Gepubliceerd op
16 september 2021
door
Pritha Bhandari.
Bijgewerkt op
18 december 2023.
Externe validiteit is de mate waarin je de resultaten van je onderzoek kunt generaliseren naar andere omstandigheden en groepen. In andere woorden: zijn je resultaten te generaliseren naar een bredere context?
Het doel van wetenschappelijk onderzoek is om generaliseerbare kennis over de echte wereld te verzamelen. In kwalitatieve onderzoeken wordt externe validiteit “overdraagbaarheid” genoemd.
Gepubliceerd op
3 september 2021
door
Pritha Bhandari.
Bijgewerkt op
22 augustus 2022.
Een ratioschaal is een kwantitatieve schaal met een betekenisvol of absoluut nulpunt en gelijke intervallen tussen aangrenzende punten. Het betekenisvolle nulpunt betekent dat bij de waarde “0” de variabele daadwerkelijk afwezig is.
Voorbeelden van ratioschalen zijn lengte, oppervlakte en bevolkingsaantallen.
Gepubliceerd op
1 september 2021
door
Pritha Bhandari.
Bijgewerkt op
17 oktober 2022.
Bij een experimenteel of correlationeel onderzoek krijg je vaak te maken met externe variabelen (extraneous variables). Dit zijn variabelen die je niet specifiek onderzoekt (waarin je niet geïnteresseerd bent), maar die wel de resultaten van je onderzoek kunnen beïnvloeden.
Als je niet controleert voor externe variabelen, kunnen deze variabelen alternatieve verklaringen vormen voor je resultaten, waardoor je niet in staat bent om met zekerheid conclusies te trekken over de relaties tussen de variabelen waarin je wél geïnteresseerd bent.
Onderzoeksvraag
Externe variabelen
Is er een verband tussen geheugencapaciteit en leesvaardigheid?
Tijdstip waarop de test wordt afgenomen
Mate van faalangst
Stressniveau
Heeft slaapgebrek invloed op de rijvaardigheid?
Kwaliteit van de weg
Aantal jaren rijervaring
Omgevingsgeluid
Draagt blootstelling aan licht bij aan de verbetering van het leervermogen van muizen?
Gepubliceerd op
23 augustus 2021
door
Pritha Bhandari.
Bijgewerkt op
23 januari 2023.
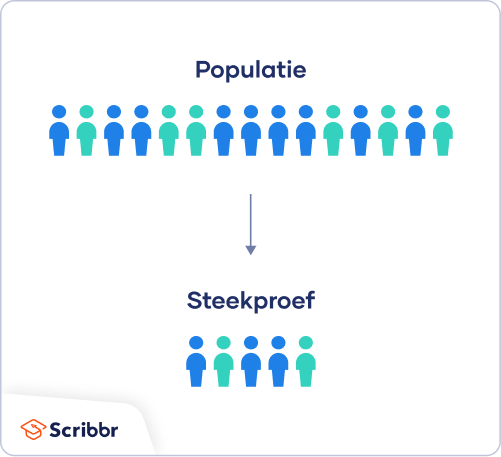
Een populatie is de gehele groep waarover je uitspraken wilt doen, bijvoorbeeld “verpleegkundigen tussen de 25 en 34 jaar oud”.
Een steekproef is de specifieke subgroep die je daadwerkelijk onderzoekt en waarvoor je data verzamelt. De steekproef is altijd kleiner dan de populatie zelf, omdat je maar een deel van de populatie onderzoekt.
Bij wetenschappelijk onderzoek bestaat een populatie niet altijd uit mensen. Een populatie kan namelijk ook bestaan uit objecten, gebeurtenissen, organisaties, landen, diersoorten, organismen, et cetera.
Populatie vs steekproef
Populatie
Steekproef
Vacatures voor banen in de IT in Nederland
Top 50 zoekresultaten voor vacatures voor IT-banen in Nederlands op 1 mei 2021
Liedjes van het Eurovisie Songfestival
Winnende, Engelstalige liedjes van het Eurovisie Songfestival
Bachelorstudenten psychologie in Nederland
300 bachelorstudenten Psychologie van drie Nederlandse universiteiten
Alle landen ter wereld
Landen die data hebben gepubliceerd over hun geboortecijfers en sterftecijfers sinds 2000
Gepubliceerd op
13 augustus 2021
door
Pritha Bhandari.
Bijgewerkt op
16 juni 2023.
Controlevariabelen zijn alle variabelen die constant worden gehouden in een onderzoek. Het zijn variabelen waarin je niet geïnteresseerd bent, maar waarvoor wordt gecontroleerd omdat ze de uitkomsten kunnen beïnvloeden.
Variabelen kunnen direct worden gecontroleerd door ze constant te houden tijdens een onderzoek (bijvoorbeeld door de kamertemperatuur in een experiment te reguleren). Ze kunnen ook indirect worden gecontroleerd door randomisatie of door statistisch te controleren (bijvoorbeeld door rekening te houden met participanteigenschappen, zoals de leeftijd, bij statistische toetsen).
Voorbeelden van controlevariabelen
Onderzoeksvraag
Controlevariabelen
Heeft de kwaliteit van de potgrond invloed op de plantgroei?
Temperatuur
Hoeveelheid licht
Hoeveelheid water
Kan cafeïne het geheugen verbeteren?
Leeftijd van de participant
Omgevingsgeluid
Soort geheugentest
Nemen mensen met een angst voor spinnen afbeeldingen van spinnen eerder waar dan mensen zonder spinnenangst?
Gepubliceerd op
13 augustus 2021
door
Pritha Bhandari.
Bijgewerkt op
10 mei 2022.
Een mediërende variabele (ook mediatievariabele of mediatorvariabele genoemd) verklaart op welke manier twee variabelen gerelateerd zijn, terwijl een modererende variabele (ook moderatievariabele of moderatorvariabele genoemd) de sterkte en richting van die relatie beïnvloedt.
Door deze extra variabelen op te nemen in je onderzoek, kijk je verder dan de simpele relatie tussen twee variabelen, zodat je een vollediger beeld krijgt van de werkelijke situatie. Het is vooral van belang om deze variabelen te bestuderen als je complexe correlaties of causale verbanden onderzoekt.
Gepubliceerd op
10 augustus 2021
door
Pritha Bhandari.
Bijgewerkt op
1 maart 2023.
Bij experimenteel onderzoek wordt vaak randomisatie (random assignment) gebruikt om participanten in je steekproef willekeurig over verschillende experimentele groepen en controlegroepen te verdelen.
Als je deze methode gebruikt, heeft ieder lid van de steekproef een even grote kans om in een controlegroep of experimentele groep te worden geplaatst. In dat geval is er sprake van een volledig gerandomiseerd design (completely randomized design).
Willekeurige toewijzing van participanten is een belangrijk aspect van een experimenteel design. Door participanten op die manier te verdelen, zorg je ervoor dat alle groepen aan het begin van het onderzoek vergelijkbaar zijn en dat alle verschillen tussen groepen het gevolg zijn van willekeurige factoren.
Gepubliceerd op
6 augustus 2021
door
Pritha Bhandari.
Bijgewerkt op
10 mei 2022.
Intervaldata wordt gemeten op een numerieke schaal met gelijke afstanden tussen de aangrenzende waarden. Deze afstanden worden “intervallen” genoemd. Doordat de afstanden tussen de verschillende datapunten gelijk zijn, kun je bepaalde berekeningen uitvoeren.
Het verschil tussen interval- en ratiodata is dat een intervalschaal geen natuurlijk nulpunt kent. Bij een schaal op intervalniveau is het nulpunt willekeurig gekozen, en betekent het niet dat de variabele compleet afwezig is.
Zo is temperatuur (in graden Celsius) een intervalvariabele. Het nulpunt is willekeurig gekozen en 0 graden betekent het niet dat er helemaal geen temperatuur aanwezig is (of dat dit de koudst mogelijke temperatuur is). Tijd is daarentegen een ratiovariabele, omdat 0 minuten daadwerkelijk een betekenisvol nulpunt is (en het laagst mogelijke aantal).
Gepubliceerd op
3 augustus 2021
door
Pritha Bhandari.
Bijgewerkt op
10 mei 2022.
Een likertschaal wordt ook wel een waarderingsschaal of gedwongen-keuzeschaal genoemd (zeker als er geen neutrale antwoordoptie is). Likertschalen worden gebruikt om meningen, houdingen of gedrag te onderzoeken. Ze worden meestal ingezet bij enquêteonderzoek, omdat dit type schaal het mogelijk maakt om persoonlijkheidskenmerken of waarnemingen eenvoudig te operationaliseren.
Om data te kunnen verzamelen, geef je de participanten bijvoorbeeld een enquête met likert-vragen of -stellingen en meestal een 5- of 7-puntsschaal met antwoordopties. Iedere antwoordmogelijkheid krijgt een nummer toegekend, zodat je de data daarna kwantitatief kunt analyseren.
Gepubliceerd op
23 juli 2021
door
Pritha Bhandari.
Bijgewerkt op
10 mei 2022.
In het dataverzamelingsproces verzamel je op basis van je onderzoeksopzet data voor je scriptie of onderzoek om zo je onderzoeksvraag te beantwoorden. Het is van belang dat je de data op een gestructureerde, valide en betrouwbare manier verzamelt.
De methoden en doelen kunnen per onderzoeksgebied verschillen, maar het stappenplan voor de dataverzameling is meestal hetzelfde. Voordat je aan de dataverzameling begint, moet je nadenken over:
Het doel van je onderzoek;
Het type data;
De methoden en procedures die je gebruikt om de data te verzamelen, op te slaan en te verwerken.
Je kunt de volgende vier stappen gebruiken om data van hoge kwaliteit te verzamelen.