossen. De tak heeft echter ook zijn beperkingen. Hieronder staan de belangrijkste voordelen en huidige uitdagingen van machine learning.
Voordelen
- Dataomvang: Machine learning kan problemen aan waarbij enorme hoeveelheden data verwerkt moeten worden. ML-modellen kunnen zelf patronen ontdekken en voorspellingen doen, en inzichten bieden die traditionele programmering niet kan bieden.
- Flexibiliteit: Machine learning-modellen kunnen zich aanpassen aan nieuwe data en hun nauwkeurigheid in de loop van de tijd voortdurend verbeteren. Dit is van onschatbare waarde als het gaat om dynamische data die voortdurend veranderen, zoals filmaanbevelingen, die gebaseerd zijn op de laatste film die je hebt gekeken of op wat je op dat moment kijkt.
- Automatisering: Dit geldt voor complexe taken en grote hoeveelheden data die menselijke experts nooit zouden kunnen verwerken of voltooien, zoals het doornemen van opnames van gesprekken met klanten. In andere gevallen kan machine learning taken uitvoeren die mensen wel kunnen uitvoeren, zoals het vinden van een antwoord op een vraag, maar nooit op die schaal of zo efficiënt als een online zoekmachine.
Beperkingen
- Overfitting en generalisatieproblemen: Wanneer een model voor machine learning te veel gewend raakt aan de trainingsdata, kan het niet generaliseren naar voorbeelden die het nog niet eerder is tegengekomen (dit wordt “overfitting” genoemd). Dit betekent dat het model zo specifiek is voor de oorspronkelijke data, dat het mogelijk niet correct classificeert of voorspellingen doet op basis van nieuwe, ongeziene data. Dit resulteert in foutieve uitkomsten en minder-dan-optimale beslissingen.
- Verklaarbaarheid: Sommige modellen voor machine learning werken als een “black box” en zelfs experts zijn niet in staat om uit te leggen waarom ze tot een bepaalde beslissing of voorspelling zijn gekomen. Dit gebrek aan uitlegbaarheid en transparantie kan problematisch zijn in gevoelige domeinen zoals financiën of gezondheid, en roept vragen op over verantwoording. Stel je bijvoorbeeld eens voor dat we niet konden uitleggen waarom een banklening was geweigerd of waarom een bepaalde behandeling was aanbevolen.
- Algoritmische bias: Modellen voor machine learning trainen op data die door mensen zijn gemaakt. Als gevolg daarvan kunnen datasets bevooroordeelde, niet-representatieve informatie bevatten. Dit leidt tot algoritmische bias: systematische en herhaalbare fouten in een ML-model die leiden tot oneerlijke uitkomsten, zoals het bevoorrechten van de ene groep sollicitanten boven de andere.
Andere interessante artikelen
Op zoek naar meer informatie over ChatGPT, AI tools, retoriek en onderzoeksbias? Bekijk onze artikelen met uitleg en voorbeelden!
AI tools
Onderzoeksbias
Veelgestelde vragen over machine learning
Citeer dit Scribbr-artikel
Als je naar deze bron wilt verwijzen, kun je de bronvermelding kopiëren of op “Citeer dit Scribbr-artikel” klikken om de bronvermelding automatisch toe te voegen aan onze gratis Bronnengenerator.
Scharwächter, V. (2023, 05 juli). Wat is Machine Learning? | Betekenis & Voorbeelden. Scribbr. Geraadpleegd op 23 juni 2026, van https://www.scribbr.nl/ai-tools-gebruiken/wat-is-machine-learning/
