Wat is reinforcement learning? | Betekenis & Voorbeelden
Reinforcement learning (RL) is een vorm van machine learning waarbij computers leren om de beste beslissingen te nemen door interactie met hun omgeving. In plaats van duidelijke instructies te krijgen, leert de computer door te proberen en te ervaren (door de omgeving te verkennen en beloningen of straffen te ontvangen voor zijn acties).
Dit is een van de drie basisbenaderingen voor machine learning, naast supervised en unsupervised learning. Reinforcement learning wordt veel toegepast in de echte wereld, bijvoorbeeld in robotica, spelletjes en het diagnosticeren van zeldzame ziekten.
Wat is reinforcement learning?
Reinforcement learning (RL) is een manier waarop computers zelfstandig kunnen leren door beslissingen te nemen en te leren van de resultaten. Ze proberen verschillende acties en leren wat het beste werkt in een bepaalde situatie om zo hun prestaties te verbeteren.
De computer krijgt feedback in de vorm van beloningen (positief) of straffen (negatief) op basis van de acties die hij onderneemt. Hierdoor leert hij geleidelijk hoe hij een taak het beste kan uitvoeren. Met RL draait het erom het optimale gedrag te leren in een bepaalde situatie om de grootste beloning te krijgen.
Reinforcement learning is geschikt om problemen aan te pakken waarbij een reeks beslissingen elkaar allemaal beïnvloeden.
Het trainen van een computer om bijvoorbeeld backgammon te winnen, omvat een hele reeks goede beslissingen (niet slechts één). In zulke spellen zijn er verschillende mogelijke acties en scenario’s en er is veel onzekerheid over het effect van kortetermijnacties op de lange termijn. RL kan ook helpen bij het oplossen van complexe controleproblemen, zoals wandelende robots of zelfrijdende auto’s.
In tegenstelling tot de andere twee leermethoden, die werken op basis van een bestaande dataset, verzamelt reinforcement learning gegevens terwijl de computer met zijn omgeving interageert. Hierdoor kan software de optimale oplossing vinden door te verkennen, met de omgeving te communiceren en uiteindelijk te leren van de omgeving.
Bij RLHF wordt een al vooraf getraind taalmodel, zoals een chatbot, beoordeeld door echte mensen, die de gegenereerde antwoorden een score geven. Door menselijke feedback toe te voegen, kunnen experts het model sturen en bepaalde resultaten meer laten voorkomen dan anderen – bijvoorbeeld antwoorden die natuurlijker klinken of nuttiger zijn.
De elementen van reinforcement learning
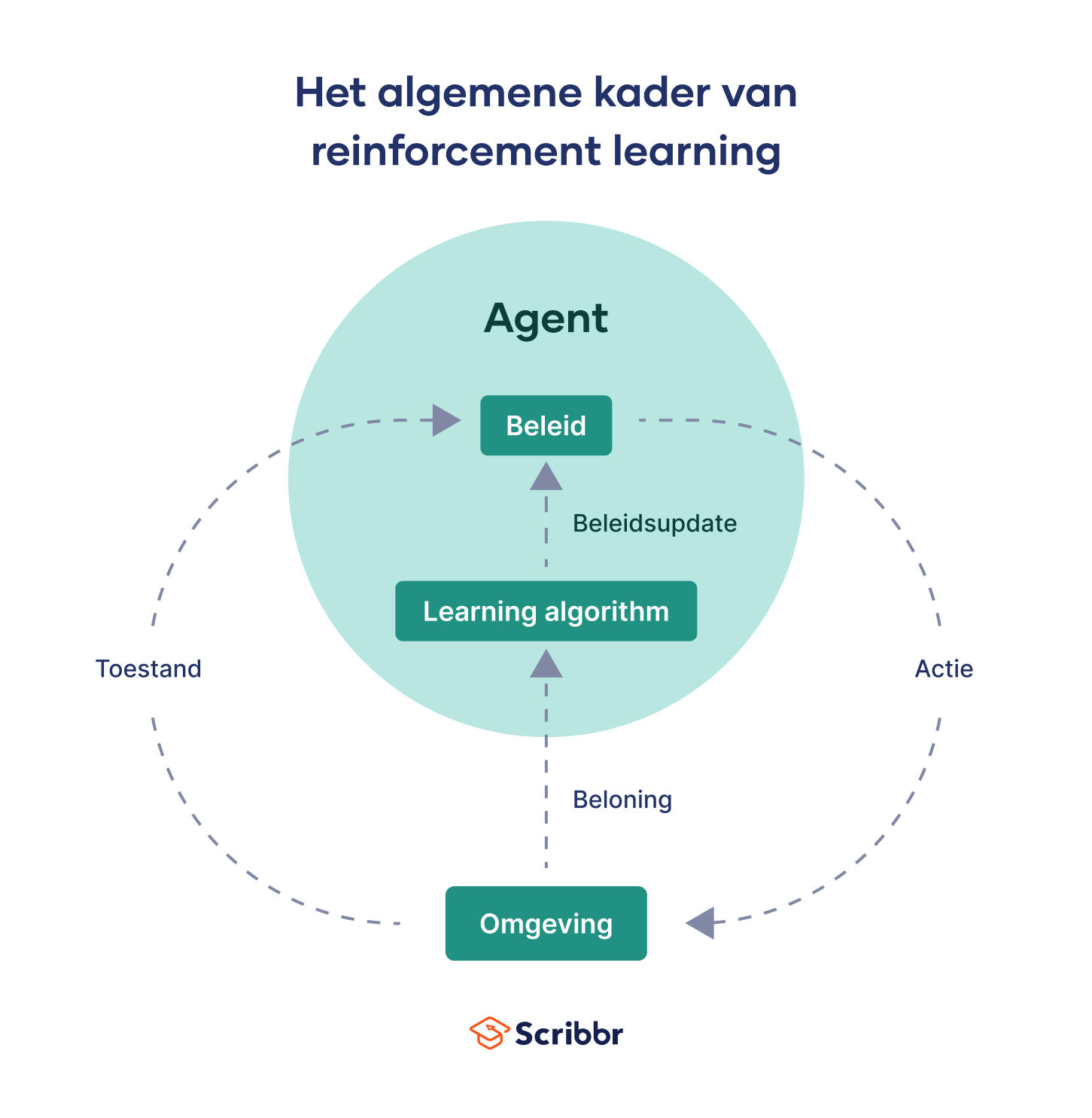
Reinforcement learning omvat de volgende belangrijke elementen:
- Omgeving: Dit is het kader waarin een computerprogramma opereert. Het kan virtueel zijn, zoals een videospel, of fysiek, zoals een huis.
- Agent: Dit verwijst naar de leerling of beslisser (bijvoorbeeld het computerprogramma) binnen de omgeving. De agent verkent de omgeving en interacteert ermee.
- Actie: Dit zijn stappen die de agent binnen de omgeving onderneemt.
- Toestand: Dit is de huidige situatie van de agent op een bepaald moment. Elke actie leidt tot een verandering van toestand.
- Beloning: Dit kan positief zijn, om goed gedrag te versterken, of negatief, om ongewenst gedrag te ontmoedigen. Het is de feedback die de agent van de omgeving ontvangt voor een bepaalde actie.
- Beleid: Het beleid is hoe een agent zich op een bepaald moment gedraagt. Het helpt de agent bij het kiezen van de volgende actie, gebaseerd op de huidige situatie of toestand, en definieert de relatie tussen verschillende situaties en acties.
- Waarde: Dit geeft aan hoe gunstig een bepaalde toestand is op de lange termijn en helpt de agent om de wenselijkheid van verschillende toestanden of acties te beoordelen. De waarde wordt bepaald op basis van de potentiële beloningen of straffen die verbonden zijn aan een toestand of actie. Door de waarde van verschillende toestanden of acties te schatten, kan de agent een beleid definiëren dat acties en toestanden met hogere verwachte langetermijnvoordelen voorrang geeft.
Algoritmes spelen een essentiële rol in het RL-proces en worden gebruikt in verschillende stappen. Ze helpen bij het ontwerpen van het leeralgoritme van de agent, dat wil zeggen hoe deze beslissingen neemt, zijn beleid bijwerkt en leert van de ontvangen feedback.
- Omgeving: De omgeving in het Pac-Man-spel is alles wat de spelwereld omvat, inclusief het doolhof zelf, de vijanden (spoken), de puntjes, de bonus-items (vruchten), de krachtpellets en alle andere elementen die van invloed zijn op het spelverloop.
- Agent: In het Pac-Man-spel verwijst de term “agent” naar het personage waar de speler controle over heeft, namelijk de Pac-Man zelf. Het doel van de agent (Pac-Man) is om alle puntjes in het doolhof op te eten, de spoken te vermijden en zijn score te maximaliseren.
- Actie: De acties zijn de bewegingen die de agent kan uitvoeren in het Pac-Man-spel, zoals vooruit bewegen, linksaf slaan, rechtsaf slaan, etc.
- Toestand: De toestand vertegenwoordigt de huidige situatie van het Pac-Man-spel op een bepaald moment. De toestand bevat belangrijke informatie zoals de exacte positie van Pac-Man, de locatie van de spoken, de verzamelde punten en andere relevante details die op dat moment van belang zijn in het spel.
- Beloning: De beloningen zijn de feedback die de agent ontvangt voor de acties die hij onderneemt in het spel. Bijvoorbeeld, het eten van een punt kan een positieve beloning zijn, terwijl het botsen met een spook een negatieve beloning kan zijn.
- Beleid: In het Pac-Man-spel kan een regel of strategie zijn: “Als een spook dichtbij is, beweeg dan in de tegenovergestelde richting” om te voorkomen dat Pac-Man wordt gepakt door het spook. Een andere regel kan zijn: “Als een punt dichtbij is, beweeg dan er naartoe” om zo veel mogelijk punten te verzamelen.
- Waarde: Waarde geeft aan hoe gunstig een toestand is om het doel van het spel te bereiken. Een toestand waarin Pac-Man is ingesloten door de spoken heeft een lage waarde omdat het risico op gevangen worden groot is en er weinig kans is om punten te scoren. Een toestand waarin Pac-Man een krachtpellet eet en de spoken kan achtervolgen heeft daarentegen een hoge waarde, omdat dit Pac-Man in staat stelt om veel punten te verzamelen, de spoken uit te schakelen en zo de score te verhogen.

Hoe werkt reinforcement learning?
In reinforcement learning draait alles om het versterken van goede acties door middel van beloningen. Ingenieurs bedenken manieren om gewenst gedrag te belonen en ongewenst gedrag te ontmoedigen.
Ze gebruiken slimme technieken om te voorkomen dat kortetermijnbeloningen de agent vertragen en daarmee het bereiken van het uiteindelijke doel. Hierbij is het belangrijk om beloningen te definiëren die passen bij het langetermijndoel, zodat de agent leert om acties te kiezen die leiden tot het gewenste resultaat.
Reinforcement learning is eigenlijk een herhalende cyclus van ontdekken, feedback krijgen en verbeteren. Het proces werkt als volgt:
- Definieer het probleem
- Zet de omgeving op
- Bedenk een agent
- Begin met leren
- Ontvang feedback
- Verfijn
- Toepassen
Als voorbeeld laten we de RL-werkwijze zien op een robotstofzuiger:
- Definieer het probleem: We willen een robotstofzuiger trainen om zelfstandig een kamer efficiënt schoon te maken.
- Zet de omgeving op: We creëren een gesimuleerde omgeving die de kamer voorstelt waarin de robotstofzuiger zal werken, inclusief de indeling, meubels en alles wat zich in de kamer bevindt.
- Bedenk een agent: De robotstofzuiger is de leerling of agent. We voorzien de robot van de juiste technologie om de omgeving waar te nemen en zich te verplaatsen.
- Begin met leren: In het begin verkent de robotstofzuiger de kamer willekeurig, botst tegen meubels of obstakels aan en reinigt delen van de kamer zonder een specifieke strategie. De robot verzamelt informatie over de kamer en hoe zijn acties van invloed zijn op de schoonmaak ervan.
- Ontvang feedback: Na elke actie ontvangt de stofzuiger een positieve of negatieve beloning, waardoor zijn besluitvormingsproces in de loop van de tijd wordt gevormd. Bijvoorbeeld, als de robot succesvol botsingen met meubels vermijdt, krijgt hij een positieve beloning, terwijl een negatieve beloning wordt gegeven wanneer de stofzuiger doelloos beweegt of dezelfde plek herhaaldelijk schoonmaakt.
- Werk het beleid bij: Op basis van de ontvangen beloningen werkt de robotstofzuiger zijn besluitvormingsstrategie of beleid bij om zich meer te richten op acties die leiden tot positieve beloningen in plaats van negatieve.
- Verfijn: De robotstofzuiger blijft de kamer verkennen, acties ondernemen, feedback ontvangen en het beleid bijwerken. Met elke herhaling verbetert de robot zijn kennis over welke acties de schoonmaakefficiëntie maximaliseren en obstakels vermijden. Gaandeweg past de stofzuiger zich ook aan verschillende kamerindelingen aan.
- Toepassen: Zodra de stofzuiger een effectief beleid heeft geleerd, past hij dit toe om de kamer autonoom schoon te maken.
Reinforcement learning vs andere methoden
Reinforcement learning is een aparte benadering van machine learning die aanzienlijk verschilt van de andere twee belangrijkste benaderingen.
Supervised learning vs reinforcement learning
Bij supervised learning heeft een menselijke expert de dataset gelabeld, wat betekent dat het juiste antwoord wordt gegeven. Bijvoorbeeld, de dataset kan bestaan uit afbeeldingen van verschillende auto’s die een expert heeft gelabeld met de fabrikant van elke auto.
De leeragent heeft een begeleider die als leraar de juiste antwoorden geeft. Door training met deze gelabelde dataset ontvangt de agent feedback en leert deze hoe nieuwe, ongeziene data (bijvoorbeeld foto’s van auto’s) in de toekomst geclassificeerd kan worden.
Bij reinforcement learning maakt data geen deel uit van de input, maar wordt deze verkregen door interactie met de omgeving. In plaats van het systeem vooraf te vertellen welke acties optimaal zijn om een taak uit te voeren, maakt reinforcement learning gebruik van beloningen en straffen. Dus de agent krijgt feedback zodra deze een actie onderneemt.
Unsupervised learning vs. reinforcement learning
Unsupervised learning houdt zich bezig met ongelabelde data en er is geen feedback bij betrokken. Het doel is om de dataset te verkennen en overeenkomsten, verschillen of groepen in de invoerdata (input data) te vinden zonder voorafgaande kennis van de verwachte output.
Aan de andere kant, bij reinforcement learning gaat het om het verkennen van de omgeving en niet de dataset. Daarnaast is het einddoel anders: de agent probeert de best mogelijke actie te ondernemen in een bepaalde situatie om de totale beloning te maximaliseren. Zonder trainingdataset wordt het RL-probleem opgelost door de acties van de agent zelf met input van de omgeving.
| Supervised learning | Unsupervised learning | Reinforcement learning | |
| Invoerdata | Gelabeld: het “juiste antwoord” is opgenomen | Niet gelabeld: er is geen “juist antwoord” gespecificeerd | Gegevens maken geen deel uit van de invoer, ze worden verzameld door middel van trial-and-error. |
| Probleem dat moet worden opgelost | Wordt gebruikt om een voorspelling te maken (bijvoorbeeld de toekomstige waarde van een aandeel) of een classificatie (bijvoorbeeld het correct identificeren van spam-e-mails) | Wordt gebruikt om patronen, structuren of relaties in grote datasets te ontdekken (bijvoorbeeld mensen die product A bestellen, bestellen ook product B) | Wordt gebruikt om beloningsgerelateerde problemen op te lossen (bijvoorbeeld in een videospel) |
| Oplossing | Invoerdata wordt omgezet in de juiste uitvoerdata (van input naar output) | Vindt overeenkomsten en verschillen in de invoerdata om deze vervolgens te classificeren | Vindt welke toestanden en acties het totale cumulatieve beloningsniveau van de agent maximaliseren |
| Algemene taken | Classificatie, regressie | Clustering, dimensionaliteit vermindering, leren d.m.v. associatie | Verkenning en exploitatie |
| Voorbeelden | Beeldherkenning, voorspelling van de aandelenmarkt | Klantsegmentatie, productaanbeveling | Spel spelen, robotstofzuigers |
| Begeleiding | Ja | Nee | Nee |
| Feedback | Ja. De juiste set acties wordt geleverd | Nee | Ja, door middel van beloningen en straffen (positieve en negatieve beloningen) |
Voordelen en beperkingen van reinforcement learning
Reinforcement learning heeft verschillende voordelen als trainingsmethode
- Complexiteit: RL kan worden gebruikt om zeer complexe problemen op te lossen die gepaard gaan met hoge onzekerheid, waarbij reinforcement learning in veel gevallen de prestaties van mensen overtreft. Het AI-programma genaamd AlphaGo was het eerste computerprogramma dat een menselijke wereldkampioen versloeg in het oude Chinese spel Go en wordt beschouwd als de sterkste Go-speler in de geschiedenis.
- Aanpassingsvermogen: RL kan omgaan met omgevingen waarin de uitkomsten van acties niet altijd voorspelbaar zijn. Dit is handig voor toepassingen in de echte wereld waar de omgeving in de loop van de tijd kan veranderen of onzeker kan zijn.
- Onafhankelijke besluitvorming: Met reinforcement learning kunnen intelligente systemen zelfstandig beslissingen nemen zonder menselijke interventie. Ze kunnen leren van hun ervaringen en hun gedrag aanpassen om specifieke doelen te bereiken.
Echter, reinforcement learning gaat ook gepaard met bepaalde uitdagingen en beperkingen:
- Grote data-eisen. Reinforcement learning heeft veel data nodig om effectief te leren, zelfs meer dan supervised learning. Het vereist veel interacties om goede resultaten te behalen. Het verzamelen van voldoende trainingsgegevens kan tijdrovend en kostbaar zijn. In sommige gevallen kan het testen van RL-systemen in de echte wereld gevaarlijk zijn (bijvoorbeeld in het geval van autonome voertuigen).
- Complexiteit van de echte wereld. In het echte leven kan feedback vertraagd zijn. Het kan maanden of jaren duren voordat duidelijk wordt of een investeringsbeslissing succesvol was of niet. Bovendien veranderen de omstandigheden waarin een agent zijn besluitvormingsproces herhaalt vaak in de echte wereld. Dit staat ver af van de stabiele omgevingen in games.
- Moeilijkheid bij het ontwerpen van effectieve beloningen. Datawetenschappers kunnen worstelen om wiskundig een beloning uit te drukken, zodat deze weerspiegelt hoe een bepaalde actie de agent dichter bij het uiteindelijke doel brengt. Bijvoorbeeld, als we een auto willen leren om een bocht te maken zonder de stoeprand te raken, moet de beloningfunctie factoren zoals de afstand tussen de auto en de stoeprand en het begin van de stuuractie meenemen. Met andere woorden, hoe dichter de auto bij de stoeprand komt, hoe lager de beloning moet zijn om de kans op botsingen te minimaliseren.
Andere interessante artikelen
Op zoek naar meer informatie over ChatGPT, AI tools, retoriek en onderzoeksbias? Bekijk onze artikelen met uitleg en voorbeelden!
Veelgestelde vragen
Bronnen voor dit artikel
We raden studenten sterk aan om bronnen te gebruiken. Je kunt verwijzen naar ons artikel (APA-stijl) of je verdiepen in onderstaande bronnen.
Citeer dit Scribbr-artikelHussaarts, Z. (2023, 01 augustus). Wat is reinforcement learning? | Betekenis & Voorbeelden. Scribbr. Geraadpleegd op 18 juli 2026, van https://www.scribbr.nl/ai-tools-gebruiken/reinforcement-learning-uitgelegd/
Li, Y. (2018). Deep reinforcement learning. arXiv (Cornell University). https://doi.org/10.48550/arxiv.1810.06339
Naeem, M., Rizvi, S. S., & Coronato, A. (2020). A Gentle Introduction to Reinforcement Learning and its Application in Different Fields. IEEE Access, 8, 209320–209344. https://doi.org/10.1109/access.2020.3038605
